volatile
happens-before原则
我们编写的程序都要经过优化后(编译器和处理器会对我们的程序进行优化以提高运行效率)才会被运行,优化分为很多种,其中有一种优化叫做重排序,重排序需要遵守happens-before规则,换句话说只要满足happens-before原则就可以进行重排序。
定义:在JMM中,如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系
注意:定义中所说的前一个操作happens-before后一个操作并不是说前一个操作必须要在后一个操作之前执行,而是指前一个操作的执行结果必须对后一个操作可见,考虑下述情况:
int a = 1; //操作A
int b = 2; //操作B
单线程执行上述代码块规定操作A happens-before 操作B,也就是说操作A的结果对操作B是可见的,但是操作B对操作A中a=1的赋值并没有依赖,即使操作A与操作B重排序了,它们之间的happens-before关系仍然存在,这个例子就说明了happens-before并不是对执行顺序对约束,同时也是重排序的一种情况。
规则:
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作;
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C;
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作;
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始;
volatile关键字
可见性
volatile修饰的变量的一个特点是可见性:保证被volatile修饰的共享变量对所有线程可见,也就是当一个线程修改了一个被volatile修饰变量的值,其他线程可以立即得知新值,举例:
volatile boolean shutdownRequested;
public void shutdown(){
shutdownRequested = true;
}
public void doWork(){
while(!shutdownRequested){
//do stuff
}
}
错误用法:
public class VolatileVisibility {
public static volatile int i =0;
public static void increase(){
i++;
}
}
/**
volatile关键值不保证有序性,i++包括读取一个值,然后写回一个新值,新值比原来值加了1,这相当于两个步骤,如果第二个线程在第一个线程读取旧值和写回新值期间读取i的值,并进行加一操作,会发生更新重复,存在线程安全问题
**/
有序性
volatile修饰的变量的另一个特是有序性点:禁止指令重排优化,从而避免多线程环境下程序出现乱序执行的现象
//双重校验锁
public class Singleton {
private static volatile Singleton instance = null;
private Singleton() { }
public static Singleton getInstance() {
if(instance == null) {
synchronized(Singleton.class) {
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
疑问:上述代码Singleton变量为什么要用volatile修饰?
解答:
instance = new Singleton()可以分为下述步骤完成:
memory = allocate(); //1:分配对象的内存空间
instance(memory); //2:初始化对象
instance = memory; //3:设置instance指向刚分配的内存地址
由于2,3步骤没有数据依赖关系,因此2,3可以重排序并没有违背单线程的happens-before规则,重排后如下:
memory = allocate(); //1.分配对象内存空间
instance = memory; //3.设置instance指向刚分配的内存地址,此时instance!=null,但是对象还没有初始化完成!
instance(memory); //2.初始化对象
根据volatile变量的可见性,在执行完3后,instance不为空,但是尚未实例化,但是此时如果有线程过来请求实例,就可能返回尚未实例化对象。
内存屏障
缓存一致性
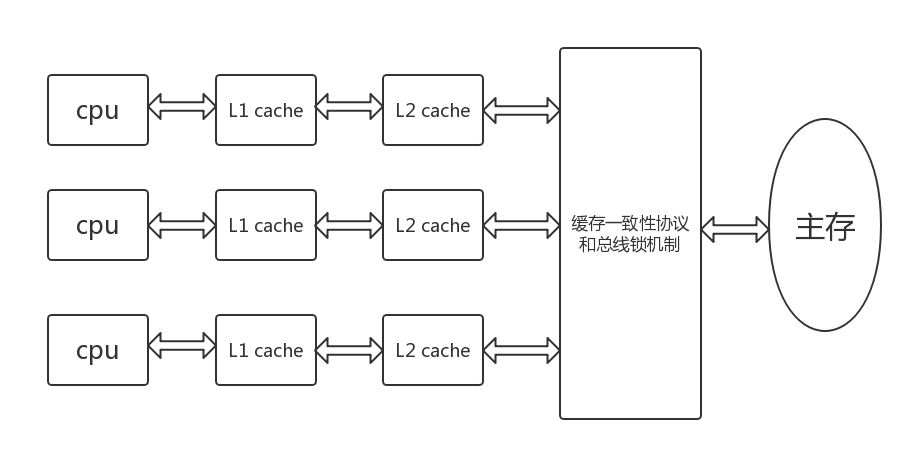
-
嗅探机制(snooping):所有内存传输都发生在一条共享的总线上,而所有的处理器都能看到这条总线:缓存本身是独立的,但是内存是共享资源,嗅探(snooping)协议的思想是,缓存不仅仅在做内存传输的时候才和总线打交道,而是不停地在嗅探总线上发生的数据交换,跟踪其他缓存在做什么。所以当一个缓存代表它所属的处理器去读写内存时,其他处理器都会得到通知,它们以此来使自己的缓存保持同步。只要某个处理器一写内存,其他处理器马上就知道这块内存在它们自己的缓存中对应的段已经失效。
-
总线锁机制(lock):在指令前面加上lock,那么会锁住总线和相应的缓存,其他指令会被阻塞,当lock后的指令执行完毕会将结果刷新到内存中去,根据嗅探机制,其他cpu中的缓存会失效,重新从内存中读取,也就解决了缓存一致性问题
-
缓存一致性协议(MESI):cpu缓存有四个标记位:
M: Modify,修改缓存,当前CPU的缓存已经被修改了,即与内存中数据已经不一致了
E: Exclusive,独占缓存,当前CPU的缓存和内存中数据保持一致,而且其他处理器并没有可使用的缓存数据
S: Share,共享缓存,和内存保持一致的一份拷贝,多组缓存可以同时拥有针对同一内存地址的共享缓存段
I: Invalid,失效缓存,这个说明CPU中的缓存已经不能使用了
CPU的读取遵循下面几点:
如果缓存状态是I,那么就从内存中读取,否则就从缓存中直接读取。
如果缓存处于M或E的CPU读取到其他CPU有读操作,就把自己的缓存写入到内存中,并将自己的状态设置为S。
只有缓存状态是M或E的时候,CPU才可以修改缓存中的数据,将其他cpu缓存设置无效,修改后,缓存状态变为M
内存屏障
- 硬件层的内存屏障分为两种:Load Barrier 和 Store Barrier即读屏障和写屏障。
- 内存屏障有两个作用:
阻止屏障两侧的指令重排序;
强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
- 对于Load Barrier来说,在指令前插入LoadBarrier,可以让高速缓存中的数据失效,强制从新从主内存加载数据;对应的在读volatile变量前加上Lfence
- 对于Store Barrier来说,在指令后插入StoreBarrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见,对应的在写volatile变量后加上Sfence
参考资料
http://blog.csdn.net/u010031673/article/details/48153797
https://kb.cnblogs.com/page/504824/
https://www.cnblogs.com/dolphin0520/p/3920373.html
https://www.jianshu.com/p/195ae7c77afe
http://blog.csdn.net/iter_zc/article/details/42006811
https://www.jianshu.com/p/2ab5e3d7e510

 浙公网安备 33010602011771号
浙公网安备 33010602011771号