时间动态协同过滤(TimeSVD++)
原作者

原论文地址
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.379.1951&rep=rep1&type=pdf
本文地址:https://www.cnblogs.com/kyxfx/articles/9414823.html
一直没有找到完整的TimeSVD++译文,就自己翻译了一下。
4.2时间改变基线预测
通过两个主要的时间效应,大部分时间变化包含在基线预测中。首先是解决一个项目的受欢迎度随着时间而改变的事实。例如,电影可以因外部事件(如新电影中演员的出现)或冷或热。体现在我们的模型中,项目偏差bi不是常数,而是随时间变化的函数。第二个主要的时间效应与用户偏见有关——用户会随着时间改变他们的基线评分。例如,一个倾向于评价电影评分“4星”的用户,因为各种原因现在可能会对这样的电影评分“3星”。因此,在我们的模型中,我们希望将参数bu作为时间的函数。这就引出了对时间敏感的基线预测:
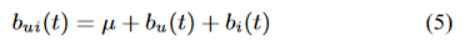
函数bui(t)表示用户u在t日对项目i的评分的基线估计值。这里,bu(t)和bi(t)是随时间变化的实值函数。构建这些函数的确切方法应该反映出一种合理的方法来参数化涉及的时间变化。我们将在电影评分数据集的上下文中详细说明我们的选择,它展示了一些典型的参考因素。一个主要的区别是时间效应跨越时间的延长和缩短的效应。在电影评分的情况下,我们不希望电影的受欢迎度每天都在波动,而是在更长的时间内发生变化。另一方面,我们观察到用户的影响每天都在变化,反映了客户行为的不一致性。在建模用户偏差时,这需要更精确的时间解析,而较低的分辨率足以捕获与项目相关的时间效应。
首先对于产品偏差,由于我们不需要太精细的分辨率,所以可以将产品偏差分割为基于时间的bin。在每个时间区间对应的bin我们使用一个不同的产品偏差。如何将时间轴分割为时间bin应该在得到更精细的分辨率(更小的bin)和在每个bin中有足够的评分之间进行权衡。在TimeSVD++论文中每个bin为连续十周的数据。因此在整个数据集上大概有30个bins。t对应一个Bin(t)(在我们的数据中是一个1到30的数),这样电影偏差就被分割为一个静态部分和一个时间变化的部分:
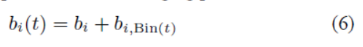
对于用户偏差来说,情况就要更复杂了。如何对用户的时间区间进行不同粒度的划分是首要要考虑的问题。
第一个模型选择是非常简单,使用一个线性函数刻画了用户评分偏差的可能的逐渐的漂移。我们首先引入一些新的符号,对每个用户,我们将其评分的日期的均值表示为tu。现在,如果用户在第t天评价了一部电影,那么这个评分相关的时间偏差定义为:
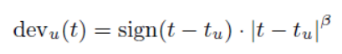
这里| t−tu|表示t和tu之间的时间距离(例如,天数)。我们通过交叉验证设置β的价值;在我们的实现中 β= 0.4。我们为每个用户引入一个名为αu的新参数,这样我们就可以得到依赖于时间的用户偏差的第一个定义:
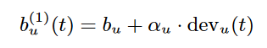
这提供了一个简单的线性模型来近似一个漂移行为,这需要每个用户学习两个参数:bu和αu。样条提供了一种更灵活的参数化。设u为与nu个评分相关的用户。我们设定以ku个时间点- {tu1,…, tu} -为核心均匀分布在u的评分数据上,公式为:
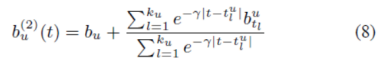
参数![]() 与控制点(或内核)相关联,并从数据中自动学习。这样,用户偏差就成了这些参数的时间加权组合。通过控制点的数量ku平衡灵活性和计算效率。在我们的应用中,我们设
与控制点(或内核)相关联,并从数据中自动学习。这样,用户偏差就成了这些参数的时间加权组合。通过控制点的数量ku平衡灵活性和计算效率。在我们的应用中,我们设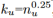 ,让它随着可用评分的增加而增长。常数γ决定了样条的平滑;我们通过交叉验证让γ= 0.3。
,让它随着可用评分的增加而增长。常数γ决定了样条的平滑;我们通过交叉验证让γ= 0.3。
到目前为止,我们已经讨论了用于建模用户偏差的平滑函数,它与逐渐的概念漂移很好地结合在一起。然而,在许多应用程序中,突然出现的漂移“峰值”是与一天或一段时间有关的。例如,在电影评级数据集中,我们发现用户在一天内给出多个评级,往往集中在一个值上。这种影响不会超过一天。这可能反映了用户当天的情绪、一天内给出的评分对彼此的影响,或者是多人账户中不同用户的评分。为了解决如此短的生命效应,我们为每个用户和一天分配一个参数,表达特定于一天的变化。这个参数表示为bu,t。注意,在某些应用程序中,要使用的基本原始时间单位可能比一天短或长。例:我们的一天的概念可以替换为用户会话的概念。
在Netflix电影评分数据中,用户平均在40天内进行评分。因此,使用bu,t每个用户平均需要40个参数来偏差。估计bu,t作为一个独立的工具来捕获用户偏差是不够的,因为它会遗漏超过一天的所有信息。因此,它只作为前面描述的方案中的一个附加部分。时间线性模型(7)为:
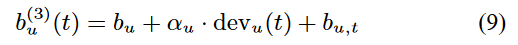
同样,基于样条的模型变成:
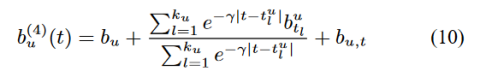
基线预测器本身不能产生个性化的建议,因为它忽略了用户和项目之间的所有交互。从某种意义上说,它正在获取与产生建议不太相关的数据部分,这样做可以得到准确的建议。尽管如此,为了更好地评估依赖时间的用户偏差的各种选择的相对优点,我们将比较它们作为独立预测器的准确性。为了学习相关参数,利用随机梯度下降法最小化相关正则化平方误差。例如,在我们的实际实现中,我们采用规则(9)对漂移的用户偏差进行建模,从而得出基线预测器:
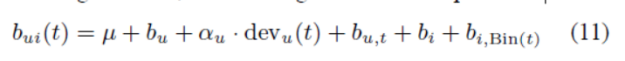
求解:
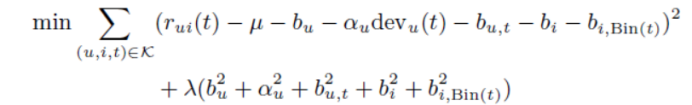
在这里,第一个公式致力于构造符合给定评分的参数。正则化项λ(…)通过降低参数大小来避免过拟合。通过随机梯度下降算法进行20-30次迭代,λ为0.01。

除了目前所描述的时间效应之外,我们还可以使用相同的方法来捕捉更多的效应。一个主要的例子是捕捉周期性的效应。例如,有些产品可能在特定的季节或临近的假日更受欢迎。同样,不同类型的电视或广播节目在一天的不同时间段(被称为“时段”)都很受欢迎。在用户方面也可以发现周期性的影响。例如,用户在周末的态度或购买模式可能与工作日不同。对这种周期效应建模的一种方法是为时间周期与项目或用户的组合指定一个参数。这样,式(6)的项偏差变成:
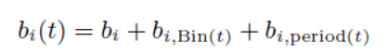
例如,如果我们试图捕捉项目偏差与季节的变化,然后时间(t)∈{秋天,冬天,春天,夏天}。同样,重复出现的用户效果通过将(9)修改为:
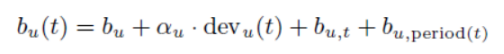
例如,如果我们试图建模一周中的周几的用户影响,则时间(t)∈{星期天,星期一,星期二,星期三,星期四,星期五,星期六}。我们无法在电影数据集中找到具有重要预测能力的周期效应,因此我们报告的结果不包括这些:
基本预测器范围内的另一个时间效应与用户评分的变化范围有关。虽然bi(t)是t时刻i项的偏好的用户无关度量,但用户对这种度量的反应往往不同。例如,不同的用户使用不同的评分尺度,单个用户可以随时间改变其评分尺度。因此,电影偏见的原始值并不是完全用户无关的。为了解决这个问题,我们向基线预测器添加了一个时间相关的缩放特性,用cu(t)表示。因此,基线预测器(11)变为:
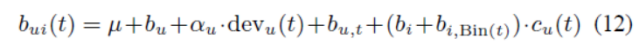
所有讨论的实现bu(t)的方法对于实现cu(t)也是有效的。我们选择每天分别给出一个参数,得到:cu(t) = cu+cu,t。与往常一样,cu(t)是cu(t)的稳定部分,而cu,t代表日变化性。在基线预测器中加入乘法因子cu(t)可使RMSE降低到0.9555。有趣的是,这个基本模型只捕获了不考虑用户项目交互的主要效果,它可以解释几乎和商业的Netflix Cinematch推荐系统一样多的数据变化,后者在同一测试集中发布的RMSE为0.9514[4]。
4.3时间变化的因子模型
在前面的小节中,我们讨论了时间对基线预测器的影响。然而,正如前面所暗示的,时间动态不仅如此,它们还会影响用户偏好,从而影响用户与项目之间的交互。用户会随时间改变他们的偏好。例如,“心理惊悚片”的粉丝一年后可能会成为“犯罪剧”的粉丝。同样,人类也会改变对某些演员和导演的看法。这种效果是通过将用户因素(向量pu)作为时间的函数来建模的。同样,我们需要在每天的基础上对这些变化进行非常精细的建模,同时还要面对用户评分的内在稀缺性。事实上,这些短时的影响是最难捕捉的,因为偏好并不像主要的影响(用户偏见)那么明显,而是在许多因子上产生分歧。
就像我们对待用户偏置的方式一样对待用户偏好的每个组成部分pu(t) t = (pu1(t),…puf(t))。在我们的应用中,我们发现类似公式(9)的建模有效:

这里puk捕获了因子的静止部分,αuk·devu(t)近似于随时间线性变化的可能性部分,而puk,t吸收了非常局部的、特定于一天的变化。
在这一点上,我们可以将所有的部分连接在一起,通过合并时间变化参数来扩展SVD++因子模型。这导致了一个模型,它将被记为timeSVD++,其预测规则如下:
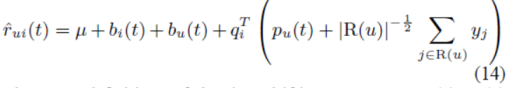
在(6)、(9)和(13)中给出了时间漂移参数bi(t)、bu(t)和pu(t)的准确定义。学习是通过使用正则化随机梯度下降算法最小化训练集上的平方误差函数来实现的。该方法与原始SVD++算法[8]相似;为了简洁起见,此处省略了细节。每次迭代的时间复杂度仍然与输入数据的大小成线性关系,而与SVD++ +相比,时钟周期的运行时间大约增加了一倍,因为更新时间参数需要额外的开销。重要的是,收敛速率不受时间参数化的影响,并且在30次迭代中收敛。
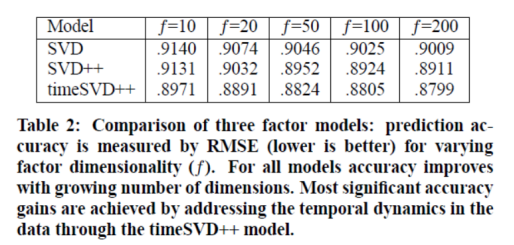
在比较过去对数据集的RMSE改进时,处理时间动态会导致在电影评分数据集内获得显著的精度提升。在表2中,我们比较了三种算法的结果。首先是由公式(3)表示的朴素矩阵分解算法,用SVD表示。第二,SVD++方法(4)被认为是对SVD的显著改进,同时也包含了一种隐式反馈[8]。最后是新提出的timeSVD++,它解释了(14)中的时间效应。这三种方法在一系列分解维数(f)上进行了比较。所有方法都受益于越来越多的因子维数,这使它们能够更好地表达复杂的电影用户交互。请注意,timeSVD++对SVD++的改进始终比SVD++对SVD的改进更为显著。事实上,我们不知道文献中有哪一种算法能提供如此精确的结果。我们把这归因于正确处理时间效应的重要性。进一步说明捕获时间动力学的重要性的是,10维的timeSVD++模型已经比200维的SVD模型更准确。类似地,维度20的timeSVD++模型足以胜过维度200的SVD++模型。
5 基于邻域模型的时间动态
(不翻译了,基本与上面是类似的思路,直接贴公式)
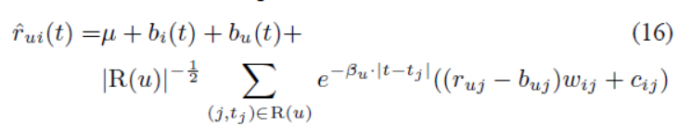
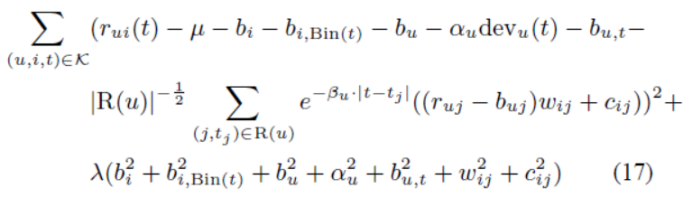
转载请注明出处:https://www.cnblogs.com/kyxfx/articles/9414823.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号