
102302147傅乐宜作业3
1.指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。实现单线程和多线程的方式爬取。
内容
由于是爬了好几次的网站,所以不放网页结构了
核心代码
1.单线程
点击查看代码
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import os
if not os.path.exists('images'):
os.makedirs('images')
max_image=47
count=0
base_url="http://www.weather.com.cn"
headers = {'User-Agent': 'Mozilla/5.0'}
response=requests.get(base_url, headers=headers, timeout=10)
print(response)
response.encoding=response.apparent_encoding
soup=BeautifulSoup(response.text,'lxml')
images=soup.select("img")
urls=[]
count=0
def download(img_url):
global count
try:
print(f"正在下载: {img_url}")
# 发送请求下载图片
response = requests.get(img_url, headers=headers, timeout=10)
response.raise_for_status()
# 从URL中提取文件名
filename = os.path.basename(img_url)
if not filename or '.' not in filename:
filename = f"image_{count + 1}.jpg"
# 完整的文件路径
filepath = os.path.join('images', filename)
# 保存图片
with open(filepath, 'wb') as f:
f.write(response.content)
count+=1
print(f"✓ 成功下载第 {count} 张图片: {filename}")
return True
except Exception as e:
print(f"✗ 下载失败: {str(e)}")
return False
for image in images:
if count >=max_image:
print("已达上限,停止")
break
try:
src = image["src"]
url = urljoin(base_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
点击查看代码
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import os
import concurrent.futures
import threading
if not os.path.exists('images1'):
os.makedirs('images1')
max_image = 47
base_url = "http://www.weather.com.cn"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(base_url, headers=headers, timeout=10)
print(response)
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'lxml')
images = soup.select("img")
urls = []
# 全局计数器和锁
download_count = 0
lock = threading.Lock()
# 多线程下载函数
def download(img_url):
global download_count
try:
print(f"正在下载: {img_url}")
# 发送请求下载图片
response = requests.get(img_url, headers=headers, timeout=10)
response.raise_for_status()
# 从URL中提取文件名
filename = os.path.basename(img_url)
if not filename or '.' not in filename:
filename = f"image_{hash(img_url)}.jpg"
# 完整的文件路径
filepath = os.path.join('images1', filename)
# 保存图片
with open(filepath, 'wb') as f:
f.write(response.content)
with lock:
download_count += 1
print(f"✓ 成功下载第 {download_count} 张图片: {filename}")
return True
except Exception as e:
print(f"✗ 下载失败: {str(e)}")
return False
# 使用 ThreadPoolExecutor 来实现多线程下载
def main():
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for image in images:
try:
src = image["src"]
url = urljoin(base_url, src)
if url not in urls:
urls.append(url)
print(url)
futures.append(executor.submit(download, url))
except Exception as err:
print(err)
# 等待所有任务完成
for future in concurrent.futures.as_completed(futures):
future.result()
if __name__ == "__main__":
main()
结果
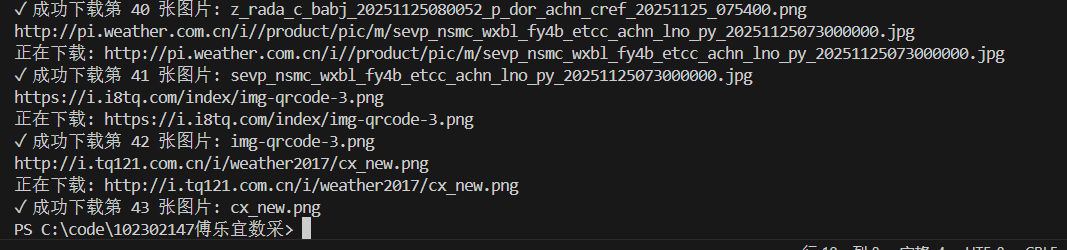
心得体会
主要是在下载的时候才有单线程多线程的区别,相比与单线程,多线程不会被单一下载任务卡住
链接:https://gitee.com/wugao00882999/data-collection/blob/master/%E4%BD%9C%E4%B8%9A3/weather1.py
https://gitee.com/wugao00882999/data-collection/blob/master/%E4%BD%9C%E4%B8%9A3/weather2.py
2.熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
内容
这也是个爬过的网站,故不再展示网页结构
核心代码
spider
点击查看代码
import scrapy
import json
import re
from Stock.items import StockItem
class EastMoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['push2.eastmoney.com']
def start_requests(self):
url = "https://push2.eastmoney.com/api/qt/clist/get"
params = {
"np": 1,
"fltt": 1,
"invt": 2,
"cb": "jQuery37106236146953184138_1761719786814",
"fs": "m:0+t:6+f:!2,m:0+t:80+f:!2,m:1+t:2+f:!2,m:1+t:23+f:!2,m:0+t:81+s:262144+f:!2",
"fields": "f12,f13,f14,f1,f2,f4,f3,f152,f5,f6,f7,f15,f18,f16,f17,f10,f8,f9,f23",
"fid": "f3",
"pn": 1,
"pz": 20,
"po": 1,
"dect": 1,
"ut": "fa5fd1943c7b386f172d6893dbfba10b",
"wbp2u": "|0|0|0|web",
"_": "1761719786819"
}
yield scrapy.Request(
url=f"{url}?{'&'.join([f'{k}={v}' for k, v in params.items()])}",
callback=self.parse
)
def parse(self, response):
content = response.text
pattern = r'^.*?\((.*)\);$'
match = re.match(pattern, content)
if match:
json_str = match.group(1)
data = json.loads(json_str)
if 'data' in data and 'diff' in data['data']:
stocks = data['data']['diff']
for stock in stocks:
item = StockItem()
item['stock_code'] = stock['f12']
item['stock_name'] = stock['f14']
# 处理最新价格
latest_price = str(stock['f2'])
if len(latest_price) > 2:
item['latest_price'] = latest_price[:2] + '.' + latest_price[2:]
else:
item['latest_price'] = latest_price
# 处理涨跌幅
change_percent = str(stock['f3'])
if len(change_percent) > 2:
item['change_percentage'] = change_percent[:2] + '.' + change_percent[2:] + '%'
else:
item['change_percentage'] = change_percent + '%'
yield item
pipeline
点击查看代码
from itemadapter import ItemAdapter
import pymysql
import json
class MySQLPipeline:
def __init__(self, mysql_host, mysql_db, mysql_user, mysql_password):
self.mysql_host = mysql_host
self.mysql_db = mysql_db
self.mysql_user = mysql_user
self.mysql_password = mysql_password
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host=crawler.settings.get('MYSQL_HOST'),
mysql_db=crawler.settings.get('MYSQL_DATABASE'),
mysql_user=crawler.settings.get('MYSQL_USER'),
mysql_password=crawler.settings.get('MYSQL_PASSWORD')
)
def open_spider(self, spider):
self.connection = pymysql.connect(
host=self.mysql_host,
user=self.mysql_user,
password=self.mysql_password,
database=self.mysql_db,
charset='utf8mb4'
)
self.cursor = self.connection.cursor()
# 创建表
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INT AUTO_INCREMENT PRIMARY KEY,
stock_code VARCHAR(20) NOT NULL,
stock_name VARCHAR(100) NOT NULL,
latest_price VARCHAR(20),
change_percentage VARCHAR(20),
UNIQUE KEY unique_stock (stock_code)
)
''')
self.connection.commit()
def close_spider(self, spider):
self.connection.close()
def process_item(self, item, spider):
# 使用INSERT ... ON DUPLICATE KEY UPDATE 避免重复数据
sql = '''
INSERT INTO stocks (stock_code, stock_name, latest_price, change_percentage)
VALUES (%s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
stock_name = VALUES(stock_name),
latest_price = VALUES(latest_price),
change_percentage = VALUES(change_percentage)
'''
self.cursor.execute(sql, (
item['stock_code'],
item['stock_name'],
item['latest_price'],
item['change_percentage']
))
self.connection.commit()
return item
class JsonWriterPipeline:
def open_spider(self, spider):
self.file = open('stocks.json', 'w', encoding='utf-8')
self.file.write('[\n')
self.first_item = True
def close_spider(self, spider):
self.file.write('\n]')
self.file.close()
def process_item(self, item, spider):
line = '' if self.first_item else ',\n'
self.first_item = False
line += json.dumps(dict(item), ensure_ascii=False, indent=2)
self.file.write(line)
return item
结果
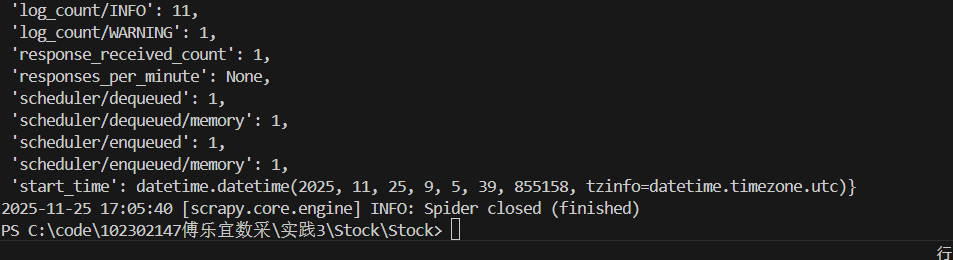
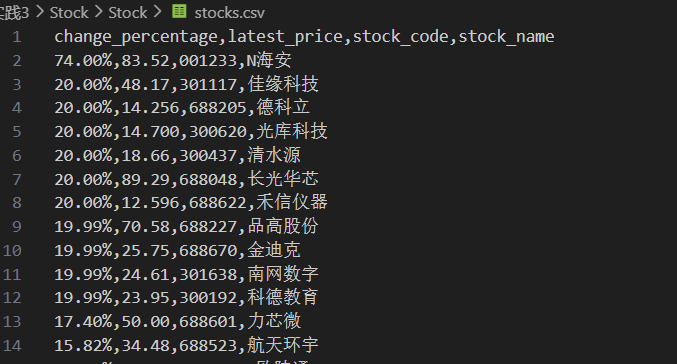
心得体会
本次实验让我对 Scrapy 项目的结构和运行流程有了更清晰的认识,知道了如何从原有的爬虫套用框架
链接:https://gitee.com/wugao00882999/data-collection/tree/master/%E4%BD%9C%E4%B8%9A3/Stock
3.熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
内容
网页结构
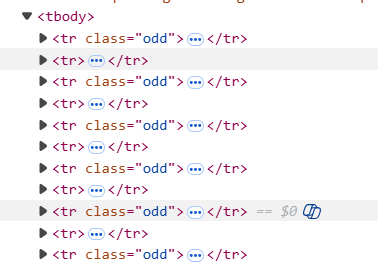
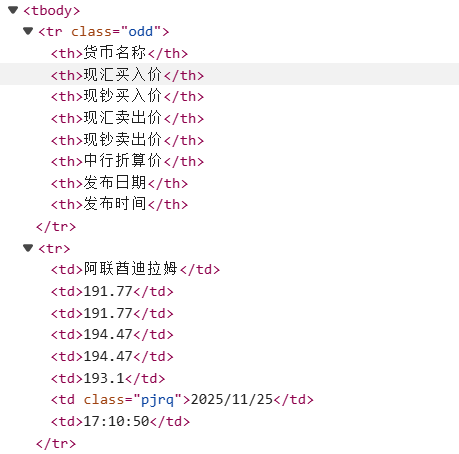
网页结构简单,容易定位元素tr,td
核心代码
spider
点击查看代码
import scrapy
from Forex.items import BocExchangeItem
from datetime import datetime
class BocSpider(scrapy.Spider):
name = 'boc_exchange'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
custom_settings = {
'USER_AGENT': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'DOWNLOAD_DELAY': 1,
'CONCURRENT_REQUESTS': 1,
}
def parse(self, response):
# 定位表格行
rows = response.xpath('//div[@class="publish"]//table/tr')
# 跳过表头,处理数据行
for row in rows[1:]:
columns = row.xpath('./td/text()').getall()
if len(columns) >= 6:
item = BocExchangeItem()
item['currency_name'] = columns[0].strip() if columns[0].strip() else None
item['buying_rate'] = columns[1]
item['cash_buying_rate'] = columns[2]
item['selling_rate'] = columns[3]
item['cash_selling_rate'] = columns[4]
item['middle_rate'] = columns[5]
item['pub_time'] = columns[6].strip() if len(columns) > 6 else None
item['crawl_time'] = datetime.now()
yield item
pipeline
点击查看代码
from itemadapter import ItemAdapter
import sqlite3
import logging
class SQLitePipeline:
def __init__(self, sqlite_db):
self.sqlite_db = sqlite_db
self.conn = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
sqlite_db=crawler.settings.get('SQLITE_DB', 'exchange_rates.db')
)
def open_spider(self, spider):
# 连接数据库
self.conn = sqlite3.connect(self.sqlite_db)
self.cursor = self.conn.cursor()
self.create_table()
def close_spider(self, spider):
# 关闭数据库连接
if self.conn:
self.conn.close()
def create_table(self):
# 创建数据表
create_table_sql = """
CREATE TABLE IF NOT EXISTS exchange_rates (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency_name VARCHAR(50) NOT NULL,
buying_rate DECIMAL(10,4),
cash_buying_rate DECIMAL(10,4),
selling_rate DECIMAL(10,4),
cash_selling_rate DECIMAL(10,4),
middle_rate DECIMAL(10,4),
pub_time DATETIME,
crawl_time TIMESTAMP
)
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
def process_item(self, item, spider):
# 检查数据是否已存在
if not self.data_exists(item):
self.insert_data(item)
spider.logger.info(f"插入数据: {item['currency_name']}")
else:
spider.logger.info(f"数据已存在: {item['currency_name']}")
return item
def data_exists(self, item):
# 检查重复数据
check_sql = """
SELECT COUNT(*) FROM exchange_rates
WHERE currency_name = ? AND pub_time = ?
"""
self.cursor.execute(check_sql, (item['currency_name'], item['pub_time']))
return self.cursor.fetchone()[0] > 0
def insert_data(self, item):
# 插入数据
insert_sql = """
INSERT INTO exchange_rates
(currency_name, buying_rate, cash_buying_rate, selling_rate,
cash_selling_rate, middle_rate, pub_time, crawl_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
"""
self.cursor.execute(insert_sql, (
item['currency_name'],
item['buying_rate'],
item['cash_buying_rate'],
item['selling_rate'],
item['cash_selling_rate'],
item['middle_rate'],
item['pub_time'],
item['crawl_time']
))
self.conn.commit()
结果
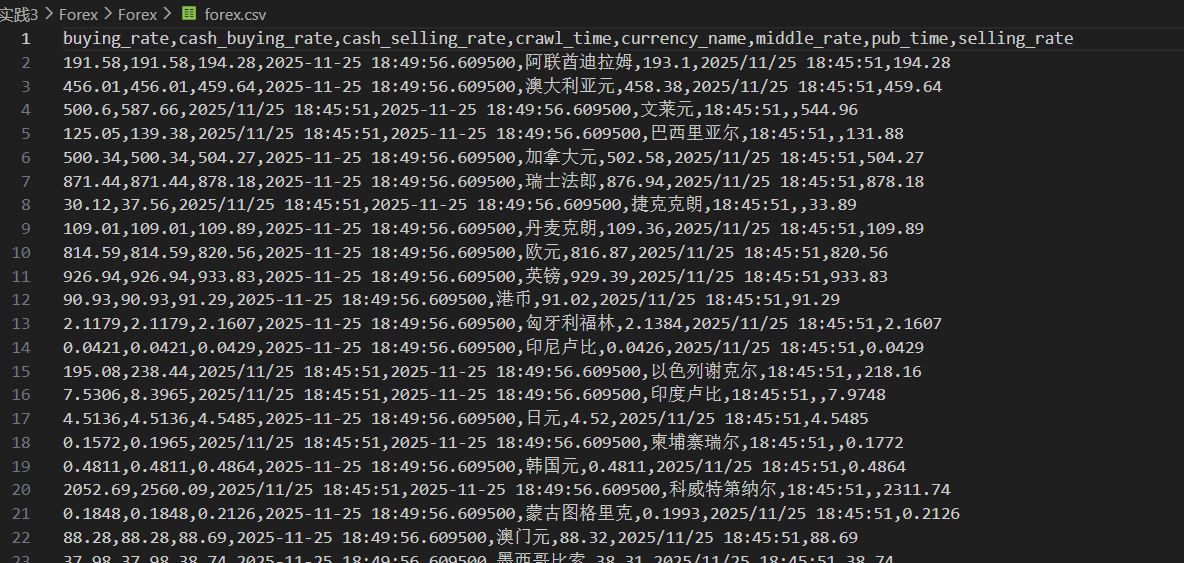
心得体会
链接https://gitee.com/wugao00882999/data-collection/tree/master/%E4%BD%9C%E4%B8%9A3/Forex

 浙公网安备 33010602011771号
浙公网安备 33010602011771号