理解人们如何使用自然语言寻求建议
来源 https://www.cnblogs.com/kyxfx/articles/9188759.html
论文地址 http://files.grouplens.org/papers/harper-recsys2017.pdf
摘要
使用自然语言与推荐系统对话的技术障碍正在消失。目前已有一些商业系统可以使用AI代理来辅助交互。例如,有可能说“我可以看什么”到一个苹果电视遥控器来获得建议。在这项研究中,我们调查了用户如何与一种新的自然语言推荐系统进行交互,以加深我们对这些技术预期的输入范围的理解。我们将一个自然语言界面部署到一个推荐系统中,我们观察用户的第一个交互和后续查询,我们测量了基于语言和基于类型的接口之间的差异。我们使用定性的方法来对用户的第一次查询(客观的、主观的、导航的)和后续查询(细化、重新制定、重新开始)进行分类。我们使用定量的方法来确定语音和文本之间的差异,发现语音输入通常更长、更具有对话性。
概念
人本计算→自然语言接口→信息系统→推荐系统
关键词
推荐系统;自然语言推荐系统;批评;声音;语音;虚拟助手;定性方法;用户研究。
ACM Reference format:
Jie Kang, Kyle Condiff, Shuo Chang, Joseph A. Konstan, Loren Terveen, and F. Maxwell Harper. 2017. Understanding How People Use Natural Language to Ask for Recommendations. In Proceedings of RecSys ’17, Como, Italy, August 27-31, 2017,9 pages.
https://doi.org/10.1145/3109859.3109873
1 简介
“嘿,Netflix,我想看一部动作片……间谍……也许像伯恩的身份……不,是一些不那么暴力、更有智慧的东西……好吧,给我看看《逃离德黑兰》的预告片。”
上面的引用举例说明了一种交互模式,我们相信这种模式将在不久的将来用于推荐系统。在这种情况下,用户与一个设备(例如,一个电视屏幕)进行对话,它将每个语句合并到一个推荐请求中。与用户的喜好和数据库的全局已知属性相匹配,以找到最相关的结果。当结果显示在屏幕上时,用户评估结果(可能有助于澄清他或她在寻找什么,可能是模糊的),并发出后续请求以帮助系统找到更好的结果。”
构建这样一个系统的几个需求已经就绪。例如,来自亚马逊(Amazon)、苹果(Apple)和康卡斯特(Comcast)的机顶盒已经在监听用户发出语音命令或搜索内容。有些甚至允许用户提出推荐,尽管这些功能目前还非常肤浅和有限。(向Apple TV询问“我今晚该看什么”,结果是一个非个性化的内容列表,回答是“我听说这些值得一看”。)在当前的自然语言推荐中缺少的是深层的:理解推荐请求的微妙意图并将其转化为正确结果的能力。
这项研究旨在解决我们知识中的一个基本缺陷:尽管我们可以设计出上面的例子来演示用户请求的细微差别,但我们不知道人们将如何真正地对流自然语言推荐系统说话或输入。因此,我们采用一种新的自然语言推荐——在一个已存在的推荐系统中增加查找功能,对用户与该系统的初次交互进行了研究和报告。通过围绕这些最初的交互进行结构化研究,我们试图了解用户可能拥有的目标、他们可能发出的查询类型,或者他们如何选择表达后续查询来细化结果。要构建对所有查询做出响应的自然语言推荐系统,我们必须开始了解完整的查询范围是什么。
本文的结构如下。我们首先描述相关的工作,重点是对话式推荐系统,信息检索中的用户目标,以及录入文字和语音的预先比较。然后我们描述了一个自然语言推荐的原型和一个我们用来收集推荐请求的实验。我们以构成我们主要贡献的三个部分作为后续:(a)对第一次查询中的推荐寻求目标进行定性分析;(b)对后续请求进行定性分析;(c)对文本和语音模式之间的差异进行定量分析。我们最后讨论了这些发现对自然语言推荐设计者的意义。
作为进一步的贡献,我们将实验数据集公开[14]。在进行这项研究时,我们收集了一个已建立的推荐系统的347个用户的推荐查询、后续查询和调查回复。该数据集是此类数据集中的第一个,可用于种子系统的构建或促进对自然语言推荐系统的后续研究。
2 相关工作
这项工作的一个方向——探索在寻求推荐请求中如何对比语音和文本的问题——建立在对比文本和语音的前期结论之上。最相关的是使用移动搜索引擎日志[9]分析语音查询和输入查询之间的语义和语法差异。这项研究表明,口语查询“更接近于自然语言”,更多时候是作为问题来表达的。关于移动搜索的研究也提供了其他相关的结果,包括语音查询更“自然”、[6]更长、移动搜索类别[13]的频率分析、语音转录错误的分类以及后续查询重构策略[12]。CSCW的早期工作调查了语音和文本在注释文档中的差异,发现语音能够更有效地沟通更高层次的概念,而文本在低层次的注释[3]中表现得更好。最近的研究表明,语音输入和转录的技术障碍正在消失。
令人惊讶的是,关于在推荐系统中使用自然语言(打字或口语)的研究很少。然而,围绕“对话推荐系统”的相关主题进行了大量的工作[21,26],在这个主题中,用户和系统相互参与以迭代地细化查询。例如,研究人员探索了“批评”界面,让用户有机会提出建议,比如“更像项目A,但更便宜”的[15]。然而,这项工作很少涉及自然语言。一个值得注意的例外是Adaptive Place Advisor[8],这是一个早期的自然语言会话推荐系统,用户和推荐系统进行一个基于自然文本的对话,以缩小一组餐馆推荐的范围。该工作后来扩展为一个基于个性化用户模型[28]的口语对话推荐系统。
在本研究中,我们探讨人们如何使用自然语言来表达一个寻求推荐的目标。一些著名的推荐系统论文提出了一套推荐系统应该支持的目标或意图。例如,人工推荐交互(HRI)模型[16]提出了描述以用户为中心的推荐系统视图的术语,并且基于用户目标和任务的层次结构。这项工作明确地认识到用户并不总是能够充分表达他们的信息需求;他们将这种不确定性因素称为“具体性”。评价推荐系统的评价被引用最多的论文之一[10],提出用一套用户任务在推荐系统中对用户目标进行分类;这些目标(例如,“找到好东西”和“只是浏览”)与这里研究的目标相比处于更高的抽象级别。总的来说,推荐系统研究更多地关注于支持这些高级任务,而不是设计或理解底层的、目标驱动的推荐寻找任务[25]。
信息检索(IR)领域对理解低层次的信息搜索目标做出了更多的贡献。一些被高度引用的论文对用户如何与搜索引擎交互进行了分类。也许最有影响力的分类[2]在搜索中提出了三种类型的用户目标:“导航”(到达特定站点)、“信息”(获取信息)和“事务”(定位服务)。Rose和Levinson通过手工编写一组来自AltaVista的1,500个查询,增加了第二层次的分类,并描述了不同用户目标[22]的频率分析,扩展了这种理解。随后的工作使用机器学习方法,在七个搜索数据集[11]中推断出这些用户目标。
3数据收集
为了研究自然语言推荐搜索界面的使用,我们在MovieLens 1中构建了一个基于语音的实验搜索界面,这是一个已建立的电影推荐网站,并要求网站成员使用它并提供反馈。本节描述研究的上下文、收集用户响应的方法以及我们用于后续分析的最终数据集的属性。
3.1实验网站
MovieLens会为其成员提供个性化的电影推荐。用户体验很大程度上是围绕着找到要看的电影的过程来进行的:会员们对他们看过的电影进行评分,然后根据他们看过的电影得到个性化的推荐。MovieLens没有提供任何自然语言搜索功能,尽管该网站有一个突出的“omnisearch”小部件,允许用户搜索标题、标记或人员。
我们为MovieLens添加了一个实验界面,该界面允许用户对系统说话(或录入)。系统以10部电影的列表来响应用户的请求。为了说明这一点,用户可能会说“great car chases”,系统可能会返回“Mad Max: Fury Road”和其他9部有cars、chases和/或greatness的电影。
需要说明的是:为电影构建一个最先进的自然语言查询引擎是不适合这个研究项目的。这样一个系统将需要在系统体系结构的每个级别上进行大量特定领域的投资,从语音识别(不包括演员的名字)到关键字提取(针对电影搜索的特定需求)。我们的目标是建立一个“足够好”的系统,使我们能够回答我们的研究问题——在之前的HCI研究中使用的方法,例如[30]。虽然我们考虑过部署一个“绿野仙踪”推荐系统,但我们希望通过给受试者一个“感觉真实”的系统,并在他们选择的时间和地点使用,来促进生态有效性。为了提高有效性,我们招募了一些实验对象,并承诺要测试一个我们正在考虑将其引入到MovieLens“实验性的特性”。
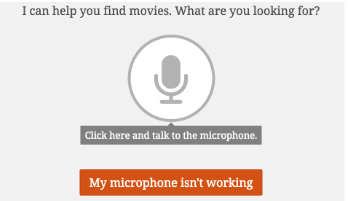
图1:语音输入接口的屏幕截图。
为了构建原型,我们将一些现成的com组件与定制的服务器端搜索逻辑结合在一起。在客户端(web浏览器)方面,我们从Wit.ai (https://wit.ai)集成一个语音输入小部件和语音-文本转换服务接受用户的语音。该接口要求用户单击一个按钮开始并结束收集语音输入的过程。我们立即将音频发送给wit。将音频转换为文本。我们允许用户查看结果,如果翻译结果导致错误,或者麦克风不工作,可以重新尝试或手动编辑结果。
我们将转录后的查询发送到MovieLens服务器,使用自定义搜索逻辑导出最相关的电影列表。我们的过程首先使用AlchemyAPI (http://www.alchemyapi.com)从查询字符串中提取关键字,然后搜索具有标题、演员、导演、流派或与这些已删除关键字匹配的标签的电影。匹配项更多的电影获得更高的分数。
请参阅下面的数据收集结果部分,对推荐结果的质量进行实验评估。
3.2受试者招募、条件、任务
为了评估用户查询行为,我们通过电子邮件招募了MovieLens用户。为了让用户对MovieLens有最少的了解,我们只给那些在前六个月登录过并且已经给足够的电影评分(15)的用户发了邮件。点击邮件链接的用户登录到MovieLens,并显示了一份实验同意书;受试者有机会立即退出或在任何时候停止。这个实验得到了我们研究机构IRB的批准。
我们只包括两个实验环境:语音或打字。在语音环境下的用户通过在他们的计算机或设备上发言来提交他们的查询,而在打字环境下的用户通过输入一个输入框来提交他们的查询。我们的分配不是随机的,因为有些用户的电脑上没有一个可用的微型电话。因此,我们的分配基于图2中可视化的策略。不能使用麦克风的受试者进入打字状态。能够使用麦克风的受试者被随机分配到语音环境(75%的机会)或打字环境(25%的机会)。有可能使用可用麦克风的用户与不使用可用麦克风的用户不同(例如,他们可能更精通技术),下面我们将分析这种潜在的偏见。
我们要求受试者依次完成几个任务,如图3所示。所有的受试者在研究开始时都要与基于打字或口语的自然语言输入界面进行交互,并提示“I can help you find movies.你在找什么?”(见图1)。一旦受试者提交了一个查询,系统就会返回10个搜索结果,并进行一个简短的调查询问,“这些结果与你所寻找的结果匹配程度”,要求受试者(在5星“非常差”到“极好的”范围)进行打分。打了差和非常差的被试者被要求解释如何使用自由的文本输入来改进结果。将结果评为“普通”或更好的受试者被要求表达一个后续查询(界面提示:“我可以改进这些结果。”多告诉我你想要什么。最后,所有的研究对象都被调查了几个因素,包括他们希望这个功能在MovieLens中是如何工作的,以及他们在其他语音识别方面的经验。我们在下面的结果中陈述了个别调查问题的具体措辞。
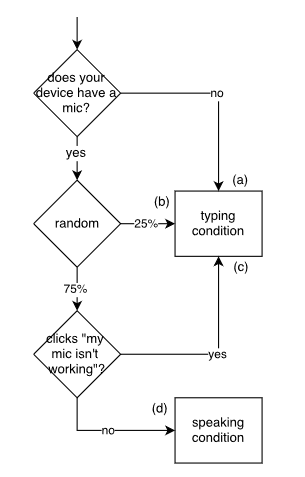
图2:将受试者分配给口语或打字条件的方法。我们首先问受试者是否有工作麦克风。说“不”的用户被输入到文本录入环境(a)中,而说“是”的用户被随机分配到文本输入(b)或语音输入。被分配到语音环境的用户可以点击“我的麦克风坏了”回到输入条件(c),或者使用语音接口(d)。
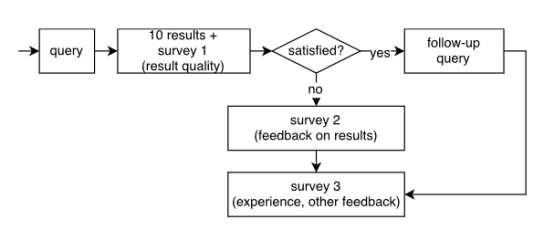
图3:描述受试者实验任务的流程图。

表1:每个数据集中的受试者数量(总数和语音环境下)。
3.3数据收集结果
我们在2016年5月12日给972位MovieLens成员发了邮件,并收集了截至5月24日的数据;544人同意参加(5.5%)。我们每个主题最多收集一个回复。对于每个主题,我们认为它们的输入是“有效的”,如果它是非空的,而不是一个测试或无意义的查询(我们的编码方法描述如下)。例如,我们排除了用户查询“测试一二三测试一二三”(测试)、“xx”(废话)和“blah blah blah blah blah blah blah blah”(废话)。此外,当用户使用文本区域完全重写了转录后的语音时我们丢弃了任何来自于语音条件的查询,因为不清楚这些查询是代表语音还是文本输入。因此,这就排除了所有收到来自wit.ai的空转录的用户。
在这些过滤步骤之后,我们的数据集包含347个有效查询,我们将其标记为输入示例。这些查询一般比较短,字符数(中位数14,平均18.0)和单词数(中位数2,平均3.1)。195/347(56.4%)受试者报告有一个工作麦克风,只有95/347(27.4%)处于说话状态。考虑到75%的随机分配率,这个数字远低于期望值(~146);这是解释为两个因素:(a)40用户在尝试了麦克风后点击“我的麦克风不工作”按钮,手动切换到文本输入条件,和(b)较多的用户在语音环境下收到一个或多个低质量的转录结果后放弃(不点击“发送”)。
我们进一步将受试者分成两个额外的数据集来分析调查响应和后续查询。224/347(64.6%)的受试者提供了完整的调查问卷,我们将其标注为调查样本。151/347(43.5%)的受试者提供了一个有效的后续查询,我们给后续的输入样本贴上标签。请参阅表1以了解每个数据集的大小。
总的来说,被试倾向于将电影搜索结果的质量评价为“公平”——156/224(69.6%)的被试报告结果与他们所期望的“公平”或“更好”匹配,而其他被试报告“非常糟糕”(12.9%)或“糟糕”(17.4%)。
4第一次查询
我们将输入样本中的查询编码为多种方式,以方便对转录用户查询的数据集进行频率分析和其他形式的定量分析。一般情况下,我们采用[18]中描述的归纳开放编码方法,基于扎根理论方法[1]通过对持续比较[7]得出的开放式评论进行分析。具体地说,参与这个项目的四名研究人员一起阅读用户查询的数据集,分配新的代码或优化旧的代码。我们的目标是用对我们的内容领域的推荐系统设计者有用的术语来描述查询。
一旦我们开发出一个稳定的代码层次结构,两位研究人员分别编写了187个随机响应来度量一致性并帮助校准他们的编码实践(Cohen 's kappa跨越了187个响应中的14个代码:avg=0.87;最小值= 0.72;max = 1.0)。为了确定在这个分析中使用的最终编码,两位研究人员分别对所有的回答进行编码,然后讨论并解决分歧。
4.1推荐标准的目标
受到对web分类搜索的经典工作的启发[2,22],我们试图理解用户与推荐系统交互的潜在目标。就像搜索引擎在网络上搜索一样,推荐系统中基于自然语言的交互是实现目标的一种手段——在这种情况下,可以找到优秀的电影来观看,或者浏览他们已经感兴趣的电影的信息。为了达到这个目标用户以不同的方式表达他们的查询。
与[22]一样,我们的归纳编码方法把用户目标构建成一个层次结构,如表2所示。我们开发了三个顶级目标:客观、主观和导航。
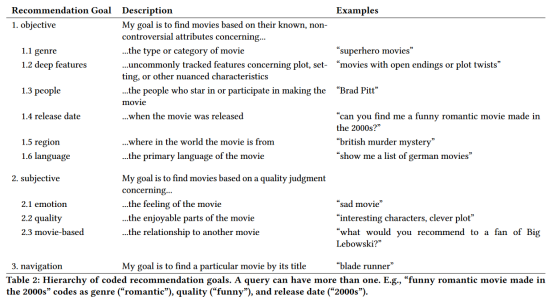
我们将目标定义为可以无歧义地回答的请求。这些目标通过指定类型、演员或发布日期等属性来筛选电影空间。这些目标通常很容易通过电影网站上常见的信息来回答。然而,我们发现了许多客观目标的例子,这些目标不能用一个典型的电影信息数据库轻易回答。我们将这些目标标记为寻求“深层特性”,这表明用户希望通过微妙的或特定的标准来过滤电影。例如 ,“apocalypse special effects”和“a movie about berlin wall”就是包含深层特性的查询。
我们将主观目标定义为包含判断、不确定性和/或个性化的请求。虽然客观目标往往像布尔过滤器(一部电影要么由布拉德•皮特主演,要么不是),但主观目标更符合评分或排序算法。例如,“有趣的角色”查询可能适用于许多电影,一些电影比另外一些更符合。回答主观的问题——就像客观的深层特性一样——是很困难的,因为元数据数据库和推荐系统都无法追踪一部电影有多少“巧妙的情节”或“悲伤的”。
我们将主观目标分为三种常见的子类型。情感请求倾向于指定电影在观众心中唤起的一种特殊感觉,例如“欢快的喜剧”。高质量的要求要么是明确地想要好的/最好的电影(例如,“一些好的反乌托邦科幻电影会很好”),要么是明确地指出电影的哪些方面让它好(例如,“经典科幻电影”)。最后,基于电影的要求寻找相关的电影,例如,“类似于低俗小说”。我们认为基于电影的请求是主观的而不是客观的,因为没有客观的和普遍持有的度量来确定任何两部电影[5]之间的相似性。
导航目标是这三个目标中最简单的一个——用户希望看到一个或多个特定的电影,因此他们声明了部分或全部的标题。我们数据集中的一些例子是“社交网络”(匹配一部电影)和“星球大战”(匹配一部系列)。
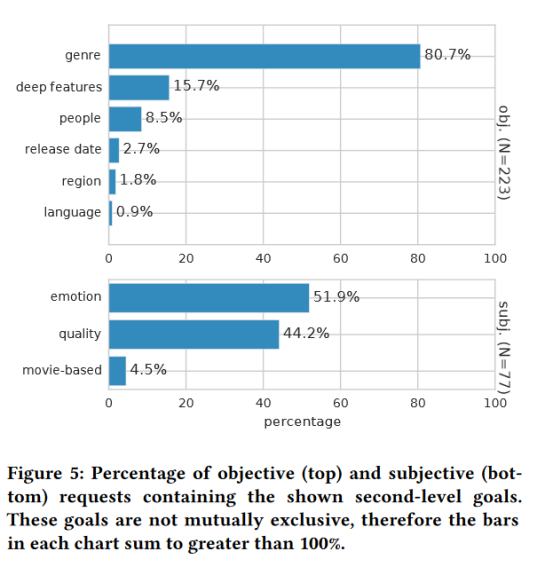
与Rose和Levinson[22]不同,我们的目标层次结构并不是每个查询都具有排他性;通常情况下,一个请求包含几个不同的目标。用户通常会寻求与这些多个目标交叉。例如,查询“大团圆结局的剧情片”结合了两个客观目标(“剧情”类型、“大团圆结局”深层特征);用户希望找到一部具备所有这些品质的电影。我们只用观察到两个查询(2/343 = 0.6%)使用了“or”这个词,其中只有一个查询似乎是请求多个不同目标的结合(“开放式结尾或情节转折的电影”)。图4显示了顶级目标之间的重叠,图5显示了数据中二级目标的频率。

4.2响应的其他编码特性。
我们对用户响应的其他一些属性进行编码,以提高我们对自然语言查询的理解。编码方法,包括测量评分者间置信度的方法,与上述方法相同。
会话。有些查询的措辞好像用户在与人交谈;我们将这些查询编码为会话查询。例如,“我在找一部硬邦邦的科幻电影”和“找到一部像《美丽心灵的永恒阳光》这样的电影”。这些措辞表明愿意与软件代理进行对话。我们发现数据集中24.8%的查询是对话式的。
修饰词的数量。查询复杂度的一个度量指标是查询包含的修饰词的数量,其中每个修饰符用于过滤或重新排序结果。例如,“我在寻找一部不悲伤的电影”只有一个修饰词(“不悲伤”),而“biographic dramas”有两个修饰词(“biographic ”,“dramas”)。我们之前对推荐目标的编码与这个度量不同,因为一个请求可能有相同类型目标的多个组成部分(例如,“间谍惊悚片”和“冒险和戏剧”每个都包含两个类型目标)。在我们的数据集中,69.7%的查询只有一个修饰符,23.9%的查询有两个修饰符,6.1%有三个,0.3%有四个(我们数据中的最大值)。
推荐。我们数据集中的一些查询明确地寻找被推荐的电影。一些例子是“一部好电影”和“我正在寻找最好的科幻恐怖电影”。对比与大多数的查询,这些查询被推荐的电影的需求是隐式的(“寻找恐怖电影”),不确定的(“警察兄弟电影”这个流派可能寻求这个类型中最好的电影,也可能是需要一个全面的展示),或者可能匹配错误(导航查询像“28天后”是在找一部电影,而不是一个列表)。在我们的数据集中,只有4.4%的查询是明确的。
5跟踪查询
被试对他们的搜索结果进行“公平”或“更好”的评价后,会被要求用提示语表达一个后续的查询:“我可以改进这些结果。告诉我你想要什么。”这个提示符旨在引出第二个问题,这次是由10个搜索结果提供的。在本节中,我们将定性地分析完成此步骤的受试者的查询(后续输入示例)。
与被试的第一个查询不同,在第一个查询中他们的目标通常是明确的和可识别的,而后续查询对于它们的目标通常是不明确的。例如,如果一个被试的第一个查询是“科幻小说”,而后续的查询是“恐怖片”,那么这个被试可能是指定一个额外的类型过滤器,也可能正在启动一个新的搜索。
由于这种模糊性,在本分析中我们采用定性的方法来识别主题,使用重复单词和上下文中的关键词方法[24]。两个编码人员遍历整个数据集,使用这些方法识别主题。然后编码人员讨论发现的主题,集成它们,并从数据集中提取每个主题的高质量示例。
在考虑这些发现时,重要的是要认识到,某些被试的初始查询目标比其他人更容易。建议的质量很可能会影响被试的后续行为,但我们这里不研究这种联系。
5.1完善
被试通常使用后续查询将初始查询细化为更具体的结果(N= 62,41.1%)。这些受试者假设系统记住了他们的初始查询,并指定了他们希望推荐系统考虑的其他条件。
进一步完善与约束。许多优化查询表明,被试仍然对初始查询感兴趣,并希望进一步限制搜索空间的范围。下面有几个例子(我们用1表示初始查询,用2表示后续查询):
1: 一部悬疑结局的神秘戏剧
2: 过去几年的事情
1: 一部有幽默感的动作片
2: 多情景喜剧少荒谬
完善与澄清。其他细化查询反映了对初始结果的失望。这些受试者试图通过提供更多信息来帮助数字助理:
1: 恐怖
2: 更真实的恐怖而不是戏剧/惊悚
1: 我在找一幅伟大的艺术作品。
2: 这应该是一部独立电影
5.2 重新阐述
其他受试者使用后续提示重新表达他们的初始查询(N=34, 22.5%)。这些被试似乎仍然对原始查询感兴趣,但希望完全重新声明查询以改进建议。这些主题不假设推荐系统记住他们最后的查询,并且通常重用原始语言的一部分。
用更进一步的约束条件重新阐述。与细化查询一样,一些被试试图通过重新阐述来进一步缩小结果集:
1: 我在找一部浪漫喜剧
2: 我想要一部在2000年之后创作的浪漫喜剧。
1: 我在找时光旅行的电影
2: 我在找一部我以前没看过的穿越电影
用澄清的方式来重新阐述。其他受试者重新制定查询,以促进系统取得更好的结果:
1: 一部结局美满的浪漫喜剧
2: 两人关系紧张但结局圆满的浪漫喜剧
1: 28天后,
2: 像《28天后》这样的电影
5.3重新开始
我们在后续查询中发现的第三个主要主题是,被试希望启动一个新的查询(N= 55,36.4%),尽管实验提示符说“告诉我更多关于您想要什么”(重点不在界面中)。这些受试者可能正在试验系统,或者可能意识到他们的第一个查询根本不是他们要找的东西:
1: 疯狂的麦克斯愤怒之路
2: 发现海鲂
1: 红色小提琴
2: 新纪录片
6 语音vs打字。
上述分析结合了两种形式的推荐查询:语音和打字。在本节中,我们讨论了这两种模式之间查询的差异。
6.1主观偏向和群体选择
在我们的实验中,我们将用户分配到语音环境或文字环境。但是,我们的分配过程是非随机的,因为我们希望包括没有工作麦克风的用户。因此,在不同分配方案的用户之间的数据集存在潜在的行为偏差。例如,不使用麦克风的用户更有可能在台式电脑上工作(而不是便携式设备),或者他们在与语音激活的界面进行整体交互时经验更少。
见表3,对每个分配类别的用户数量进行总结;分配过程如图2所示。达到打字条件有三条路径,达到口语条件只有一条路径。
我们在不同的分配类别中发现了用户之间的一些差异,这影响了我们后续的分析。我们用一些细节来描述这些发现,因为它们揭示了自我报告的经验和行为模式的几个有趣的差异。我们通过对分类数据使用似然比卡方检验和对数值数据使用秩和检验来测试差异。
没有麦克风的受试者自述较少使用语音助手。我们的调查包含了这样一个问题:“你多久使用一次语音助手(比如谷歌Now、Siri等)?”“从不”(0)、“很少”(1)、“每月几次”(2)、“每周几次”(3)、“每天一次”(4)、“每天多次”(5)。然而,没有麦克风的受试者回答较低的次数(N=256, p < 0.001)。例如,50%的用户以“从不”作为回答,而同样的回答其他三组中只有21%-25%。
文本输入条件的三个类别之间存在明显的行为差异。这三组被试(a-c)有几种相似的表现方式:它们输入的查询长度大致相同(p=0.748),导航(p=0.839)和客观(p=0.387)的比例相近。但是,我们发现主观性特征(打字-有麦克=10.0%,打字-麦克不工作=25.0%,打字-无麦克=28.9%;p=0.008)和会话查询(打字-有麦克= 6.7%,打字-麦克不工作=32.5%,打字-无麦克=19.1%;p = 0.003)的比例存在差异。打字-麦克不工作组的受试者也需要更长的时间(以秒为单位:打字-有麦克=17.5,打字-麦克不工作=42,打字-无麦克c=20, p < 0.001),尽管这可以用判定麦克风失效并切换到打字状态的额外时间来解释。
由于赋值类别之间的差异,我们将此分析限制在打字-随机(N=60)和语音-随机(N=95)的受试者。这些组被随机分配,他们报告了类似的语音助理使用经验(受试者报告3或更高的比例:说-随机=29.2%,打字-随机=31.8%;p = 0.386)。
6.2 结果
与推荐系统使用语音交互会导致比打字更长的查询(字符中位数:Speaking =19, typing=12.5;p < 0.001)。与此相关,我们发现处于语音状态的受试者更有可能提出会话请求(比例会话查询:speaking=40.0%, typing=4.0%;p < 0.001)。
使用语音与推荐系统交互需要更多的时间(以秒为单位的中位数:口语=39,打字=17.5;p < 0.001)。这种影响可能是由于花费了时间来纠正转录错误;如果有一个完美的语音识别系统,这种影响可能会消失。
语音导致更多具有客观深度特征的查询(语音=14.7%,打字=5.0%);和更主观的基于电影的查询(语音=5.3%,打字=0.0%;p = 0.025)。其他二级类型特征在两组之间具有相似的比率,并且在我们的数据集中没有显示统计上的显著差异。此外,我们也没有发现两组查询中有统计学上的显著差异,分别是客观查询(语音=67.4%,打字=70%)、主观查询(语音=17.9%,打字=10.0%)和导航查询(语音=22.1%,打字=23.3%)。
7讨论
在这项工作中,我们使用一个电影推荐界面原型来了解更多用户如何构造推荐搜索查询。我们的工作展示了用户如何处理推荐和搜索的相似性和差异性。我们的推荐目标分类包括“导航”查询的概念,该概念是为理解搜索行为而开发的[2,11,27]。然而,由于推荐通常是单站点的,与web搜索不同,信息检索文献中的其他搜索目标(“信息性”和“事务性”)不太适用。相反,我们选择用“客观的”和“主观的”标准来定义用户对内容进行过滤和优先排序的特征。主观的查询,特别是,很有趣,因为它们过滤的工作很差,但是提供了一个重要的信号来指导排名。这些差异突出了将当前一代搜索技术应用于自然语言推荐问题的缺点,并指出了推荐系统研究人员在开发下一代系统时必须克服的一些关键挑战。
我们推荐的分类法的几个显著特征,即“客观深度特征”和“主观”特征,不容易被传统的推荐算法处理。深层特性(如“情节转折”)是客观的,但是超出了通常实体元数据被索引的范围。主观特征(如“伟大的表演”)更加困难,因为它们塑造了观点而不是客观的事实。在我们的实验中,15%的查询包含“深层特征”,而22%包含强调重要性“主观”的特征。一个可能的方向是使用文本挖掘算法——比如标签基因组[29]或word2vec词向量[17]——对非结构化文本(如评论)进行挖掘。然而,这些复杂特性的突出显示了未来当系统将“推荐项目”的概念与用户对“不暴力”或“伟大表演”等方面的上下文搜索结合在一起时的迷人之处。
虽然未来可能会带来近乎完美的语音识别,但目前提供的工具通常会导致转录错误。为了便于实验,增加实验对象的数量,避免诸如此类的转录错误,研究人员可能希望利用打字作为说话的替代手段来研究自然语言界面。在这项研究中,我们发现了这两种模式之间的一些关键区别:语音会导致更长的对话,更有可能包含客观的深层特征(“情节扭曲”)和主观的电影特征(“像《终结者》这样的电影”)。因此,当文本作为语音的替代时,会产生不同的输入模式,这可能会在某些情况下影响研究结果。
7.1限制及未来工作
我们的研究是基于寻求电影推荐的受试者的行为,因此我们不清楚这里介绍的哪些发现将推广到其他领域。我们认为我们的一些高级发现已经超出了电影领域。例如,不同的推荐者可能会发现用户表达了客观的特征来过滤结果以及主观的特征来区分结果的优先级。此外,用户在说话时的查询比输入时的查询更具有对话性这一发现,我们没有找到领域相关性。未来还需要比较我们目前的发现与其他领域的自然语言推荐-查询行为来确认是否是领域相关。
我们不能确定我们的小样本(N=347)是否代表了大量的电影推荐搜索者。在我们的实验场地之外添加实验对象——或者简单地从我们的网站上扩展实验对象——可能会改变我们的频率分析的结果,甚至可能改变我们的定性编码过程的结果。考虑到在这个主题上之前工作的不足,我们的目标是开发一种对用户行为的最初的、广泛的理解,并通过一个小样本来提供自然语言推荐。未来的工作是将这项研究扩展到跨站点的许多用户,深入研究这些结果,以进一步了解诸如推荐搜索词汇或通过机器学习的方法来预测推荐搜索目标等主题。
从根本上说,尽管我们希望探索一个“开放式”的推荐提示符,但我们在内部测试中发现,我们不能简单地使用google风格的界面(只是一个未标记的框和一个按钮),因为用户不理解它。因此,我们设计了一个“虚拟助手”,比如Alexa或Cortana,说明“我可以帮你找到电影。你在找什么?”这个提示以一种不确定的方式塑造了反应的模式。未来的工作可能会探究不同的提示——比如Facebook上的电影推荐聊天机器人“And Chill”(andchill.io)——是如何影响用户请求的。
8结论
在本文中,我们描述了一个推荐系统的自然语言接口原型,它会提示用户使用开放式的推荐请求。我们研究用户与系统的第一次交互,以鼓励用户表达他们想要的内容,而不是他们已知的在特定系统中才能工作的查询方式。
我们对推荐系统的理解做出了一些贡献。据我们所知,这是第一个在自然语言界面中描述用户推荐请求的工作。为了理解这些请求,我们提供了用户推荐目标的分类;最高层次的目标是客观的、主观的和导航的。我们还描述了一个后续请求的数据集,发现当人们使用第二个输入以“评论”风格细化他们的初始请求时,许多其他人会重新制定他们的查询或重新开始。我们研究了文本模式和语音模式之间的差异,发现语音引导用户使用更长的、更复杂的查询,具有更客观的“深层特征”和更主观的“基于电影的”特征。
我们收集了347个用户的第一次查询、后续查询和调查响应的数据集,并作为开放数据集[14]发布;我们希望这一数据集将对系统建设者和研究人员在开发新一代的推荐技术方面提供有用的补充。
9 感谢
This material is based on work supported by the National Science Foundation under grants IIS-0964695, IIS-1017697, IIS-1111201, IIS- 1210863, and IIS-1218826, and by a grant from Google.
转载请注明出处:https://www.cnblogs.com/kyxfx/articles/9188759.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号