
基于深度单分类和视觉注意机制的色情图像识别模型

现有的方法通常将色情图像的识别作为一种二分类或多类分类任务,通过提取多种特征来实现。 但是,这些方法忽略了负样本中固有类型的问题,忽略了分类任务中不确定性的影响,导致负数据集不足,对不在训练集中的样本识别错误。 为了解决这一难题,本文提出了一种名为Deep One-Class with Attention for porn (DOCAPorn)的方法,该方法通过基于神经网络的一类分类模型对色情图像进行识别,并引入视觉注意机制来提高识别性能。 另外,由于现有的基于深度卷积神经网络(cnn)的方法需要一个固定尺寸(如224 x224)的输入图像,因此现有的方法没有考虑图像缩放引起的几何失真,降低了色情图像的识别精度。 为了解决这一问题,本文提出了规模约束池(Scale Constraint Pooling, SCP),将不同维度的输入转换为相同维度的输出。 此外,现有的色情图像识别方法均忽略了领域的对抗性攻击。 为了解决这一问题,本文提出了压缩重构预处理(Preprocessing for compression and reconstruction,简称prer)方法,该方法通过对图像进行压缩来减少图像的微小扰动,然后重构出完整的图像进行识别。 通过使用自定义数据集进行对比实验,验证了该方法的有效性。 实验结果表明,该算法在数据集上的准确率为98.419%。 该方法在NPDI数据集上的识别准确率为95.632%。 实验结果验证了该方法的有效性 。
在现代社会,互联网已经成为全球信息中心。 全世界互联网用户的数量每天都在增加。 根据“We Are Social and Hootsuite”在2019年[1]发布的最新全球数字套件报告,全球45%的人口现在是互联网用户。 各种信息工具的快速发展和推广,使得互联网上的信息共享和资源的网络传播更加活跃。 人们可以随时轻松地在互联网上发布或分享信息和资源。 另一方面,滥用互联网传播色情信息也被广泛报道[2][7]。 网络色情日益影响人们特别是青少年的正常生活,引发许多社会问题和道德问题[7][9]。 此外,不断有研究报告称,网络色情的增长与性犯罪的上升有关,如性虐待、家庭暴力和儿童色情[10]。 因此,识别网络色情对网络资源和网络文化的健康发展具有重要意义。 设计一种实用、有效的色情图像识别方法势在必行。 网络色情的发现和消除一直是网络信息安全领域关注的话题,[11][15]。 色情图像是网络色情的重要组成部分,随着计算机视觉技术的发展,基于内容的色情图像识别得到了广泛的研究。
在过去的几十年里,许多研究试图解决这个问题。 然而,现有的色情图像检测方法仍然存在许多挑战。
首先,传统的二元分类的目标任务是分类的类别A和类别B。例如,对于猫狗分类任务,如果猫形象被认为是一类,狗的形象被认为是类别B。在这种情况下,功能空间的A类和B类都是明确的。 色情图像识别任务通常被认为是一种二值分类任务。 如果将色情图片归为A类,则将正常图片归为b类。 在负类中,样本类型之间不可能存在相关性。 例如,在正常的图像中,猫和车是完全不同的类型。 在这种情况下,由于B类的特征空间不明确,B类本质上等同于非A类。由于非A类包含无限种,我们将这种情况定义为“负样本中无限种”。 因此,色情图像的识别被认为是一种特殊的二值或三值分类任务。 最直接的解决方法是在阴性样本中包含尽可能多的物种。 这意味着识别色情图像的训练集需要不同类别的图像。 然而,在现实的互联网环境中,正常图像的类别异常的多样化,使得构建训练集变得困难。 另外,由于色情图像识别中存在无限种的负样本,导致特征空间不清晰。 一些不在负样本训练集中的正常图像,如脸部特写,会被分类器误判。 这是因为负样本的特征空间不清晰,导致分类边界模糊。 由于不能指定负样本的特征空间,降低了分类的准确性。
其次,当色情图像被添加了微小的数据扰动,人类无法观察到细微的扰动,这些图像仍然是色情的。 但现有的主流识别方法将无法识别它们。 例如,一个简单的例子是,在添加了不易察觉的噪声[17]后,神经网络将熊猫图片分类为长臂猿。
第三,现有的识别方法需要固定尺寸(如224 224)的输入图像。 这一要求改变了图像的原始比例,通过神经网络的卷积层导致一些信息的放大或减少。 这会导致色情图像的几何失真。 图像信息丢失或失真会影响识别精度。 另外,缩放造成的几何失真会在一定程度上改变色情图像的关键信息。 例如,一个胖男人的胸部被缩放,在视觉上变得与女性乳房相似。 信息的这种变化导致分类器的错误判断。
为了解决上述问题,本文提出了一种新的色情图像识别框架。 本文的具体贡献总结如下:
- 为了避免负样本中类型无限的问题,最大限度地减少分类任务中不确定性的影响,提出了一种基于神经网络的色情图像单类分类方法。 就笔者所知,单类图像分类检测色情图像的文献报道甚少。
- 为了提高深度一类分类的性能,将视觉注意机制引入到深度一类分类模型中。 本文将一类分类与视觉注意机制相结合的系统命名为Deep one-class with attention for porn (DOCAPorn)。 该系统能够更加注重目标物体的识别,从而减少图像中复杂背景的干扰。 此外,DOCAPorn可以捕获图像中的小补丁的色情内容。
- 为了在色情图像识别应用中防止对抗攻击,提出了一种压缩重建预处理方法,即压缩重建预处理(Preprocessing for compression and reconstruction, PreCR)。 prer提高了FGSM、DeepFool和C&W攻击方法的防御性能。 据作者所知,本文首次考虑了色情图像识别领域的对抗性攻击。
- 为了适应互联网上不同规模的色情图片,提出了规模约束池(Scale Constraint Pooling, SCP),使输入图像在保持自身规模比例的同时,在全连接层获取固定尺寸。 本文充分考虑了原始图像比例对色情图像识别的影响。
本文的其余部分组织如下。 第二节简要回顾了相关工作。 第三部分解释了区分色情和非色情图像的过程。 第四节介绍了本文提出的色情图像识别方法。 第五节给出实验结果,第六节给出结论。
II. RELATED WORKS
识别色情图片是一个极具挑战性的问题[19]。 在过去的几十年中,人们提出了各种方法来处理这个问题。 一般来说,这些方法可以分为三类:基于人体皮肤的、基于手工特征的和基于神经网络的。 在本节中,我们将对这三个类别进行回顾。
Traditionally, the human skin-based approaches to recognize the pornographic images are natural and simple. These approaches determine the nude body through detecting the human skin [11], [20], and then dene appropriate thresholds of human skin regions in the entire image to recognize the pornography [21]. The human skin-based approaches are highly dependent on the detection of human skin color [22]. For instance, many researchers focused on the color space model to improve the accuracy of the detection of human skin [12], [21][24]. Marcial et al. [21] and Basilio et al. [25] converted the RGB color model into the YCbCr color model in order to improve the accuracy of skin color recognition. Although, the human skin-based approaches are intuitive, they are unable to obtain satisfactory performance. Many normal images may show large regions of human skin (e.g., face close-ups), leading to a large number of false positives. On the other hand, many images with a small amount of human skin may be pornographic. In addition, the appearance of the human skin area signicantly varies with various lighting conditions and backgrounds, which make it extremely difcult to dene an exact threshold of human skin for pornography.
The handcraft feature-based approaches are better than the human skin-based approaches because they consider various types of pornographic image features. The feature selection and extraction in pornographic images are emphasized in these approaches. Wang et al. [26] proposed an approach based on the navel and many-body features to recognize the nudity. Sevimli et al. [27] ltered many face close-ups through face detection and then extracted visual descriptors using four different methods. Zhu et al. [28] proposed an approach based on human skin detection and extracted 31- dimensional features (global image features, human body parts, faces, breasts, vulvas, etc.) to be fed into a random forest classier in order to improve the accuracy of pornography recognition. Tian et al. [29] combined color and shape features to represent the sexual organs for detecting pornographic images. In order to reduce the impact of various colors similar to human skin color such as a beach or aquatic sports in the context, many researchers utilized the visual Bag-of-Visual-Words (BoVW) to extract the feature for recognizing the pornographic images [30], [31]. Moreira et al. [32] extracted features from human skin regions and classied them using machine learning algorithms. In addition, Moreira et al. mitigated false positives in portrait photos by detecting faces. Although the handcraft feature-based approaches usually achieve better detection accuracy, these approaches rely on the accuracy of features recognition. Moreover, the complexity of handcraft featurebased approaches depends on the relevant experience and knowledge of the researchers
2012年,由Krizhevsky等人[33]提出的卷积神经网络模型AlexNet通过将classication错误记录从26%降低到15%赢得了ImageNet竞赛[34]。 这一惊人的进步使得神经网络成为近年来计算机视觉领域的研究热点。 许多研究人员使用神经网络在图像识别和分类cation [35][37]中实现了显著的增强。 最近,许多研究人员采用基于神经网络的方法来识别色情作品[38],[39]。 Moustafa等人结合AlexNet[33]和GoogleNet[40],率先采用神经网络检测色情图像和视频。 2016年,雅虎提出了一种基于ResNet-50架构[41]的深度学习解决方案,用于色情图像检测。 该方案基于强大的ResNet神经网络模型,并通过ImageNet数据集进行预训练。 该方法可以为每个输入图像输出0到1之间的概率,以检测色情。 此外,研究人员采用卷积神经网络从帧中提取特征,检测色情视频[15],[42]。 Wehrmann等人[15]在考虑视频帧间关系的基础上,提出了一种新的深度神经网络结构,将ConvNet与LSTM相结合,用于色情视频的识别。 为了缓解皮肤暴露于色情信息的映射问题,Perez et al.[42]通过光流位移场和MPEG运动矢量将运动信息纳入神经网络模型,提高色情信息自动识别的准确性。 由于关键的色情信息大多位于图像的局部区域,许多研究者认为局部上下文信息对识别色情信息是有用的[43],[44]。 Wang et al.[43]采用卷积神经网络同时获取图像的全局和局部信息,提高色情检测的准确性。 但是Wang等人[43]提出的方法并没有利用局部上下文信息。 为了克服这一问题,Cheng等人[45]提出了一种基于多任务学习方案的成人图像分类的全局和局部上下文集成DCNN。 DCNN可以对端到端网络进行端到端训练,同时考虑局部区域检测和全局分类来优化网络权值。 色情图像的识别是一项具有挑战性的任务,因为图像中关键的色情内容往往位于较小的局部区域。 为了解决这一难题,Jin等人[46]将每个图像建模为一个区域包,并采用多实例学习(MIL)方法训练了基于泛域的神经网络识别模型。
然而,对于负样本中无限类型的问题,以及识别色情图像的分类任务中不确定性的影响,一直没有得到足够的重视。 此外,之前没有研究在_x001D_上调查对抗性攻击对识别色情图片的影响。 研究了图像大小对分类的影响,特别是对色情图像的识别。 因此,色情图像识别还需要进一步的研究。
III. BACKGROUND
本节介绍了背景知识,并给出了基于神经网络技术的色情图像识别的通用模型。
基于神经网络的色情图像识别采用输入图像并输出类(色情、正常等)或最能描述该图像的类的概率。
像素值。 根据图像的分辨率和大小,计算机将看到一个W x H xC的矢量,其中w、h和c分别表示图像的宽度、高度和通道数量。 向量中的每个数字被分配一个从0到255的值,该值描述了点的像素强度。 这些数字是计算机唯一可用的输入。 一般情况下,JPG或PNG格式的彩色图像中的c值为3,即RGB值。 将这些输入向量输入到神经网络模型中,在前向传播训练步骤中通过卷积操作提取图像的边缘特征以及局部和全局特征。 然后通过反向传播和梯度更新策略进行训练,不断优化神经网络模型的参数。 最后,通过这种方法自动提取色情图像的特征,并在模型参数的解空间中确定适合于色情图像到色情类标签或概率的映射。
IV. THE PROPOSED APPROACH
在本节中,将详细介绍所提出的方法。
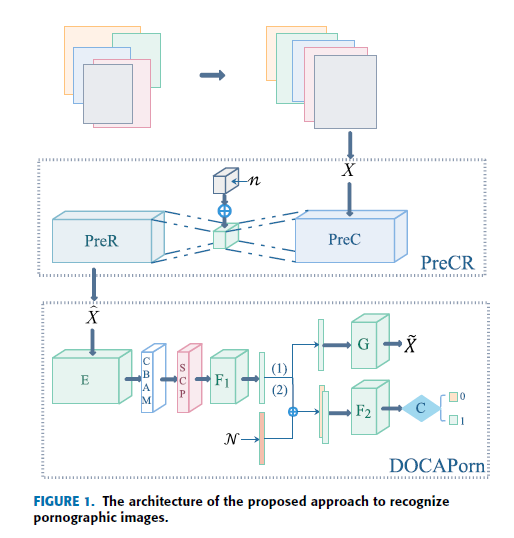
该方法的总体架构包括一个基于注意力的但分类色情模型(Deep One-Class with Attention for porn, DOCAPorn)、一个压缩与重构预处理(Preprocessing for compression and reconstruction, prer)和规模约束池(Scale Constraint Pooling, SCP)。 DOCAPorn专注于色情图像的识别,利用基于神经网络的单分类。 由于神经网络具有良好的特征提取能力,DOCAPorn算法提高了分类性能。 将视觉注意机制引入深度一类分类中,使得神经网络在忽略无关信息的同时,将注意力集中在目标对象上。 此外,还避免了由于负样本类型或数量不足而导致泛化能力低的问题。 此外,由于单分类方法更关注目标对象的识别,添加视觉注意机制有助于减少分类任务中不确定性的影响。 该算法通过对原始图像进行压缩后重建得到的图像来减少干扰,以抵御对抗性攻击。 图像压缩受到图像局部结构中相邻像素之间强相似性和相关性的启发,可以在保留图像主导信息的同时减少冗余信息。 压缩后的图像重建可以抑制对抗扰动的影响。 SCP是提议的最大池化层,用于将不同维度的输入转换为相同维度的输出。 SCP消除了将不同大小的输入图像预处理为相同大小的要求。 这种方法可以最大限度地保留原始图像的尺度信息,避免不必要的几何失真。
所建议的方法的体系结构概述如图1所示。 首先,将原始图像变换为在最短边具有统一的固定长度的图像,并根据图像的大小自适应缩放图像的另一边。 在此基础上,利用该算法对图像进行预处理,通过对图像进行压缩和重构来减少干扰,从而达到防御对抗性攻击的目的。
最后,利用该算法对图像进行识别
- SCP
从本质上说,所使用的SCP是最大池化的一种变体。 它将不同比例尺的特征约束为同一比例尺特征图。 假设输入图像的原始大小为w0;H0。 为了避免图像之间像素数的较大差异,将输入图像的最短边固定为Sf。 同时,输入图像的另一侧根据图像的比例进行缩放。
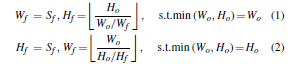
经过上述处理后,将输入图像的大小重塑为Wf;Hf。 它确保输入图像的比例不改变。 然后,通过神经网络的卷积操作,更新各层的feature map大小,如下所示:
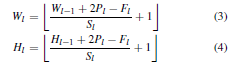
其中Wl和Hl分别为当前层的宽度和高度l, Fl和Pl分别为当前层的卷积核大小和填充大小,Sl为当前层的步长。
通过神经网络对特征图进行一系列变换,得到(WL;HL)大小的数据。
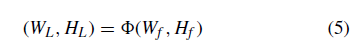
其中 (Wo;Ho) -> (WL;HL)为神经网络进行特征融合前,利用式(3)、(4)连续计算从输入层到隐含层L的特征映射变换而得到的映射函数。 具体的映射取决于所使用的神经网络模型的结构。 理论上,该算法可以代替神经网络中任意一层的最大池化算法。
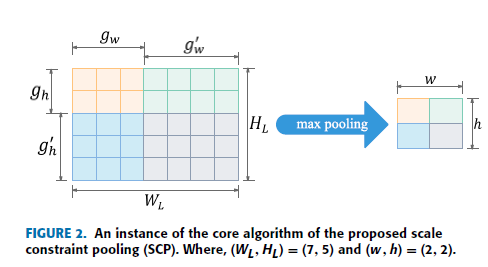
对于不同比例尺的输入图像,其对应的特征图(WL、HL)是不同的。 提出的SCP最大池化算法的目标是将(WL;HL)特征映射划分为(w; H)统一的网格尺度。 即通过SCP max pooling得到一个宽度为w高度为h的feature map网格。 网格中每个子窗口的大小为:
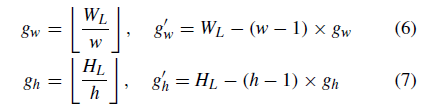
其中gw和g’ w分别表示网格行的前(w - 1)子窗口和最后一个子窗口的宽度。 其中,gh和g’ h分别表示网格列中的前(h-1)子窗口和最后一个子窗口的高度。
然后,在网格的相应区域执行最大池化。 图2显示了所提议的SCP的核心算法的一个实例。
- PreCR
提出的preRC的动机是消除对人类来说极难检测到的干扰。 prer的总体架构如图3所示。 假设输入是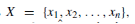 , PreRC的目标是输出纯化的
, PreRC的目标是输出纯化的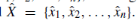
值得注意的是,根据公式(1)和(2),数据X的大小被重塑为(Wf;Hf)。PreRC由子网络PreC和PreR组成。

子网络PreC的目的是压缩图像,其框架是完全卷积的。 为了避免压缩图像中关键细节的丢失,提出的子网络PreC中不存在池化层。 子网络PreC由卷积核大小为 3x3的11个卷积层组成。 每一层的输入通道数等于前一层的输出通道数。 前10个卷积层包含ReLU激活功能。 第11层包含s形激活函数。 这个sigmoid输出允许输入图像xi通过子网络PreC获得不同灰度信息所代表的特征。 利用第一至第六层提取输入图像xi的特征,生成512个特征图。 第一层的输入通道数为3,输出通道数为16。 之后,每层的输出通道数分别为32、64、128、256和512。 在提取特征时,利用剩余的五层构造图像xi的紧凑表示。 第七层的输入通道数为512,输出通道数为256。 之后,每层的输出通道数分别为128、64、32和12。 当原始图像xi通过子网络PreC传播时,在消除扰动的同时提取xi的主要特征。
为了提高重构模型的性能,对子网络PreC的输出进行了随机高斯噪声攻击。 子网PreC受攻击后的输出如下:
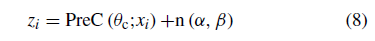
其中PreC()表示子网络PreC的输出,是原始输入图像xi的紧凑表示的特征,表示子网络PreC的学习参数,表示均值和方差值分别为 和 的高斯噪声。 这里,and分别设为0.00和20.00。
为了在重建纯图像时利用子网络进行细节补偿,将反卷积作为子网络PreR的框架。 子网络PreR由11个反卷积层组成,其层的大小为 3。 与子网络PreC一样,每一层的输入通道数等于前一层的输出通道数。 rst的10个反卷积层包含ReLU激活函数。 第一层的输入和输出通道数分别为12和32。 之后,每层的输出通道数分别为64、128、256、512、256、128、64、32、16、3。 最后,对输出的Oxi进行重塑,使其大小与原始输入图像Oxi相同。
压缩后的原始图像到重构后的图像的端到端映射需要通过子网络PreC和PreR的权值共同学习。 通过最小化preCR输出和输入图像Oxi之间的均方误差(MSE)来实现映射。 因此,preR的优化目标为:
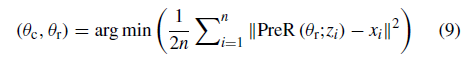
此外,由于所提出的preCR不涉及全连接层,本质上是对像素的预测,因此原始输入图像的大小可以是任意的。 这保留了原始图像的比例信息。
- DOCAPorn
神经网络由输入层、隐藏层和输出层组成,其中隐藏层是主要成分。
为了实现网络的有效设计,本文采用了模块化设计的方法。 建议的DOCAPorn的概述如图4所示。是输入层的数据,经过预处理后,利用该预处理方法重构为纯净的图像。 提出的模块化设计方法将隐层根据不同的功能划分为不同的子网络。
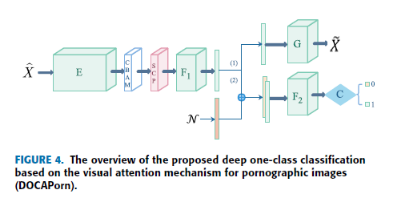
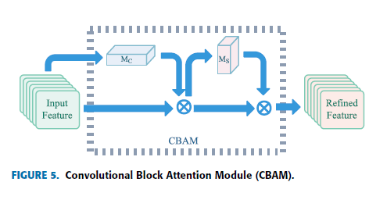
在图4中,E是将原始数据映射到复杂高维特征空间的特征提取子网络。 子网络E的输出可以看作是神经网络从数据中学习到的分布式特征表示。 子网络E可以灵活地融入现有神经网络的任何特征提取体系中。 此外,为了将视觉注意机制融入到所提出的深度单类分类模型中,我们将卷积块注意模块[47]融合到子网络E中。具体来说,在中间feature map之后是CBAM,如图5所示。 由通道注意模块 和空间注意模块
和空间注意模块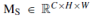 组成。 通道注意模块专注于认为输入图像重要的信息。 Mc模块的定义如下:
组成。 通道注意模块专注于认为输入图像重要的信息。 Mc模块的定义如下:
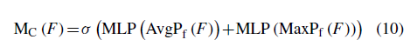
其中AvgPf()和MaxPf()分别表示该层中每个feature map的全局平均池操作和全局最大池操作。 MLP()表示一个带有隐藏层的多层感知器。 具体为,其权重为 和
和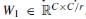 ,其中r为还原比例。 此外,隐含层有一个ReLU激活函数,
,其中r为还原比例。 此外,隐含层有一个ReLU激活函数,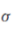 表示s形函数。
表示s形函数。
空间注意模块决定了输入图像的信息部分。 首先,对输入特征的通道维度进行平均池和最大池操作。 然后结合输入特征得到二维特征; 最后,利用带有单个卷积核的隐层进行卷积运算。 模型Ms的定义如下:
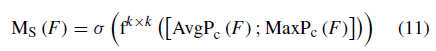
其中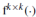 表示卷积核大小是k x k卷积运算。这里,k被设为7。
表示卷积核大小是k x k卷积运算。这里,k被设为7。 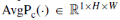 和
和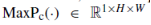
分别表示该层中所有通道的平均池操作和最大池操作。
假设输入特征映射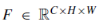 通过CBAM依次传播,中间输出F’通过一维通道注意映射
通过CBAM依次传播,中间输出F’通过一维通道注意映射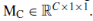 得到。 然后,通过二维空间注意图
得到。 然后,通过二维空间注意图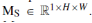
将特征图F重新输出为F''。 以下是CBAM的整体模型:

其中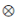 表示元素的乘法。
表示元素的乘法。
为特征融合子网络。 子网络F1的功能是融合子网络E学习到的深度特征。所提出的DOCAPorn框架包含两个子网络F1和F2。 在这种模块化设计方法中,子网F可以由全连接层或全局平均池(Global Average Pooling, GAP)组成。 特别地,子网E和F1是通过所提出的SCP连接的。 当输入数据 通过子网络F1时,将其转换为d维特征向量vi。SCP保证了对不同尺度的输入图像获得相同维d的特征向量。 输出层C是一个分类器。
通过子网络F1时,将其转换为d维特征向量vi。SCP保证了对不同尺度的输入图像获得相同维d的特征向量。 输出层C是一个分类器。
在图4的分支(1)中,G为生成器子网络。 子网络G的本质是带有反卷积模块的解码器网络。 它的输出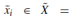
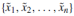 是根据与
是根据与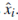 相同维数的子网络F1生成的特征向量vi重建的图像。 这是为了让神经网络学习获取输入数据的特征表示,并用它来重构输入数据。 分支(1)的目的是约束由子网络E生成的单分类数据表示。事实上,子网G和RreR试图根据不同的目的重构图像。 PreR利用高斯噪声攻击后的数据进行训练,重建纯数据。 子网G主要采用子网E学习到的特征表示,并尝试重构输入。这实际上限制了子网络E学习具有自表示特性的表示。 从结构上看,子网络G以及子网络E和子网络F1可以被视为一个“自编码网络”。 分支(1)产生的损耗函数L1定义为:
相同维数的子网络F1生成的特征向量vi重建的图像。 这是为了让神经网络学习获取输入数据的特征表示,并用它来重构输入数据。 分支(1)的目的是约束由子网络E生成的单分类数据表示。事实上,子网G和RreR试图根据不同的目的重构图像。 PreR利用高斯噪声攻击后的数据进行训练,重建纯数据。 子网G主要采用子网E学习到的特征表示,并尝试重构输入。这实际上限制了子网络E学习具有自表示特性的表示。 从结构上看,子网络G以及子网络E和子网络F1可以被视为一个“自编码网络”。 分支(1)产生的损耗函数L1定义为:
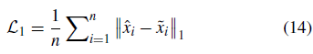
在图4的分支(2)中,N是一个与vi维数相同的零中心高斯噪声,将其附加到特征向量vi上,形成伪类特征向量pi。

生成伪类pi的动机来自以原始为参考寻找单类分类的决策边界的思想。 基于此思想,我们利用潜在特征空间中的零中心高斯噪声作为伪类,利用交叉熵等损失函数训练神经网络,学习给定类的更好的表示作为决策边界。 伪类数据可以用来确定深度类的决策边界。 此外,生成伪类可以避免使用普通图像作为负类。 这样,利用伪类避免了负样本无穷种的问题。
分类器C的功能是区分伪负数据集 目标数据集
目标数据集 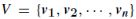 学习决策边界的。 由于在伪类数据中加入了原始特征,分类器C观察批大小2的输入。 因此,分类器C可以是输出量为2的softmax回归层。 伪类和色情类的数量均为n,因此损失函数的输入样本总数为2n。 分支(2)产生的损耗函数L2定义为:
学习决策边界的。 由于在伪类数据中加入了原始特征,分类器C观察批大小2的输入。 因此,分类器C可以是输出量为2的softmax回归层。 伪类和色情类的数量均为n,因此损失函数的输入样本总数为2n。 分支(2)产生的损耗函数L2定义为:

式中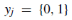 ,
,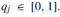 。
。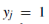
表示特征向量被归为目标数据,否则(yj =0)为伪负数据。 这里,qj和1-qj分别表示yj=1和yj=0的概率。
最后,将分支(1)和(2)的损失函数合成为所提DOCAPorn的整体损失函数L。 定义为:

其和均为常系数,均设为0.50,以简化整体损失函数L。
- EXPERIMENTS
- EXPERIMENTAL ENVIRONMENT AND DATASET
在实验中,研究人员从网上收集了62500张色情图片,包括各种姿势、大小、动作和特写镜头。 为了适应人类肤色的差异,收集的图像包括白人、黑人和亚洲人。 为了解决由于数据不足而导致的过拟合问题,对收集到的数据采用了数据增广的方法。 通过一定的先验知识,在保留图像中的色情信息的同时,对原始数据进行适当的操作,如_x001D_翻转图像,改变图像的亮度和锐度。 通过这种方式,数据集获得了50万张色情图片。 训练集、验证集和测试集分别为数据集的80%、10%和10%。 此外,还收集了来自互联网和ImageNet数据集的50万张正常图像作为非目标类进行对比分析。 非目标类的训练集、验证集和测试集分别占数据集的80%、10%和10%。 此外,使用NPDI[48]色情数据库作为实验的测试。 NPDI包含近80个小时的400个正常视频和400个色情视频。 该数据库由不同种族的人组成,包括黑人、白人和黄种人。 因此,NPDI数据库中含有符合真实互联网环境的色情图片。 对于普通类,它包括两个子类:一半的视频是随机选择的(称为“简单”),而另一半是从文本搜索查询中选择的,如游泳、海滩和摔跤。 后半部分的视频包含大量的人类皮肤,但没有色情内容(称为“困难”),这对识别器来说是一个特别的挑战。 从色情视频和普通视频中分别提取了10000帧关键帧。 这些关键帧被用来测试提出的框架的准确性。
- IMPLEMENTATION DETAILS AND EVALUATION METRICS
在实验中,将输入图像的固定最短边设置为224(即Sf D 224)。 本文参考VGG19[49]神经网络模型设计了所提出的DOCAPorn。 子网E采用VGG19最后一次最大池前的结构。 在本框架中,VGG19的最后一个最大池被提议的SCP替换。 SCP的网格大小为7x 7(即,(w; h) = (7; 7)),与VGG19的最后一个最大池相同。 子网络F1是VGG19中的第一个全连接层(即FC-4096)。 子网络F2由VGG19中除第一全连接层外的其余全连接层组成。 另外,在子网络F2的最后一层增加了一个具有二维矢量输出的全连通层。 子网络G由四个完全卷积层(怀疑这里应该是反卷积层)组成。 它采用子网络E学习的特征表示,并尝试在DOCAPorn中重构输入。
超参数值的选择是基于使用验证集在向量空间上的网格搜索。 preCR设置的超参数为:batchsize= 500, epoch =101, Learning Rate = 0.0001。 DOCAPorn设置的超参数为:batch-size = 1000, epoch =101, Learning Rate = 0.0001。 图6和图7分别显示了训练时的损失和验证集中色情图像识别的准确性。
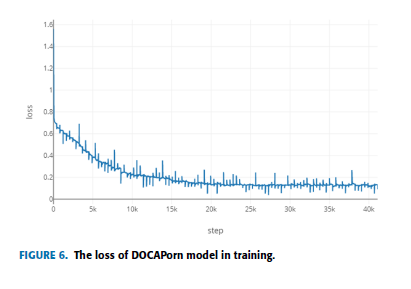
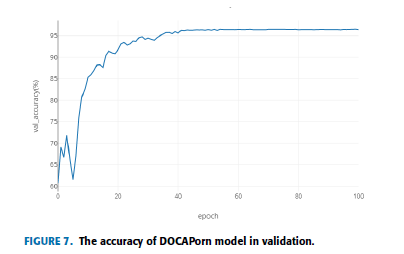
如图6和7所示,在6000步的初始阶段,识别准确率从60.72%迅速提高到87.63%左右,这与初始学习阶段有关。 在初始阶段识别率也相对较低。 由于学习刚刚开始,准确率相当低,但提高得很快。 同时,如图7所示,loss的值在此期间从1.56急剧下降到0.34。 从步骤6000到16000,识别准确率从87.63%逐渐提高到95.59%。 同时,随着loss值从0.34减小到约0.16,训练过程逐渐趋于稳定。 从16000步到24000步,正确率从95.59%提高到96.43%左右,而识别正确率的提高比较缓慢。 loss值保持在0.13左右,说明学习过程基本完成。 最终,培训在第40,400步结束。 在实际应用中,为了克服模型的过拟合问题,当epoch达到60时停止训练。
- EXPERIMENTS AND ANALYSIS
为了评价该方法的性能,将其与基于人体皮肤、基于手工特征和基于神经网络的色情图像识别方法进行比较:
(1) 基于皮肤的:采用Marcial et al.[21]的方法进行对比实验。 它是基于人体肤色识别的代表性方法之一。
(2) 基于BoVW的方法:将Deselaers等人[30]提出的基于BoVW的方法进行实现,与所提方法进行比较。 鉴于BoVW方法是手工设计特征中比较有优势的算法,本文将此方法作为基于手工特征的一种代表性方法。
(3) 基于cnn的:采用Moustafa等人[13]提出的简单卷积神经网络进行色情图像识别对比实验。 本文以基于神经网络的方法为代表。
(4) 基于resnet的:将NSFW[50]项目与所提出的方法进行比较。 这是一个基于ResNet-50的雅虎色情图片识别的开源神经网络模型。 它是识别色情图像的最先进的方法之一。 本文将它作为基于神经网络方法的另一个代表。
(5) 基于异常的:Xception[51]是谷歌开发的功能强大的神经网络模型。 本文设计了一种基于异常的神经网络,并与该方法进行了比较。 与(3)和(4)相比,本实验只是对神经网络模型的一个改变。 本研究旨在探讨不同神经网络模型对色情图像识别的影响。
表1显示了本文方法与上述方法的对比结果。 这些实验在相同的数据集下进行比较。 图9显示了该方法与其他方法的混淆矩阵。
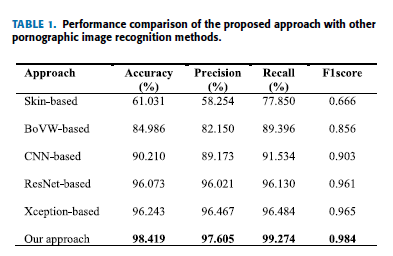
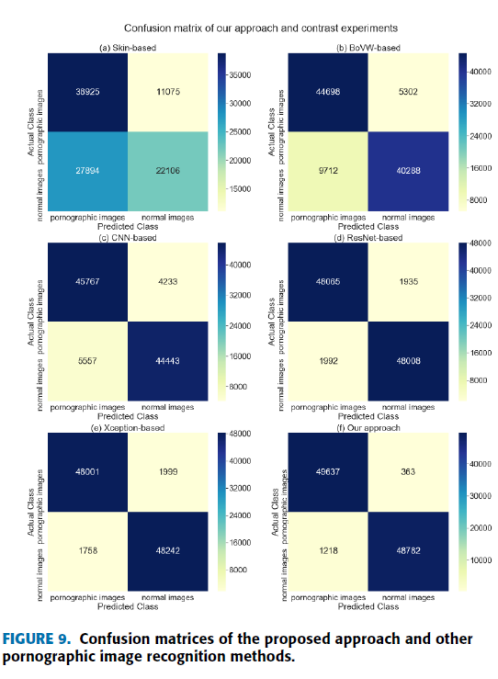
如表1所示,基于皮肤的方法的性能不如其他方法。 基于skin的方法将许多肤色比例较大的正常图片(如比基尼)误认定为色情图片,导致误报率较高。 基于cnn的方法在性能上优于基于skin和bovw的方法。 这是因为cnn能够完全提取复杂、高维和抽象的图像特征。 这些特征比手工特征更有代表性。 此外,精心设计的神经网络模型(如基于resnet、基于exception和我们的方法)优于简单的神经网络模型(如基于cnn)。 从表1可以看出,本文提出的方法比五种方法中的任何一种都具有最高的性能。 由于所提出的深度单类分类方法避免了负样本无穷和分类不确定性的问题,降低了FNR。 此外,图10将本文提出的方法与使用NPDI数据库的其他色情图像识别方法的准确率进行了比较。 可以看出,本文提出的方法在NPDI数据库中仍然具有最高的精度。

