

利用强化学习处理冷启动的协同过滤
原论文地址:https://arxiv.org/pdf/1806.06192v1.pdf Handling Cold-Start Collaborative Filtering withReinforcement Learning
原作者:
本文地址:https://www.cnblogs.com/kyxfx/articles/9341516.html
2相关工作
最近在协同过滤方面的许多工作利用了强化学习技术。Shani等人[2005]的一种方法是将推荐系统视为Markov决策过程(MDP),并使用RL技术来解决。Leel等[2012]也将问题形式化为MDP,利用Q-learning了解用户评分时间序列之间的联系。Choi等人[2018]利用双聚类技术将问题描述为一个gridworld游戏,以大幅度减少动作和状态空间。为了使用RL技术解决冷启动问题,Nguyen等人[2014]将其视为上下文bandit问题。他们提出了一种基于流行的LinUCB算法Li等[2010]的上下文bandit问题的新方法。
在过去,Schein等[2002]在一个单一的概率框架下将内容和协作数据结合在一起。Park和Chu[2009]提出了一种两两预测系统,用于构建基于特征的回归模型,利用用户人口统计信息、项目内容特性以及其他关于用户和项目的信息来解决冷启动问题。该模型以用户的评分为目标,使用两个向量xu和zi来预测用户xu给出的项目zi的评分rui,其中u是用户的索引,i是项目的索引。
指标函数表示为:
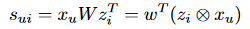
(zi⊗xu)代表zi和xu的外积。优化方程为:
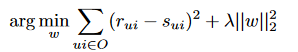
协同过滤的统计方法是概率矩阵分解(PMF)、Mnih和Salakhutdinov[2008]。PMF随观测次数线性伸缩,在稀疏数据上表现良好。例如,假设一个评级矩阵R,其中每一行对应一个用户,每一列对应一个电影。如果R是 N×M维,PMF提取一个N×D矩阵UT和D×M矩阵V 且 R =UTV, 其中D是潜在的空间的维数。一个变种使用贝叶斯方法处理PMF被称为贝叶斯概率矩阵分解(BPMF), Salakhutdinov和Mnih[2008],被证明优于简单的PMF。
一个成功的解决冷启动的方法是为良好的推荐预先做问卷调查以学习用户的兴趣。Golbandi等人[2011]建议通过bootstrapping算法构建初始问卷调查的决策树。它们为初始问卷构建了一个决策树,每个节点都是一个问题,允许推荐器根据用户先前的回答自适应地查询用户。
周等人[2011]在前人的基础上提出了函数矩阵因子化。在这种情况下,潜在特征与决策树的每个节点相关联,因此用户特征是所有可能的问卷答案的函数。它是一种在决策树构建和潜在概要特征生成之间进行交替迭代优化的算法。这有助于同时学习问卷的最佳决策树和生成好嵌入向量。属性ui以函数的形式与用户i的回答绑定;因此称为函数矩阵分解(fMF)。给定一个答案集ai,用户属性由ui = T(ai)生成。目标是从观察到的评分集中学习T和vj(项目属性)。
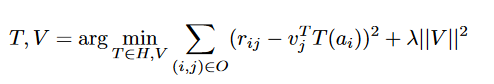
在这里,用户属性uii = T(ai)被建模为用户根据问卷问题给出的答案的函数。rij表示实际的项目评分,vj是项目属性的潜在表示。
3方法
针对协同过滤中的冷启动问题,我们提出了一种新的基于问卷的方法。BPMF、Salakhutdinov和Mnih[2008]为了进行协作过滤,基于数据集中已经存在的热启动用户的评分创建电影嵌入向量。为了生成冷启动用户的嵌入向量,我们提出了一种问卷方法。对于提出理想的问题,我们实现了一个深度Q网络(DQN),生成问卷问题,由冷启动用户来回答。面试由DQN生成表单的问题:“你喜欢λ吗?”,λ是来自所有电影的动作空间。用户可以通过给电影1-5评分来回答面试问题,或者回答说他或她没有看过这部电影,我们认为这部电影的评分为0。根据用户对前一个问题的响应,DQN将动态生成后续问题。一旦访谈完成,问题回答对将被传递到多层感知器模型中(MLP),并生成一个预测的用户嵌入向量。一旦我们有了用户嵌入向量和电影嵌入向量,我们就可以对电影评级进行建模。

对于一些函数f,ui的是用户u的嵌入向量,mj是电影j的项目嵌入向量,ˆrij用户i对电影j的预测评分。
我们训练我们的深度Q网络,使状态是一组来自问卷的问答对的表示。在每个面试问题之后,状态更新并通过DQN生成下一个问题。DQN的动作空间是所有关于问卷问题可能产生的电影的集合。一旦我们完成了问卷,终端状态将被传递到MLP中,以创建一个预期的用户嵌入。预测的用户嵌入然后被冷启动用户用来生成所有电影的预测评级。
为了训练我们的DQN,我们计算了电影评分预测的RMSE,并将RMSE的倒数作为我们行为的奖励。对于长度为k的访谈,以及相应的动作a 1·····a k,对于所有动作at,t < k,我们将立即获得0的奖励。动作ak的奖励是电影预测评分RMSE的倒数。也就是
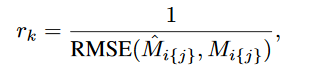
ˆMi{ j }是一组预测的用户i的电影评分,Mi{ j }是实际的用户i的电影评分。因此,对一个动作的奖励at是

gamma是衰减系数
在典型的Q- learning设置中,我们只更新我们所观察到的动作的Q函数。我们对Q函数进行了稍微修改的更新,在这个更新中,我们将先前选择过的任何动作的奖励设置为0。也就是说,我们更新Q函数,使重复的问卷问题的q值为0。
MLP是通过监督学习进行训练的。我们以两种不同的方式探索MLP的训练。在第一个方式中,将由BPMF模型生成的用户嵌入向量作为真实值对MLP进行了训练。在第二种场景中,MLP直接针对用户的实际电影评分进行训练。前者的MLP的输入是DQN的最终终止,而后者的MLP 的输入是DQN的终止状态、待预测评分的电影ID和数据集中电影评分平均值。在这两个设置中,MLP的输出也是不同的。通过用户嵌入向量训练的MLP输出一个预测的用户嵌入向量,而通过电影评分训练的MLP输出一个指定电影的预测评分。为了便于说明,我们将第一个模型作为我们的Q-Embedding模型,将第二个模型作为我们的Q-Rating模型。
3.1 Q-Embedding 模型
Q-Embedding模型如图1所示。该模型是一个结合了DQN和MLP的复合网络。DQN以维数大小是动作空间的两倍的初始状态向量作为输入。这个维度需要表示每一个可能的面试问题-答案对。DQN输出一个等于作用空间的q值向量。给定DQN输出,我们选择要询问的面试问题,并根据用户的回答更新状态。新的状态然后被传递回DQN,直到我们完成我们的访谈。问完最后一个问题后,我们将最后一次更新状态,并将终端状态传递到MLP中。MLP学习一个将终端状态转换为用户嵌入向量的函数。DQN使用上面描述的奖励函数进行训练,而MLP使用BPMF用户嵌入向量作为真实值进行训练。
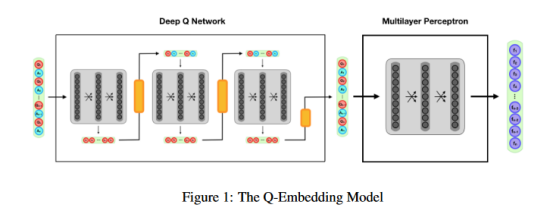
我们实现一个问卷长度为3的Q-embedding模型。DQN动作空间由数据集中最常用的100部电影组成,DQN有两个隐藏层。它需要输入一个200维的状态向量。第一个隐藏层是一个密集层,有64个神经元和一个relu激活。第二个隐藏层是一个密集的层,有32个神经元和一个relu激活。在每一层,我们使用0.5的dropout率来规范和防止过拟合。输出层是密集层,有100个神经元和一个relu激活。我们使用学习速率为5e-4的Adam优化算法和分类交叉熵损失函数。
MLP接受一个200维状态向量作为输入。MLP有两个隐藏层。两个隐藏层都是密集连接层,有32个神经元和relu激活功能。这两层都利用0.5的dropout率来规范和防止过度拟合。输出层是一个密集层,有10个神经元和tanh激活。MLP使用Adam优化算法,学习速率为1e-4,并使用均方根误差损失函数。
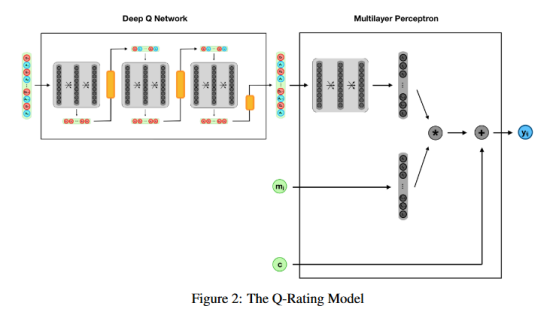
3.2 Q-Rating 模型
Q-Rating模型如图2所示。该模型也是一个将DQN与MLP相结合的复合网络。DQN的行为与Q-Embedding模型中的DQN类似。Q-Rating模型的MLP与Q-Embedding模型的MLP略有不同。与Q-Embedding模型不同,Q-Rating模型直接预测电影的用户评级。Q-Rating MLP需要三个输入:DQN的终端状态、电影id和平均电影评分。注意,在所有电影和终端状态下,电影的平均评分都是恒定的。MLP将用户和电影嵌入到潜在的空间中。MLP使用类似在Q-embedding模型中一样的结构创建用户嵌入向量。此外,MLP将电影嵌入到一个潜在的项目空间中。电影嵌入向量是预先训练的BPMF电影嵌入向量;然而,嵌入层与用户嵌入层并行地重新训练。在MLP嵌入用户和电影之后,它获取两个嵌入的内积,并向加上平均电影评分。平均电影评分和嵌入向量内积的总和输出为用户的电影评分预测。
 ‘’
‘’

我们实现了长度为3的问卷的Q-Rating模型。DQN动作空间由数据集中最常用的100部电影组成,DQN有两个隐藏层。它需要输入一个200维的状态向量。第一个隐藏层是一个密集层,有64个神经元和tanh激活。第二个隐藏层是一个密集的层,有32个神经元和一个tanh激活。在每一层,我们使用0.5的dropout率来规范和防止过拟合。输出层是密集层,有100个神经元和一个relu激活。我们使用学习速率为5e-4的Adam优化算法和分类交叉熵损失函数。
Q-Rating模型的MLP具有三个流。第一个流接受状态向量作为输入,并使用与Q-Embing模型中的MLP相同的体系结构创建一个用户嵌入向量。第二个流作为影片的输入。这个流有一个嵌入层,将电影嵌入到一个10维的潜在空间中。前两条流通过它们之间的内积合并在一起。因此,在合并之后,只剩下一个标量值。第三个流将数据集中的平均电影评分作为输入。这第三条流被添加到前两条流的内积。得到的总和是MLP的输出,一个1维标量表示预测的用户电影评分。MLP使用Adam优化算法进行训练,学习速率为1e-4,并使用一个自定义损失函数,在计算真实评分和预测评分的均方根误差之前,将预测评分剪辑为1到5。
3.3 超参数
两种模型训练使用的衰减系数γ= 1。在训练模型的同时,我们使用e-greed策略来选择动作。我们从e=1开始训练,递减5e-2直到e=0.2。我们利用重复训练的方式对模型进行训练。也就是说,在模型看起来稳定之后,我们使用性能最好的模型重新开始训练。当重新开始训练时,我们重置e=1,将DQN的学习率降低到1e-5。
4 Experiments
4.3 Results
5 讨论
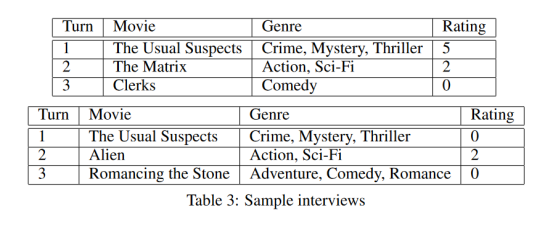
表3给出了两个用户的样本访谈。第一个问卷问题(对所有用户来说都是一样的)是普通的猜测。根据用户的回答,选择下一个问卷问题。从访谈样本中有趣的观察是,每个问卷问题都会询问用户不同类型的电影。由于没有电影元信息提供给学习器,这证明了Q网络在电影空间上的推理能力特别强。从直观上看,一个期望问关于不同系列电影的问题可以帮助模型全面地了解用户。
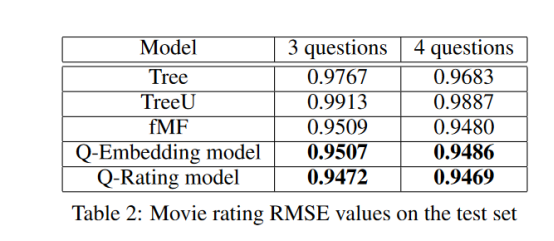
对比图3和图4中的Q-Rating模型和Q-Embedding模型,我们发现Q-Rating模型比Q-Embedding模型更稳定。Q-Embedding模型策略在大约500次迭代之后,在重新学习一个成功的策略之前就会出现分歧。另一方面,Q-Rating模型并没有偏离,而是更加稳定地改进或保持它的学习策略。
我们还观察到,Q-Rating模型优于Q-Embedding模型。这种行为与期望一致,因为Q-Rating模型同时学习电影嵌入向量与用户嵌入向量,而Q-Embedding模型使用静态的BPMF电影嵌入向量。此外,Q-Rating模型通过直接最小化预测电影评分的RMSE而进行训练,而Q-Embedding模型通过最小化预测用户嵌入向量的MSE和BPMF用户嵌入向量来间接最小化预测电影评分的RMSE。
Q-Embedding模型在一台配备2.7 GHz的i5处理器和8GB的RAM的MacBook Pro上训练,每100个用户需要约1.3秒的时间。Q-Rating模型在同一设备上训练大约每100个用户3.2秒。因此,在MovieLens数据集中训练Q-Rating模型需要大约3倍的时间。考虑到这一点,当处理非常大的数据集(例如,1亿级的Netflix数据集)时,可能更喜欢Q-Embedding模型。我们注意到Q-Embedding模型的每一个训练的迭代时间与数据集的大小无关。相比之下,Q-Rating模型可能无法扩展到大型数据集。
令人印象深刻的是,尽管这些模型接受了3个问题的温泉,但这两种模式都能很好地概括出4个问题的问卷。Q-Embedding模型通过问第四个问题将RMSE降低了2e-3,Q-Rating模型将RMSE降低了3e-4。我们假设,如果训练模型使用4个问题的问卷,这些RMSE的减少会更大。
除了我们的模型提供的改进性能之外,我们相信我们的模型架构比基于决策树的模型有许多先天的优势。
用强化学习估计Q函数的一个优点是,冷启动问卷可以包含任意数量的问题。这使得有耐心的用户可以花更多的时间在冷启动设置下调整他们的个人属性,而没耐心的患者用户可以缩短他们的问卷。我们的模型的另一个优点是它们可以应用于热启动用户。给定一组来自热启动用户的电影评分,我们可以为DQN创建一个状态输入并生成新的问卷问题。这可以用来细化一个热启动用户的嵌入向量。相比之下,基于决策树的面试将无法为热启动用户生成理想的问卷问题。给定一个热启动用户和一个决策树,面试将需要从任意节点开始。如果开始节点太深,问卷将在更低的节点选择问题失败。相反,如果起始节点在树中太浅,那么访问将无法考虑一个热启动用户评分的完整上下文。我们模型的第三个优点是DQN估计的Q值可以用于自主学习。估计的Q值提供了在某个时间点问用户指定问题的重要程度。我们设想了两种可能的应用。其中一个应用是,如果模型估计了问题的边际效益是显著的,那么它就可以动态地提示热启动用户进行访问。另一个应用是,如果它估计边际效益很小,该模型可以动态地停止问卷。
6 后期工作
进一步的研究可能包括改进DQN在大型操作空间中的性能。我们的DQN在学习100部最常用电影时表现良好;但是,当操作空间增加时,模型性能会下降。理想情况下,系统应该能够处理所有电影的操作空间。为了在更大的操作空间中提高性能,我们实施了Dueling Deep Q Networks, Wang et al.[2015],以及策略梯度法,如enhance, Williams[1992]。这两种方法都被认为可以在大型操作空间中提高性能。不幸的是,这两种方法都不能像DQN解决受限的操作空间一样解决大的操作空间。在大型电影动作空间中导航的一种可能的方法是开发一个复合的Q网络,使用多个Q学习器首先选择要询问的电影类型,然后在选择的类型中选择要查询的合适的电影。进一步研究的另一个方面可能包括合并电影和用户元数据。
7 结论
我们开发了一个复合的深度Q网络来学习如何在电影推荐系统中处理冷启动用户。据我们所知,我们的模型比其他所有类似的方法都要好。此外,与基于决策树的方法相比,我们的模型具有一些继承优势,如适应热启动用户和执行自主学习。像我们在电影推荐设置中训练我们的模型一样,我们提出的方法应该广泛地推广到所有类型的推荐系统中。
转载请注明出处:https://www.cnblogs.com/kyxfx/articles/9341516.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号