
基于langchain4j入门学习RAG
Retrieval 检索 Augment 增强 Generation生成
RAG即检索增强生成,通过检索外部知识库的方式增强大模型的生成能力,重点在于通过检索机制增强大模型的生成能力
为什么使用RAG?
在不使用RAG之前,用户通过提出的问题生成prompt,将prompt发送给大模型后等待回复。
这种模式的缺点是:一旦模型训练结束,后续的及时性数据处于大模型未知状态,无法正确回复。为此引入了外部知识库,通过外部知识库提供额外的信息来增强大模型的回复。
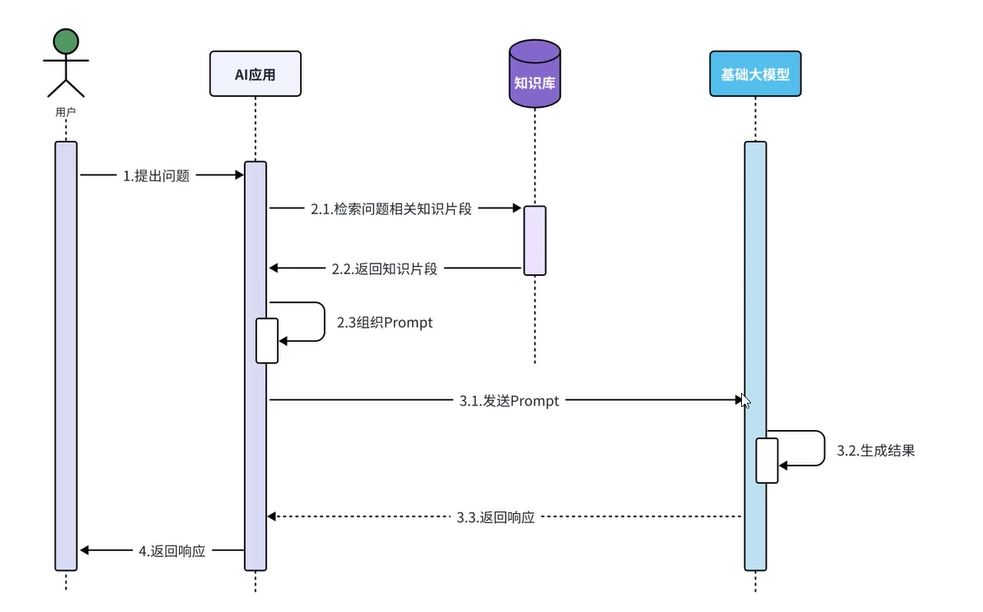
什么是RAG,RAG都有哪些实现方式及对应的优缺点场景?
RAG = 大模型 + 检索机制(我们常用向量数据库,也可以使用知识图谱或者混合搜索:
向量数据库语义相似度匹配能力强,适合开放式场景问答,但是无法处理精确条件过滤;
知识图谱虽然支持多跳推理,适合因果推理与事实核查,但依赖人工构建;
混合搜索适合企业级知识管理,他能兼顾语义与多跳查询,但是系统复杂度较高)
langchain4j快速使用Easy RAG
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-easy-rag</artifactId> <version>1.0.1-beta6</version> </dependency>
主要分两个步骤:1.索引数据,2.检索数据
索引数据:将数据加载到文档,再将文档切分向量化后哦存入向量数据库。
存储数据分为多个步骤:
1.将文档数据正确加载(使用文档加载器document loader),并进行解析(使用文档解析器document parser),得到可供AI使用的文档;
langchain4j提供三种文档加载器:
根据绝对路径加载、根据相对路径加载、根据URL加载
langchain4j提供多种文档解析器:
解析纯文本格式TextDocumentParser、pdf格式ApachePdfBoxDocumentParser、微软的office格式ApachePoiDocumentParser、以及默认的解析所有格式的文件ApacheTikaDocumentParser,此外官网还提供了加载所有子目录的方法:loadCocumentsRecursively,并且可以通过正则表达式过滤某些文档
这里使用非默认解析器(因为tika已经默认包含在easy-rag包下)时,需要额外引入依赖。以pdfbox为例
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-document-parser-apache-pdfbox</artifactId> <version>1.0.1-beta6</version> </dependency>
本小结实际使用案例:
//1.1 文档加载器:根据相对路径加载文档:加载res下doc文件夹内的文件 //1.2 使用tika解析器 List<Document> doc = ClassPathDocumentLoader.loadDocuments("doc", new ApacheTikaDocumentParser()); //1.2 使用pdfbox解析器 List<Document> docPdf = ClassPathDocumentLoader.loadDocuments("doc/pdf", new ApachePdfBoxDocumentParser());
2.将文档切割成多个textSegment(使用文档切割器document splitter)
文档切割器分为按段、行、句、字符切割,还有按token(语义)、代码结构、保持标题和段落结构(读markdown文件)等其他形式。
langchain4j默认使用的是递归切割recursiveSplitter:只要没满chunkSize,那么切割的优先级 段切割 > 行切割 > 句切割 > 子句切割 > 字符切割(这种情况几乎不存在)
recursiveSplitter通用性高,可以应对各类型的文档,复杂文档中也能处理,性能较好。并且相对于token切割,他的配置较少
// RecursiveSplitter 可以处理各种类型的文档 RecursiveSplitter splitter = RecursiveSplitter.builder() .chunkSize(1000) // 目标segment大小 .chunkOverlap(200) // 重叠区间,有一定重叠能够保持上下文 .build();
额外写一下tokenSplitter,一开始我实在不理解这是什么意思。按deepseek的说法,token即按语义切割,他最重要的是能避免截断重要信息,而且能支持多语言,下面是deepseek提供的例子:
String text = "深度学习是人工智能的一个重要分支。"; // 字符分割(每10字符): // ["深度学习是人", "工智能的一个重", "要分支。"] ← 截断语义 // Token分割: // ["深度学习", "是", "人工智能", "的一个重要", "分支。"] ← 保持语义完整
重叠区间:会影响检索的质量与回答的准确性,能一定程度避免信息断层防止关键信息被切割。不同的切割方式会设置不同的重叠区间大小,最优实践在10%~20%左右。
看到这里不知道屏幕前的你是否想去试一试神奇的token切割,看到deepseek写的这段之后我非常的惊叹于token切割这么神奇又类似于分词器的切割方式。
怎么找不到tokenSplitter?我搜到了接口DoucumentSpliltter

我后面又相信肯定和tika一样,需要加载依赖,去官网看一下。最后得出的结论:果然没有,langchain4j的官网压根就没提供文档切割器的相关依赖:
其实文档切割器就上面这6种+一个递归切割器:(下图为官网文档,其实没有什么token切割,代码切割,都是骗人的!!!)

伤心之时已到凌晨,附上本小结的实际使用案例:
//2 文档分割器 //2.1 递归分割文档 DocumentSplitter documentSplitter = DocumentSplitters.recursive(500,100); //2.2 按段落分割文档 DocumentSplitter documentSplitterByP = new DocumentByParagraphSplitter(300,100);
3.将textSegment转换为向量(使用向量模型embeddingModel)
这里黑马推荐直接使用阿里百炼的向量模型。在langchain4j中直接使用配置项即可自动装配实现输入输出的向量转换
langchain4j:
open-ai:
embedding-model:
api-key: ${api-key}
base-url: ${base-url}
model-name: ${model-name}
log-requests: true
log-responses: true
max-segments-per-batch: 10 # 这里根据不同模型的性能设定,一般官方文档都会指出具体大小
然后在config中直接注入embeddingModel即可使用
4.将向量存储到向量数据库中(使用向量数据库操作对象embeddingStore)
默认给的是内存的向量数据库,靠谱人他都得用持久化存储的,我们这里跟黑马,选redis search。
先在网上找一个教程:https://blog.csdn.net/m0_46647628/article/details/135426620
安装好redis search并启动后,加入新的依赖坐标和yaml配置
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-community-redis-spring-boot-starter</artifactId> <version>1.0.1-beta6</version> </dependency>
langchain4j:
community:
redis:
host: localhost
port: 6379
然后直接在config里注入就可以使用了...在项目启动时,所有切割好的向量都会写入到redis中
最后贴一个完整的config里RAG的配置代码:
@Autowired private EmbeddingModel embeddingModel; @Autowired private RedisEmbeddingStore redisEmbeddingStore; // RAG向量数据库操作对象(构建存储功能) @Bean//首次构建向量库的时候需要Bean注解;在第二次启动项目时,需要将bean注解去掉,否则会重复构建向量库,浪费资源并且会在redis里重复出现相同数据 public EmbeddingStore embeddingStore(){ //1.1 文档加载器:根据相对路径加载文档:加载res下doc文件夹内的文件 //1.2 使用tika解析器(解析器选一个即可,分割器同理) List<Document> doc = ClassPathDocumentLoader.loadDocuments("doc", new ApacheTikaDocumentParser()); //1.2 使用pdfbox解析器 List<Document> docPdf = ClassPathDocumentLoader.loadDocuments("doc/pdf", new ApachePdfBoxDocumentParser()); //2 文档分割器 //2.1 递归分割文档 DocumentSplitter documentSplitter = DocumentSplitters.recursive(500,100); //2.2 按段落分割文档 DocumentSplitter documentSplitterByP = new DocumentByParagraphSplitter(300,100); //3.构建向量数据库操作对象,这里是内存使用 InMemoryEmbeddingStore inMemoryEmbeddingStore=new InMemoryEmbeddingStore(); //4.构建一个storeIngestor对象,进行数据切割与向量化存储 EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .embeddingStore(redisEmbeddingStore) .documentSplitter(documentSplitter) .embeddingModel(embeddingModel) .build(); //5.将文档数据存储到向量数据库中 ingestor.ingest(doc); return inMemoryEmbeddingStore; } //RAG向量数据库检索对象(构建检索功能) @Bean public ContentRetriever contentRetriever(){ return EmbeddingStoreContentRetriever.builder() .maxResults(3) .minScore(0.7) .embeddingStore(redisEmbeddingStore) .embeddingModel(embeddingModel) .build(); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号