
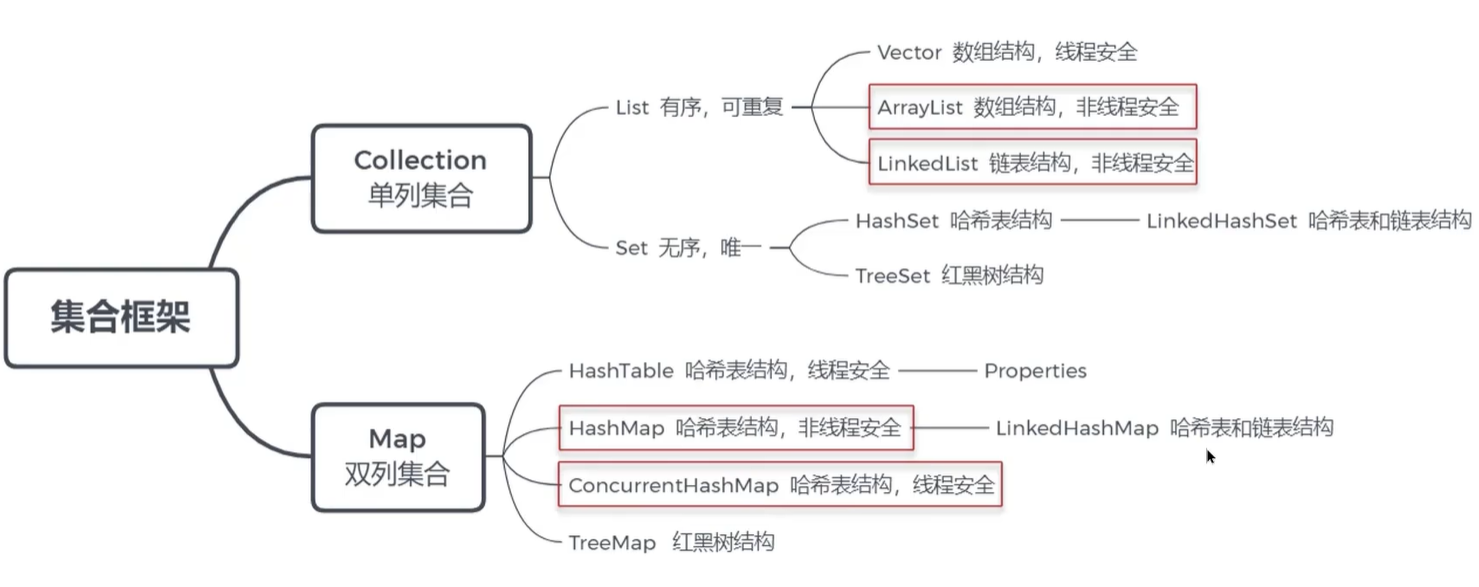
关于JAVA集合框架——collection与map
0.常见的时间复杂度以及性能从好到坏的排序:O(1),O(log n),O(n),O(nlog n),O(n^2)
List相关问题
1.为什么数组的索引是从0开始的,而不是从1开始的呢?
首先数组是一个空间连续存储同种类型元素的有序集合。
如果索引从0开始,那么寻址就是a[i] = baseAddress + i * dataTypeSize 。如果数组的索引是从1开始,那么寻址公式就变成了a[i] = baseAddress + ( i - 1 ) * dataTypeSize。
如果从1开始,对于CPU来说就需要多做一个减法的操作指令,从0开始会让操作更加高效。
2.数组的查找时间复杂度
随机查找(通过下标查),时间复杂度是O(1);不通过下标查找则是O(n);如果排好了序不通过下标查找,会启用二分查找,时间复杂度是O(log n)
数组的增删时间复杂度平均为O(n),因为要挪动其他元素的位置,所以效率不是很好。
3.arraylist的底层原理是什么
arraylist是通过动态数组实现的。
数组初始化容量为0,当一次add时会将数组大小设为10。后续每当超过当前容量,就会扩大1.5倍,扩容会拷贝数组
在添加数据时,1.需要确保数组的size+1有位置放;如果数组满了,就需要调用grow扩容1.5倍大小;确保新增的数据有地方存储后,将新元素放在size位置上;添加成功返回布尔值
4.Arraylist list = new Arraylist(10)是扩容了几次
该语句只是声明并实例了一个arraylist,没有进行扩容
5.如何实现数组和list的转化
数组转List:List<Integer>list=Arrays.asList(nums)。当nums值发生变动后,list也会跟着发生变化,因为asList只涉及了引用,没有new新的对象,用的是new ArrayList<>(Collection<T ?>collect),collect指向的地址和nums仍然一致
List转数组:int [ ] nums = toArray(new Integer(size))。list发生变化后,nums不会一起变化,因为toArray实现了数组的拷贝,相当于new了一个新的,和旧数据没关系了
6.讲讲arraylist和linkedlist的区别
LinkedList是基于双向链表实现的,而arraylist是基于动态数组实现的
效率上arraylist按下标查比较快是O1,其他增删查情况两者基本一致
arraylist相对于linkedlist来说不需要两个指针,更省空间
arraylist和linkedlist都不是线程安全的
如何保证其线程安全
尽量在方法内使用list
集合类提供了Collections.synchronizedList(new Arraylist<>())实现线程安全列表,加了sync锁
HashMap
1.讲讲二叉树和二叉搜索树
二叉树是每个节点最多有两个子节点:左孩子和右孩子,二叉树的每个子树都要满足二叉树的定义
二叉搜索树BST:在二叉树的任意节点,要求左孩子节点值小于当前节点,右孩子节点值大于当前节点。最坏情况下二叉搜索树会退化为链表。正常情况下二叉搜索树的平均时间复杂度为O logn
2.讲讲红黑树
自平衡的二叉搜索树,所有操作都是O logn级别。
根节点都是黑色,叶子节点都是黑色的空节点。红色节点的子节点都是黑的,任一节点到叶子节点的所有路径包含相同数量的黑色节点。
当出现不满足上述性质的情况,树会发生自旋让自己满足性质
3.讲讲散列表
散列表(又称哈希表)是HashMap的重要组成,散列表又由红黑树和链表组成。是根据键key直接访问值value的数据结构,并且利用了数组按照下标访问数据的特性。
散列函数及将key映射为数组的下标,可以表示为hashValue = hash (key)
散列函数计算得到的散列值必须是大于0的正整数 如果key1==key2,那么hash(key1)==hash(key2)
但是反过来如果key1!=key2,那么hash(key1)!=hash(key2)是不一定的,及时是比较出名的md5,SHA算法也无法避免哈希冲突
链表法解决哈希冲突:
当同一个hash(key)对应上多个key之后,我们就需要将原本的数组加上链表,让其插入到对应的链表中。插入的时间复杂度是O 1
当链表过长的时候,效率会明显降低,这里我们引用红黑树代替链表
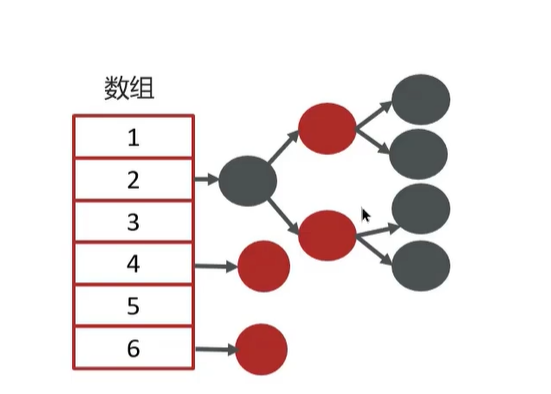
4.HashMap的实现原理
hashmap的数据结构:底层使用的是hash表数据结构,即数组+链表
添加数据时,计算key的值确定元素在数组的下标
- key相同则直接替换value对应的值
- key不同但仍然冲突,则存入链表/红黑树中
后续获取数据仍然通过key的hash计算数组下标获取元素
在JDK+1.8+之后,当链表长度超过8并且容器大小超过64,链表就会进化成红黑树。扩容resize时,红黑树拆成的树的节点如果小于等于6个的话就会退化成链表
5.HashMap的寻址算法
先通过对象的hashCode计算,再调用hash进行二次哈希计算,使哈希分布更均匀
最后根据(capacity-1)&hash得到索引
6.为什么hashMap的数组长度一定要保持2的n次幂?
- 为了提高索引计算效率:使用按位与运算代替取模。计算val的索引时使用(n-1)&hash代替hash%n,减少CPU利用率
- 扩容的时候重新计算的效率会更高:hash&oldCap==0则留在原位,否则新位置=oldCap+旧位置
7.hashMap1.7情况下在多线程
jdk1.7的时候链表使用的是头插法,多线程操作可能会出现链表内节点指向产生A->B->A的死循环;在jdk1.8中使用尾插法解决了这一问题
补充:
1.JDK1.8是如何让hashMap变快的
- 数据结构优化:在1.8中hashMap由数组+链表改成了数组+链表+红黑树,并且链表由头插法改成了尾插法
- hash机制优化:hash将高位也加入了运算,降低了哈希冲突的几率
- 扩容机制优化:1.7的时候是每一个元素都需要进行rehash,1.8通过高位运算来判断是否需要挪动元素
2.怎么线程安全的使用HashMap
在方法体内new hashmap,即每个线程都使用自己的hashmap;
初始化时进行写操作,后续只提供读操作
添加读写锁:写时阻塞,可并行读。使用ReadWriteLock可以比ConcurrentHashMap更灵活的控制颗粒度
使用Collections.SyncronizedMap(),他实际上是一个map的包装类,内部有一个mutex作为对象锁,每次不论进行什么操作都会触发sync(mutex)。这样的性能当然也相当差(这里运用了装饰器模式)
3.重写equals时为什么要重写hashCode
重写equals用来解决判断两个对象是否相等的问题;重写hashCode用来解决判断对象和集合的问题。
举一个简单的例子:equals相同的对象,如果不修改hashCode,那就会导致同样的对象他们对应的hash值不相同,从而导致集合失效(例如set不能去重)
equals方法用于检测两个对象是否相等;在Object类内,equals只是判断值引用是否相等,在绝大多数情况下这是没有意义的。所以在重写equals的时候我们会先判断两个对象的值引用是否相等,然后再判断他们的具体数值是否一一对应。
hashCode方法用于支持哈希表的使用,同一个对象的hashCode是一定相等的。native的hashCode是对值引用进行hash并不适用于作为哈希表的对象;我们重写的hashCode一般是只对和equals相关的属性进行哈希。
4.65535
65535是一串神奇的数字,端口一共有65535个;编译时,String类型长度一旦超过65535就无法编译,因为编译时常量的最大长度是由常量池决定的。不过在运行时,String类型的长度会发生变化,这时其长度要求为不超过Integer.MAX_VALUE
5.String为什么是不可变的
String的value是被final修饰的私有成员变量,String也被final修饰。没有提供任何修改value的方法。每次修改实际都会出现一个新的String对象。
目的是:保证线程安全,String类会保存对应的哈希码,保证常量池复用的可靠性
6.HashSet和TreeSet有什么区别
HashSet基于哈希表,TreeSet基于红黑树
HashSet不保证元素顺序,TreeSet按元素自然排序或者比较器排序。因此HashSet的查找速率是比TreeSet快的,并且TreeSet通过红黑树维护元素的有序性
HashSet通过哈希值判断元素唯一性,TreeSet通过自然排序/比较器将元素放置到正确位置
HashSet适用于快速插入删除的场景,TreeSet适用于需要排序的场景

 浙公网安备 33010602011771号
浙公网安备 33010602011771号