进阶2:Hadoop 环境搭建: hadoop3.1.1 jdk1.8 在centos6.5上的伪分布式安装
参考文章:
https://blog.csdn.net/qq_38038143/article/details/82779016
https://blog.csdn.net/m0_37461645/article/details/84111375
1. 安装包准备
hadoop3.1 : https://pan.baidu.com/s/1VBivgUyyjmS5ysLOiVC1Og 密码:xxo6 jdk1.8 : https://pan.baidu.com/s/142vome8m8BfsE6aF6OMZyA 密码: jg1l
在主机端下载后,通过WinSCP软件将两个安装包传输到Redhat上。如图:

2. 安装jdk
命令:
rpm -ivh jdk-8u51-linux-x64.rpm
安装完成后,执行命令如下:
rpm -qa | grep jdk
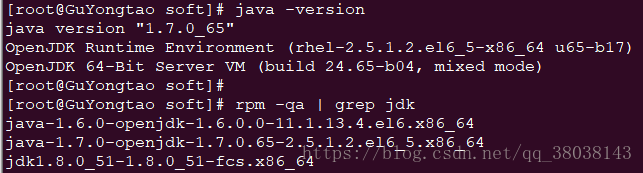
发现,java的版本仍然为1.7.0_65。rpm命令查询,系统默认已安装了jdk1.6和1.7。则依次卸载1.6和1.7:
命令:
rpm -e java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
rpm -e java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
并且修改/etc/profile文件,在文件末尾添加:
export JAVA_HOME=/usr/java/jdk1.8.0_51
执行命令,使/etc/profile文件立即生效:
命令:
source /etc/profile
再次查看java版本,安装成功

3. 设置免密登录
依次执行命令:
ssh-keygen -t rsa cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys chmod 600 authorized_keys
执行ssh localhost查看系统是否能够免密登录。
4. hadoop安装
解压hadoop-3.1.1:
tar -zxvf hadoop-3.1.1.tar.gz
移动压缩后的文件,并修改名称:
mv hadoop-3.1.1 /usr/local/hadoop
编辑hadoop 版本文件
vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在该文件hadoop-env.sh末尾加入:
export JAVA_HOME=/usr/java/jdk1.8.0_51
执行命令查看版本:
cd /usr/local/hadoop/
./bin/hadoop version

配置文件:
修改文件~/.bashrc,在文件末尾加入:
export JAVA_HOME=/usr/java/jdk1.8.0_51 export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
5. 伪分布式搭建
5.1 hadoop配置
5.1.1 在 /usr/local/hadoop/ 创建目录:

5.1.2 修改配置文件:
进入路径:
修改以下文件内容:
- vim core-site.xml
注:将下列所有配置文件的yue修改为自己centOS的主机名(如下面代码第9行,修改为hdfs://你的主机名:9000)
在<configuration中加入以下内容,:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>注释</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://yue:9000</value>
</property>
</configuration>
2.vim hdfs-site.xml
在<configuration中加入以下内容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
</configuration>
- vim mapred-site.xml
在<configuration中加入以下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>yue:9001</value>
</property>
</configuration>
4. vim yarn-site.xml
在<configuration中加入以下内容:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>yue:8099</value>
</property>
</configuration>
6. 报错处理(可以跳过此步骤,直接进入8. hadoop启动)
由于启动过程发生报错,作出以下修改:
进入路径:
[root@master sbin]# pwd
/usr/local/hadoop/sbin
1.修改start-dfs.sh,stop-dfs.sh
在这两个文件的头部加入:
#!/usr/bin/env bash HDFS_DATANODE_USER=root HADOOP_SECURE_DN_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
2.修改start-yarn.sh,stop-yarn.sh
在这两个文件的头部加入:
#!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
3. 修改文件:
vim /usr/local/hadoop/etc/hadoop/log4j.properties
4.在文件末尾加入:
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
5. 如果在启动时报错:could not resolve hostname yue :name or service not know

解决办法:
vi /etc/hosts
注释前面,并新增(IP 主机名):
192.168.57.129 yue

7. hadoop启动(若启动时报错,可以回到6. 报错处理)
修改/etc/profile文件,在文件末尾加入,并执行source /etc/profile:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
格式化namenode节点:
命令:
hdfs namenode -format
效果:

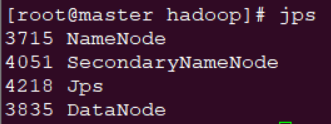
启动:系统能够免密登录后,启动命令(停止命令:stop-all.sh):
- 执行
start-dfs.sh
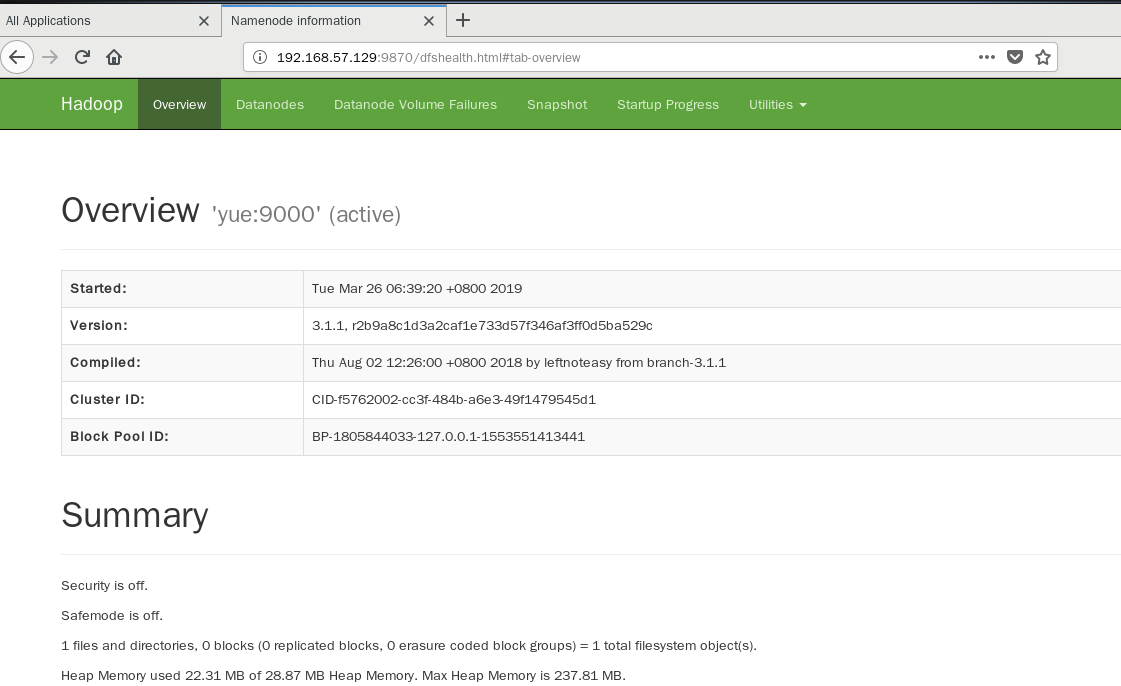
在Linux的浏览器查看(hadoop2.x 端口为:50070,3.1为9870):
可查看 NameNode 和 Datanode 信息,也可以在线查看 HDFS 中的文件
2. 执行
start-yarn.sh
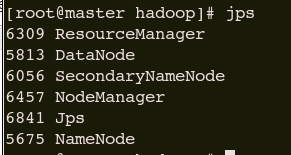
在Linux的浏览器查看,可查看任务运行情况:

配置完成
参考链接:
https://blog.csdn.net/cx105200/article/details/78284761
https://blog.csdn.net/u011762604/article/details/72897000
https://blog.csdn.net/mm_bit/article/details/49474709
https://blog.csdn.net/lglglgl/article/details/80553828
https://blog.csdn.net/l1028386804/article/details/51538611

 浙公网安备 33010602011771号
浙公网安备 33010602011771号