从 0 到 1 学爬虫:用 Python 爬取网页数据指南一(附实战案例)
引言
在我们的生活中会遇到很多的数据,或者是自己想看的照片,或者是电影评分,一些商品比较。这个时候,如果我们手动收集需要消耗很多的时间,精力。此时爬虫就在数据收集、分析中体现了其使用价值。而本文则简要的叙述关于爬虫的相关知识。
一、爬虫入门:核心库与基础原理
1.1 基础工具的了解
对于爬虫,如同网络安全和网络工程一样,抓包是一项必不可少的工作,但是我们没有类似网络安全那样使用BP或者是网络工程那般使用wireshark,通常情况下利用浏览器自带的抓包即可(这里推荐使用google或者是微软)接下来便会介绍一下工具的使用,首先打开F12
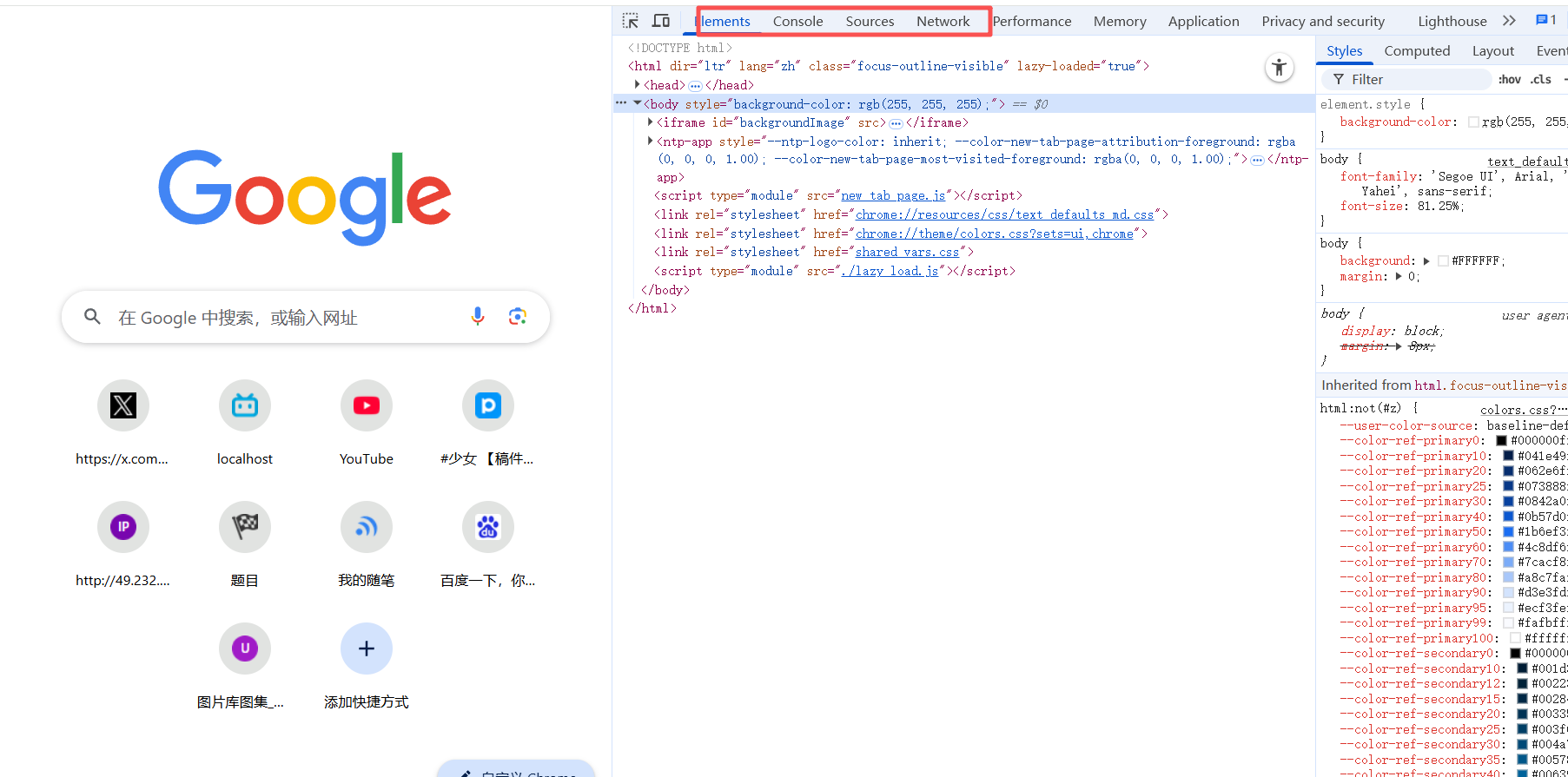
如图中圈出的所示,我们主要使用的是Elements、Console、Sources以及Network。
对于Elements大家会误认为是源代码,实则不然,如果想查看源代码,则应该使用鼠标右键的检查代码。如图所示:
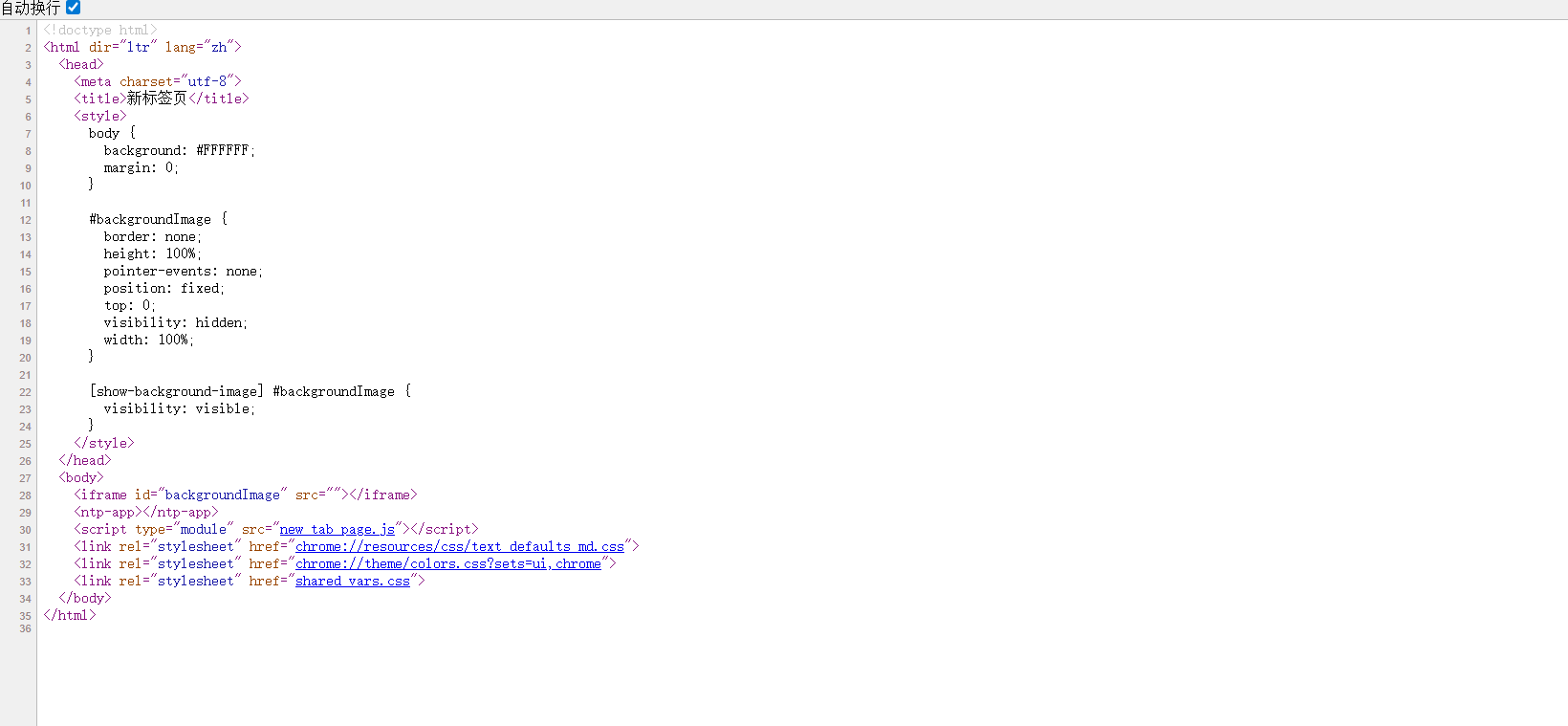
那就有人会问:这两个有什么区别呢?拿考试举例子来说,查看源代码,相当于老师给出的卷子的标准答案;而Elements是由学霸自己写出的不是很简洁的答案。可是,那是不是意味着Elements是没有用的呢?答案是错误的,在一个只有代码的页面里,我们想要找到我们所需要的标签是困难的,有时候便会须有借助Elements去定位我们所需要的标签。
console是一个用来调试JavaScript的工作台,在爬虫中用处不是很大,下文如有需要会单独去说。
Sources是存放了源代码的文件夹,可以查看其文件。
Network则是我们用的最多的,要注意打开这些选项,当刷新后会出现所有传输的数据包,有时候我们想要的便在这里。
1.2 基础库urllib
引入库 urllib.request。即
from urllib.request import urlopen接下来以百度为例,在urllib库中引用urlopen方法:
url = "http://www.baidu.com" # 定义要访问的url
resp = urlopen(url) # 打开url
#print(resp.read().decode("utf-8")) # 读取响应内容并解码为utf-8,此时拿到的是源代码
with open("mybaidu.html",mode="w",encoding="utf-8") as f: # 打开文件,指定编码为utf-8
f.write(resp.read().decode("utf-8")) # 写入文件首先我们需要给出一个url,告诉爬虫我们要去哪里爬,所以这个时候就要利用urlopen()方法进行获取url。
而resp.read()获取的其实是字节,所以需要通过解码的形式,获取到我们能看懂的源代码。但是解码的码源对于不同网站是不一样的,所以此时需要用CTRL+F搜索“charset”这个单词来查找发现使用的码源,百度用的是“UTF-8”.如图:

图一是未使用解码的效果,图二是使用了解码的效果。
到这里我们并没有将其保存,所以为了将其保存,我们使用了函数即“with open() as”
python文件读写,以后就用with open 语句。
with open("filename.txt",'r') as f:
content = f.read(f) #文件的读操作其中意思为保存文件类型为txt,以只读的方式打开文件。
with open("data.txt","w") as f:
content = f.write("hello world") #文件的写操作其中意思为保存文件类型为txt,以只用于写入的方式打开文件
故,对于我们想要保存的源代码,则需要用到如此语句
with open("mybaidu.html",mode="w",encoding="utf-8") as f:
f.write(resp.read().decode("utf-8"))该代码段的意思是,将url的页面用utf-8的形式解码写入到mybaidu.html中并保存。
但是需要注意的是:urllib.requests库是自带的,并不好用,所以引入新的库requests。该库需要下载,在终端输入pip install requests进行下载。下载完成后便可正常使用。
import requests
url = "http://www.baidu.com"
resp = requests.get(url) #发送get请求体
resp.encoding = "utf-8"
print(resp.txt) #拿到页面源代码1.3 POST与GET请求
1.3.1 POST请求
以百度翻译为例
import requests
url = "https://fanyi.baidu.com/sug" #对于post无论url有多长都需要拿过来
data ={
"kw":input("请输入一个单词:")
}
rep = requests.post(url,data=data) #data为post请求的数据包参数
print(rep.text) #拿到的是文本字符串
print(rep.json()['data']) #此时拿到的直接是json数据对于data部分,有人可能会问,这是在哪里呢?我们在百度翻译里输入dog(最后使用中文输入)
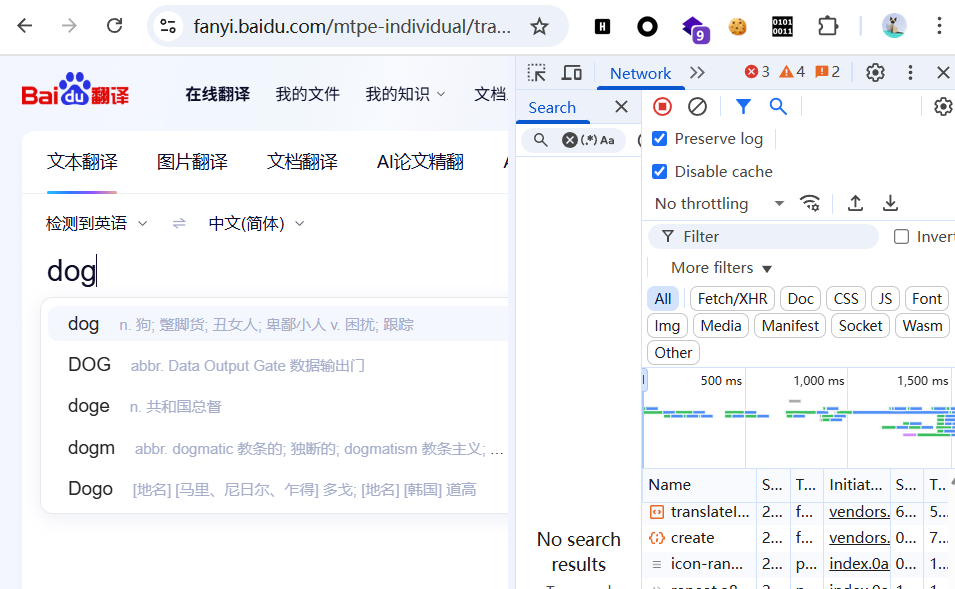
抓包后,我们可以在form data中找到相应的数据,如下图所示:
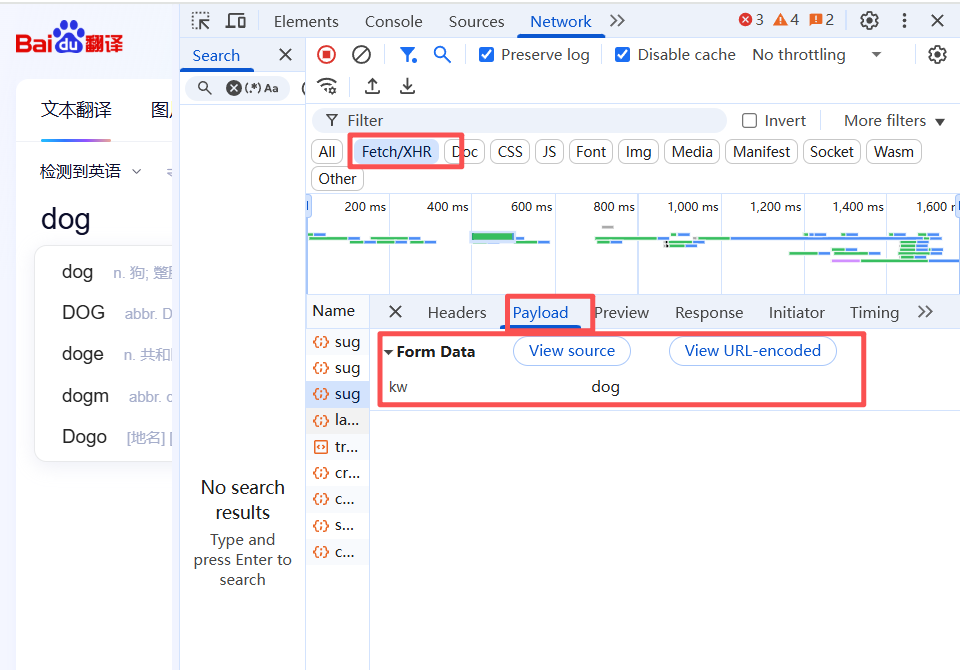
1.3.2 GET请求
以豆瓣为例:
import requests
#get请求只需要提取问号前面的url
url = "https://movie.douban.com/j/chart/top_list"
data = {
"type":"13",
"interval_id":"100:90",
"action":"",
"start" :"0",
"limit":"20"
}
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"
}
resp = requests.get(url,params=data,headers=headers) #处理get请求数据包为params
print(resp.text)
print(resp.request.url) #查看url对于data部分,在Get请求中为Query String Parameters,与POST请求在同一个位置,需要注意的是GET请求只需要提取问号前面的URL,而非整个的URL。
二、网页解析:从 HTML 中提取数据
2.1 HTML与CSS
2.1.1 HTML基础语法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>标题</title>
</head>
<body>
</body>
</html>
<!--
html基本语法:
1.<标签名 属性="属性值">被标记的内容</标签名>
2.<标签名 属性="属性值" />
2.1.2 CSS基础语法
完整的 CSS 代码由 “选择器” 和 “声明块” 组成,但爬虫场景下,我们只需要 “选择器”
| 需求场景 | 推荐选择器 | 示例 |
|---|---|---|
| 定位唯一元素 | ID 选择器(#id) | #user-avatar → 定位用户头像 |
| 定位一类元素(如商品列表) | 类选择器(.class) | .goods-item → 定位所有商品项 |
| 定位嵌套元素(如列表里的链接) | 后代选择器(空格) | .goods-list a → 定位商品列表里的所有链接 |
| 定位带特定属性的元素(如图片) | 属性选择器([属性]) | img[src] → 定位所有图片(带 src 属性的 img 标签) |
2.2 正则表达式
2.2.1 元字符
. 匹配换行以外的任意字符,在python的re模块中的是一个坑
\w 匹配字母或数字或下划线
\d 匹配的是数字
\n 匹配一个换行符
\t 匹配一个制表符
^ 匹配字符串的开头
$ 匹配字符串的结尾
\W 匹配非字母或数字或下划线
\D 匹配非数字
\S 匹配非空白符
a|b 匹配字符串a或字符串b
() 匹配括号内的表达式,也表示一个组
[] 匹配字符组中的字符2.2.2 量词
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n此或更多次
{n,m} 重复n到m次2.2.3 惰性匹配和贪婪匹配
.* 贪婪匹配(尽可能多的拿到结果,匹配到最后一个出现在*后的)
.*? 惰性匹配(尽可能少的拿到结果,匹配到第一个出现在*后的)2.2.4 以爬取豆瓣top250为例
思路:我们需要先拿到页面源代码(仔细观察其url每个页面就是对于其实值加5所产生的等差数列),再用正则去爬取数据,之后将爬取的数据保存下来。
#思路:先拿到页面源代码,再用正则提取数据,保存数据
import requests
import re
#csv文件数据与数据之间用问号隔开
f = open("top250.csv",mode="w",encoding="utf-8")
for i in range(0,250,25):
data = i
url = f"https://movie.douban.com/top250?start={data}"
header = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"
}
resp = requests.get(url,headers = header)
content = resp.text
#编写正则
# re.S可以让正则中的.可以匹配换行符
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p>.*?导演: (?P<daoyan>.*?) .*?主演:(?P<zhuyan>.*?)<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<pingfen>.*?)</span>.*?<span>(?P<num>.*?)人评价</span>',re.S)
result = obj.finditer(content)
for item in result:
name = item.group("name")
daoyan = item.group("daoyan")
zhuyan = item.group("zhuyan")
year = item.group("year").strip() #去掉字符串两边的空白
pingfen = item.group("pingfen")
num = item.group("num")
f.write(f"电影名称:{name}\n导演:{daoyan}\n主演:{zhuyan}\n年份:{year}\n评分:{pingfen}\n{num}人评价\n")
#收尾工作
f.close()
resp.close()
print("数据保存成功")
2.3 BS
2.3.1 BS知识点总结
BeautifulSoup 是一个 Python 库,用于从 HTML 或 XML 文件中提取数据。它的主要优势在于能将复杂的 HTML 文档转换成一个结构化的树形对象,让你能轻松地通过标签名、属性、文本等方式来查找和操作节点。
其安装方式依旧是(pip install beautifulsoup4);导入方式为(from bs4 import BeautifulSoup)
使用BeautifulSoup的第一步。需要将HTML/XML文本或文件对象传入到BeautifulSoup构造函数,并指定一个解析器。如代码所示,soup对象现在代表了整个html文档的结构,你可以把它想象成一个树的根节点
from bs4 import BeautifulSoup
# 假设 html 是你的 HTML 字符串
html_doc = "<html><head><title>标题</title></head><body><p>内容</p></body></html>"
# 创建 BeautifulSoup 对象
# 第一个参数是要解析的文本
# 第二个参数是解析器,推荐使用 "html.parser" (Python 内置,无需额外安装)
# 其他选项有 "lxml" (速度快,功能强,但需要 pip install lxml) 和 "html5lib" (兼容性好)
soup = BeautifulSoup(html_doc, "html.parser")BeautifulSoup 最常用的功能是
soup.find() | 查找第一个匹配条件的元素。 | 一个 Tag 对象,如果找不到则返回 None。 | li = page.find("li", attrs={"id": "abc"}) |
soup.find_all() | 查找所有匹配条件的元素。 | 一个包含 Tag 对象的列表 (list),如果找不到则返回空列表 []。 | li_list = page.find_all("li") |
其查找条件:
- 通过标签名:
soup.find("li") - 通过属性:
soup.find(attrs={"id": "abc"}) - 标签名 + 属性 (最常用):
soup.find("li", attrs={"id": "abc"}) - 简化写法: 对于
id和class属性,可以直接作为关键字参数传入。soup.find("li", id="abc")# 注意 class 是 Python 关键字,所以用class_soup.find("div", class_="container")
遍历 find_all() 的结果: find_all() 返回一个列表,你可以用 for 循环来遍历每一个元素。
li_list = page.find_all("li")
for li in li_list:
# 对每个 li 元素进行操作
print(li) 嵌套查找: 你可以在一个已经找到的元素(Tag 对象)中继续使用 find() 或 find_all() 进行查找。
# 先找到 id 为 abc 的 li 标签
li = page.find("li", id="abc")
# 再在这个 li 标签内部查找 a 标签
a = li.find("a") 找到元素后,通常需要提取它的文本内容或属性值。此时就需要.text或.get_text()。对于后者可以提供多个参数,如:strip=True 可以去除首尾空白,separator=' ' 可以指定拼接符。
a_tag = page.find("a")
print(a_tag.text) # 输出: 张三2.3.2 实战演练
import requests
from bs4 import BeautifulSoup
import re
"""
子页面的url如果开头是/,直接在前面拼接上域名即可
子页面的url不是/开头,此时需要找到主页面的url,去掉最后一个/后面的所有内容,再拼接上子页面的url
"""
url = 'https://umei.net/tags/nvpu/'
domain = "https://umei.net/"
resp = requests.get(url)
obj = re.compile(r'<li class="i_list list_n2">.*?<a href="(?P<href>.*?)" title=',re.S)
main_page = BeautifulSoup(resp.text,"html.parser")
result1 = obj.finditer(resp.text)
n = 1
for item in result1:
href = item.group("href")
child_url = domain + href
child_resp = requests.get(child_url)
child_resp.encoding = "utf-8"
#子页面的bs对象
child_bs = BeautifulSoup(child_resp.text,"html.parser")
#子页面的图片url
div = child_bs.find("div", attrs={"class":"image_div"})
img_src = div.find("img").get("src") #拿到图片的下载路径
#下载图片
img_resp = requests.get(img_src) #图片不是文本,不能获取text的内容,所以应该用字节的形式
img = img_resp.content
with open(f"{n}.jpg",mode = "wb") as f:
f.write(img_resp.content)
print(f"第{n}张图片下载完成")
n += 1
f.close()
child_resp.close()
resp.close()
该代码对于一个图片的保存做了很好的阐述,因为其不是文本,所以我们不能用之前那种编码,使用的更应该是字节的形式。
2.4 XPath
2.4.1 知识点分析
<book>
<id>1</id>
<name>测试</name>
<price>1.23</price>
<author>
<nick>name1</nick>
<nick>name2</nick>
</author>
</book>对于上述代码做出总结:
-
book,id,name,price...都被称为节点
-
Id,name,price,author被称为book的子父节点
-
book被称为id,name,price,author的父节点
-
id,name,price,author被称为同胞节点
2.4.2 实战演练
"""
拿到页面源代码
从页面源代码获取所有的项目名称
"""
import requests
from lxml import etree
url = "https://www.zbj.com/fw/"
f = open("猪八戒.csv",mode="w",encoding="utf-8")
data = {
"type":"news",
"kw":"saas"
}
haeders = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"
}
resp = requests.get(url,params=data,headers=haeders)
er = etree.HTML(resp.text)
#search-result-list-service,准备变量来收
divs = er.xpath("//div[@class='search-result-list-service']/div")
for div in divs:
price = div.xpath("./div/div[3]/div[1]/span[1]/text()")[0]
tltle = div.xpath("./div/div[3]/div[2]/div/span//text()") #表示提取span中的所有
tltle = "".join(tltle)
company = div.xpath("./div/div[5]/div/div/div/text()")[0]
f.write(f"项目名称:{tltle},价格:{price},公司名称:{company}\n")
2.5 PyQuery
PyQuery 是一个模仿 jQuery 语法的 Python 库,它能让你像在浏览器中操作 DOM 一样方便地解析 HTML。
- 核心思想:将 HTML 解析成一个树状结构(DOM 树),然后通过强大的CSS 选择器来定位和操作其中的节点。
- 在代码中的应用:
- 初始化:
pq(html_string)将 HTML 字符串加载成一个 PyQuery 对象。 - CSS 选择器:这是其核心优势。
p("a"):选择所有<a>标签。p(".item a"):选择 class 为item的元素下的所有<a>标签。p("#qq a"):选择 id 为qq的元素下的所有<a>标签。
- 提取数据:
.attr("href"):获取选中节点的href属性值。.text():获取选中节点的文本内容。
- 遍历多个元素:当选择器匹配到多个节点时,
.items()方法会返回一个迭代器,方便你逐个处理每个节点。 - DOM 操作:PyQuery 不仅能读,还能修改。如
.after(),.append(),.attr(),.remove()等方法,可以动态地添加、修改或删除标签和属性。
- 初始化:
三、对与电影天堂的爬取
"""
提取到主页面中的每一个电影背后的那个URL地址
拿到2021必看热片的html代码
从刚才拿到的html代码中提取到href的值
访问子页面,提取到电影的名称以及下载地址
"""
import requests
import re
f = open("电影天堂.csv",mode="w",encoding="utf-8")
url = "https://www.dytt8899.com/"
resp = requests.get(url)
resp.encoding = "gbk"
#1.提取到必看热片代码
obj = re.compile(r"2025必看热片.*?<ul>(?P<html>.*?)</ul>",re.S)
result1 = obj.search(resp.text)
html = result1.group("html")
#2.提取a标签中的href属性
obj2 = re.compile(r"<li><a href='(?P<href>.*?)' title")
result2 = obj2.finditer(html)
#爬虫要对id敏感,所以采取id进行定位
obj3 = re.compile(r'<br />◎片 名(?P<name>.*?)<br />.*?<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<url>.*?)">',re.S)
for item in result2:
url2 = url.strip("/") + item.group("href")
child_resp = requests.get(url2)
child_resp.encoding = "gbk"
result3 = obj3.search(child_resp.text)
movie = result3.group("name")
download_url = result3.group("url")
f.write(f"电影名称{movie}/t下载地址{download_url}\n")
f.close()
resp.close()
child_resp.close()
print("数据已保存")四、一个简单的模拟用户登录的程序
模拟用户登录实际是获取其Cookie值来进行登录,cookie值的抓取需要通过数据包来获得。
#登录 -> 得到cookie
#带着cookie 去请求到书架url -》 书架上的内容
#把上述操作连续起来
#我们可以使用session请求 -> session你可以认为是一连串的请求,在这个过程中的cookie不会丢失
import requests
#会话
session = requests.session() #拿session对象
#1.登录
url = "https://passport.17k.com/ck/user/login"
data = {
"loginName":"Freedom049527",
"password":"sin(30)Msy049527"
}
#session.post(url,data=data,headers=headers)
#print(resp.text)
#print(resp.cookies)
#2.那书架上的内容
resp = requests.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919",headers={
"Cookie":"GUID=25c4d053-d289-43e0-87b9-a20d76772fc1; sajssdk_2015_cross_new_user=1; Hm_lvt_9793f42b498361373512340937deb2a0=1758178121; HMACCOUNT=B385CD001FAA3161; c_channel=0; c_csc=web; acw_sc__v2=68cbaed0dea5efb1275723ff87124fbf4bd8c39b; ssxmod_itna=eu0Q0KAI3x8f40L9YtDymDBQnD7DmEidM0fu4GXhmYDZDiqAPGhDC3bUgd4QQ2qEWDp04r3=58QnwvW=tBWfPirDCPGnDBFhfqQxYYkDt4DTD34DYDi2KDLDmeD+GqKDdEsNXzS2D3qDwDB=DmqG2ld=Dm4DfDDLn30qGbLQD4qDBDGtx2jNDG4Gf7uqD0LEIDohuDxGWbTtjYnNqcjDgYY=DjqGgDBLelcwn0lyGZDNgUpGFTOQxPeGuDG6ehTdqx0P9nwt086vpDEhYlA5=+Yha3AqDRExNiGCitBDiDhwB=XDBdA1PCDSfGgKBvnDSiyZeD==; ssxmod_itna2=eu0Q0KAI3x8f40L9YtDymDBQnD7DmEidM0fqA=nIQD/3YDF2dI=E=oKlYzBBaypzH8rTn0FD8xWNz/W9AyDmoP4Yvz8W+PMumqROG390VfKLiTpgbwx38fQvS13=ydvhUGREokTnX7b3fM73E0Dni4=LNedbig7W0gY+IXi+K8n7XQ2CR7b0qp7RUeKGNix=xPzTqfbuc4TpU8lWYyA2EsYmbCSrt++39sIR2+ZQR5v4m3cr=M+rdAs4Sql2fr1zGKWbY4TmIUbQjgQq+IzctvblF1gMFGMzFoM18iBzU70t=M4FkVdHdBrVe7zCwiWvXYYEib//0w7bxDhR+KfIuzUexvFu4Bpf5CUT/AFNlezlxrQWO8hib+B8hL/bl0bQaqQwPr7OMDbGCTs/A5ZGAjnC433D07803eODKExRgzrTE6iKyMEl8+Qa5=Y3G7k208zDsdkLS0L57NOpE7r+gBDHBD8rKfP=GY5=YUp35M0oFxLuoxSZDl7aD7=DYIiXv5m99UxxDhAQ0E42fI3xBe7ta57CH6j5BWxlGwo0msRwOQ2U0eZGaK2Wc0NlGN+lqp=4eD==; accessToken=avatarUrl%3Dhttps%253A%252F%252Fcdn.static.17k.com%252Fuser%252Favatar%252F12%252F32%252F88%252F104288832.jpg-88x88%253Fv%253D1758179303000%26id%3D104288832%26nickname%3DFreedom049527%26e%3D1773732252%26s%3Dbe5b09889cc66379; tfstk=gONiLjDydRk1FpO6IZc1BR9UBvBKffGjdodxDjnVLDoIDNitXrr0ozkq7CrTKmqUxclx65C0nDlZhRnxXmc0lubd2_C85PGj3gIRwip7FfGS7duwDvJErj0aKspP6PGjgMLpgTCu5lO6T9cZgwcEo4oqgIrqLvoIlq-ZuC738Die_dJZQBzE54uq0olV-yoIujo40x738DgqgmkK0Oo_gWPF0SBmKpk0JW0iI0zhFnxqEQHn4PnHggPnSnoz7DA2g0YAkrz3WGA7JfaUq4EOTCquPWZn8u5cxjZQ3ou0Y_tx18E_Nv4CUBzKsDkrzW72amFgpzonZE5a-fmiU5HNZaZz-ry-KWQPNfcZb-h_kUjT-5qT5W4vupli6JDusb5WbmeLrS00Gi13qzNQx2rPiGSzvpJPq1Oj8ZFHhKMZR2m8Pt_7O5QplR7h-L7jQ2gs2wbHhKMZR2mR-wvPlAuI50C..; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22104288832%22%2C%22%24device_id%22%3A%221995b9515327e0-08c385756cd7608-26011051-1327104-1995b9515331c41%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fgraph.qq.com%2F%22%2C%22%24latest_referrer_host%22%3A%22graph.qq.com%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%7D%2C%22first_id%22%3A%2225c4d053-d289-43e0-87b9-a20d76772fc1%22%7D; Hm_lpvt_9793f42b498361373512340937deb2a0=1758180253"
})
print(resp.text)
这里其实有两种方法,一种是通过session保存,另一种是登陆后获取其Cookie值进行保存,代码所展示的部分是cookie值登录,而注释掉的则是获取cookie值进行登陆的部分。
五、总结
看似我们学了很多的爬取方法,觉得我是不是只要一种就可以了?实际却不是这样的,对于不同的网页,所采取的方法也是不一样的,并且要善于利用网络数据包,通过构造header的方式来绕过一些反爬(referer啦,user-agent啦,还有X-forwared-for啦)要让网页误以为你的程序不是程序而是真人,才可以做到爬取想要的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号