Scrapy爬虫框架(2)--内置py文件
Scrapy概念图
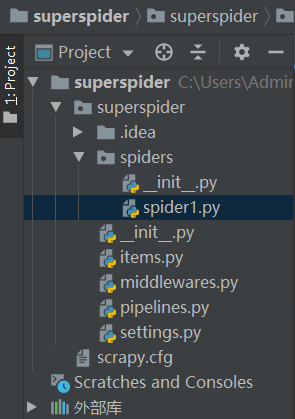
- 这里有很多py文件,分别与Scrapy的各个模块对应
- superspider是一个爬虫项目
- spider1.py则是一个创建好的爬虫文件,爬取资源返回url和数据
- items.py可以在里面预先定义要爬取的字段,并导入到其他模块,在爬虫解析页面时仅能使用已定义的这些字段
- middlewares.py里面可以编写有关爬虫中间件和下载中间件的内容
- pipelines.py则是提取数据的一个部分,编写有关数据处理的代码,接受由spider传过来的数据
- settings.py里面是一些爬虫的设置,也可以导入自己的设置并导入到其他模块
- superspider是一个爬虫项目
大致内容
- spider.py
- items.py
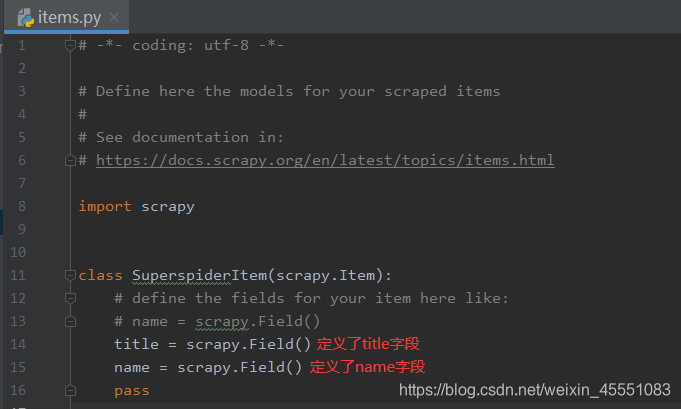
settings内容
-
原生设置
BOT_NAME = 'superspider' SPIDER_MODULES = ['superspider.spiders'] NEWSPIDER_MODULE = 'superspider.spiders'BOT_NAME: 项目名称SPIDER_MODULES:爬虫位置NEWSPIDER_MODULE: 新建爬虫的位置
Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'superspider (+http://www.yourdomain.com)'- 可在这里设置User-Agent
ROBOTSTXT_OBEY = TrueROBOTSTXT_OBEY:是否遵守robots协议默认为遵守,改 False 可不遵守
Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 32CONCURRENT_REQUESTS:Scrapy downloader 并发请求(concurrent requests)的最大值,默认: 16
Configure a delay for requests for the same website (default: 0) DOWNLOAD_DELAY = 3 The download delay setting will honor only one of: CONCURRENT_REQUESTS_PER_DOMAIN = 16 CONCURRENT_REQUESTS_PER_IP = 16DOWNLOAD_DELAY:页面请求延迟时间,默认为0(秒)可缓解对方服务器压力- 下载延迟设置,只能有一个生效
CONCURRENT_REQUESTS_PER_DOMAIN对单个网站并发请求最大值CONCURRENT_REQUESTS_PER_IP对单个IP并发请求最大值- 设置为0则下载延迟生效
Disable cookies (enabled by default) COOKIES_ENABLED = False Disable Telnet Console (enabled by default) TELNETCONSOLE_ENABLED = False- cookies和控制台,默认禁用
COOKIES_ENABLED
# Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #}- 默认的请求头,User-agent和cookies不需要在这里设置
# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = { # 'superspider.pipelines.SuperspiderPipeline': 300, #}- item pipelines的配置
'superspider.pipelines.SuperspiderPipeline' = 300300指的是优先级
-
额外经常用到的配置
默认: True,是否启用logging。
LOG_ENABLED=True
默认: 'utf-8',logging使用的编码。
LOG_ENCODING='utf-8'
它是利用它的日志信息可以被格式化的字符串。默认值:'%(asctime)s [%(name)s] %(levelname)s: %(message)s'
LOG_FORMAT='%(asctime)s [%(name)s] %(levelname)s: %(message)s'
它是利用它的日期/时间可以格式化字符串。默认值: '%Y-%m-%d %H:%M:%S'
LOG_DATEFORMAT='%Y-%m-%d %H:%M:%S'
日志文件名
LOG_FILE = "dg.log"
LOG_LEVEL = 'WARNING'
- 日志文件级别,默认值:“DEBUG”,log的最低级别。可选的级别有: CRITICAL、 ERROR、WARNING、INFO、DEBUG 。
logging模块的简单使用
- settings中设置LOG_LEVEL = "WARNING"
- settings中设置LOG_FILE = "./a.log"就不会在终端显示日志内容
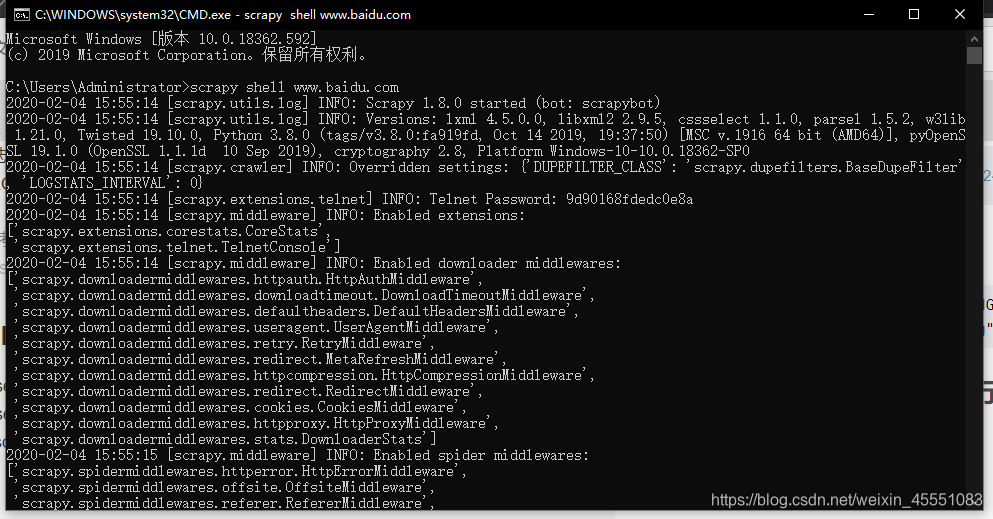
scrapy shell可以在终端进行调试
[博客内容只是本人学习过程记录的笔记,不保证质量.本人不保证技术的实用性,一切文章仅供参考,如有谬错,请留言.]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号