

论文阅读(二):Packing Input Frame Context in Next-Frame Prediction Models for Video Generation
前言
前几天看到了lvmin在arxiv上发表的新作Packing Input Frame Context in Next-Frame Prediction Models for Video Generation,采用next-frame-section prediction的形式生成视频,能够生成一分钟的视频,效果还不错。因此,抽时间阅读了论文与代码,与大家分享。
Framework
next-frame-section prediction
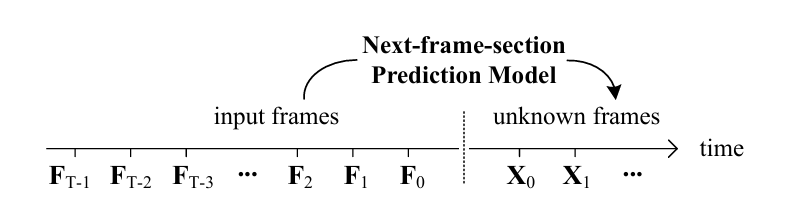
如上图所示,next frame section prediction生成视频的方式与LLM中next-token prediction的方式类似:在生成\(T\)帧的前提下,继续生成后续\(S\)帧。即,输入一段已经生成的视频,\(F \in \mathbb{R}^{T \times C \times H \times W}\),生成后续视频\(X \in \mathbb{R}^{S \times C \times H \times W}\)。假设单帧token的长度为\(L_{f}\),那么输入到网络中的视频token数为\(L_{f}(S+T)\)。由于attention的计算复杂度和token数成平方关系,因此随着生成视频长度\(T\)的增加,计算复杂度显著上升,限制了长视频的生成。
FramePack
正如上文所述,对长视频采用full attention是不现实的,因此,本文提出framepack方法限制参考的token长度。framepack对不同位置的视频采用不同压缩倍率压缩,进一步消减视频的冗余性。对于视频的第\(i\)帧而言,第附近的帧往往与其更加相似,因此采取更低的压缩率;与其较远的帧则采用更高的压缩率。此时,第\(i\)帧的token长度为
视频的总token数为
假设\(\lambda_{i}\)服从指数分布,即\(\lambda_{i}=\lambda^{i}\),此时,当$T \rightarrow +\infty $时
因此,即使随着视频长度的增加,视频的总token数仍然存在一个上界。

图(a)给出了\(\lambda=2\)时的framepack形式。图(b)给出了framepack的另一种变体,该变体能够实现更加紧凑的压缩。
Anti-drifting Sampling
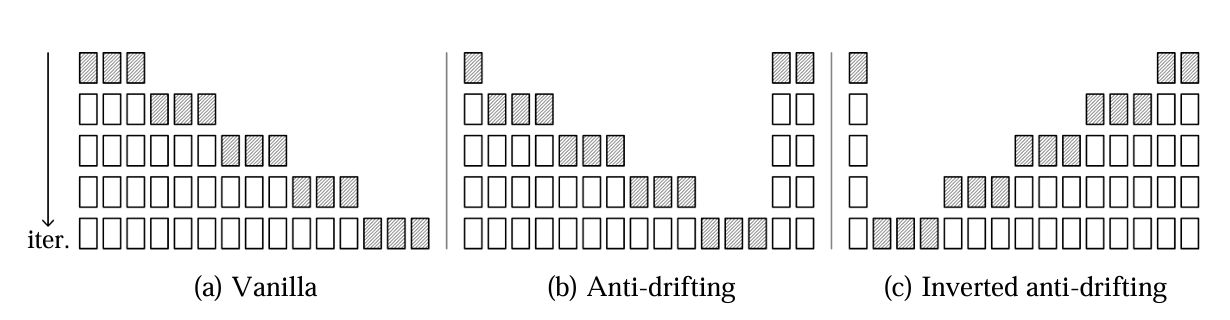
图(a)给出了传统的自回归生成范式,随着序列的生成,模型会出现漂移现象,降低生成帧质量。作者认为,首先生成尾帧能够缓解这一现象。较先生成的帧的误差累计相对较小,能够缓解漂移现象,该过程对应于图(b)。此外,作者还提出了anti-drifting采样方式,将视频由后向前生成,对应于图(c)。对于I2V(Image-to-video)任务,首帧质量较高,因此,由后向前生成视频时,靠近首帧的帧虽较晚生成但受首帧的影响更大,进一步减缓了漂移现象。
I2V Pipeline
由于原论文的训练代码还未放出,只放出了基于HunyuanVideo的I2V infer框架,因此,在此只梳理了infer的框架。

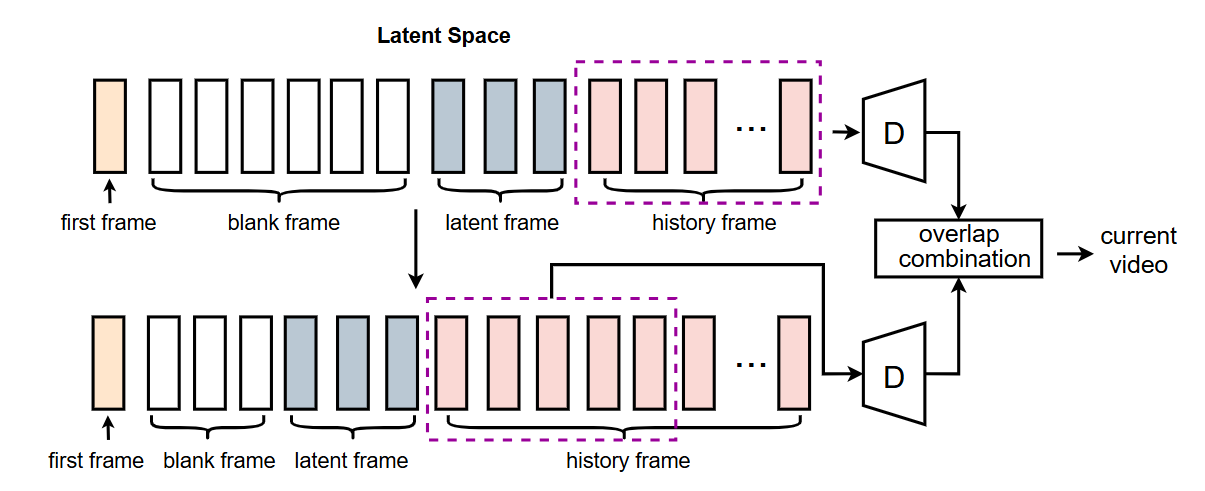
将待生成的视频在隐空间中分为四部分:
first frame:首帧
blank frame:后续待生成的视频帧
lantent frame:当前待生成的视频帧
history frame:已生成的视频帧(全零初始化)
- framepacking获得video token
![]()

其中,\(p_{1}\)表示HunyuanVideo中的原始patchify操作,\(kernelsize=(1, 2, 2)\),\(p_{2}\)和\(p_{4}\)对应的\(kernelsize\)分别为\((2, 4, 4)\)和\((4, 8, 8)\)。对\(p_{1}\)进行插值以获得\(p_{2}\)与\(p_{4}\)的初始值。计算RoPE的方法与进行patchify的方法类似,在此省略。
-
去噪过程
![]()
-
单次迭代结果(生成一段视频)
![]()

后记
笔者认为,此文章还给出了附加的价值。第一个问题是,当目标是生成2s的视频时,采用framepack串行生成两次1s的视频和直接生成2s的视频,哪一个方法更好。由于计算量和token数成平方关系,大概率生成两个1s的视频比直接生成一个2s的视频耗时更少。第二个问题是,当token数减少时,扩散步数能不能相应减少,例如,生成2s视频所需要的扩散步数,是否要多于生成相同质量的1s视频所需要的扩散步数。如果token数减少能够使扩散步数也相应减少,那么framepack的方式能够进一步减少时间。
此外,笔者对于framepack仍然存在一些疑惑。framepack能否生成与首帧完全不相似的尾帧。比如,首帧为屋子中有一个人,所给的prompt为这个人走出了镜头。至少在笔者的测试下,framepack不能够处理这样的任务。
参考
原始论文:https://arxiv.org/abs/2504.12626
github仓库:https://github.com/lllyasviel/FramePack/tree/main

 浙公网安备 33010602011771号
浙公网安备 33010602011771号