
102302147傅乐宜作业2
在中国气象网给定城市集的7日天气预报,并保存在数据库
内容
核心代码
点击查看代码
import sqlite3
import requests
from bs4 import BeautifulSoup
class WeatherDB:
def __init__(self):
self.con = sqlite3.connect("weather.db")
self.cursor = self.con.cursor()
self.create_table()
def create_table(self):
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS weathers (
city TEXT,
date TEXT,
weather TEXT,
temp TEXT,
wind TEXT
)
''')
self.con.commit()
def insert_data(self, city, date, weather, temp, wind):
self.cursor.execute('''
INSERT INTO weathers (city, date, weather, temp, wind) VALUES (?, ?, ?, ?, ?)
''', (city, date, weather, temp, wind))
self.con.commit()
def close(self):
self.con.close()
def fetch_weather(city, code):
headers = {
'User-Agent': 'Mozilla/5.0'}
url = f"http://www.weather.com.cn/weather/{code}.shtml"
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
weather_list = soup.select("ul.t.clearfix li")[:7]
weather_data = []
for item in weather_list:
date = item.find('h1').text.strip()
weather = item.find('p', class_='wea').text.strip()
temp_p = item.find('p', class_='tem')
high_temp = temp_p.find('span').text.strip() if temp_p and temp_p.find('span') else ''
low_temp = temp_p.find('i').text.strip() if temp_p and temp_p.find('i') else ''
temp = f"{high_temp}/{low_temp}" if high_temp and low_temp else "无"
wind = item.find('p', class_='win').text.strip() if item.find('p', class_='win') else '无'
weather_data.append((city, date, weather, temp, wind))
return weather_data
def print_weather_data(weather_data):
for data in weather_data:
print(f"{data[0]},{data[1]},{data[2]},{data[3]},{data[4]}")
city_code = {"北京": "101010100", "上海": "101020100"}
weather_db = WeatherDB()
print("城市,日期,天气,温度,风力")
for city, code in city_code.items():
weather_data = fetch_weather(city, code)
print_weather_data(weather_data)
for data in weather_data:
weather_db.insert_data(*data)
weather_db.close()
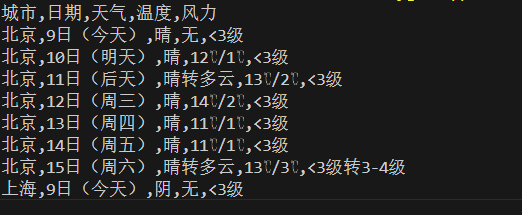
网页结构
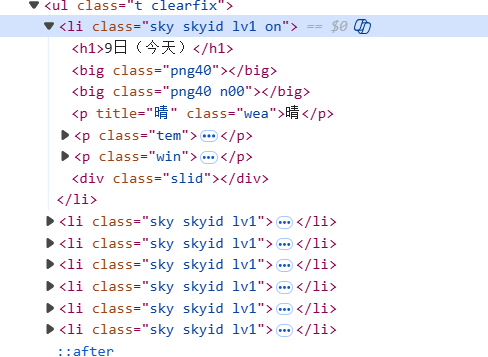
由图可知,天气列表,具体元素的所在。
心得体会
和之前的题目差不多,没遇到什么困难
2.用requests和json解析方法定向爬取股票相关信息,并存储在数据库中。
内容
核心代码
点击查看代码
import requests
import json
import re
import sqlite3
url = "https://push2.eastmoney.com/api/qt/clist/get"
params = {
"np": 1,
"fltt": 1,
"invt": 2,
"cb": "jQuery37106236146953184138_1761719786814",
"fs": "m:0+t:6+f:!2,m:0+t:80+f:!2,m:1+t:2+f:!2,m:1+t:23+f:!2,m:0+t:81+s:262144+f:!2",
"fields": "f12,f13,f14,f1,f2,f4,f3,f152,f5,f6,f7,f15,f18,f16,f17,f10,f8,f9,f23",
"fid": "f3",
"pn": 1,
"pz": 20,
"po": 1,
"dect": 1,
"ut": "fa5fd1943c7b386f172d6893dbfba10b",
"wbp2u": "|0|0|0|web",
"_": "1761719786819"
}
response = requests.get(url, params=params)
if response.status_code == 200:
content = response.text
pattern = r'^.*?\((.*)\);$'
match = re.match(pattern, content)
if match:
json_str = match.group(1)
data = json.loads(json_str)
if 'data' in data and 'diff' in data['data']:
stocks = data['data']['diff']
conn = sqlite3.connect('stocks.db')
cursor = conn.cursor()
# 创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY,
stock_code TEXT,
stock_name TEXT,
latest_price TEXT,
change_percentage TEXT
)
''')
print(f"{'序号':<4}{'股票代码':<10}{'股票名称':<10}{'最新报价':<10}{'涨跌幅':<10}")
for index, stock in enumerate(stocks, start=1):
daima = stock['f12']
name = stock['f14']
zuixin = str(stock['f2'])[:2] + '.' + str(stock['f2'])[2:]
zhangdiefu = str(stock['f3'])[:2] + '.' + str(stock['f3'])[2:] + '%'
print(f"{index:<4}{daima:<10}{name:<10}{zuixin:<10}{zhangdiefu:<10}")
cursor.execute('''
INSERT INTO stocks (stock_code, stock_name, latest_price, change_percentage)
VALUES (?, ?, ?, ?)
''', (daima, name, zuixin, zhangdiefu))
conn.commit()
conn.close()
else:
print("No stock data found")
else:
print("Failed to parse JSON")
else:
print("Failed to retrieve data.")
运行结果
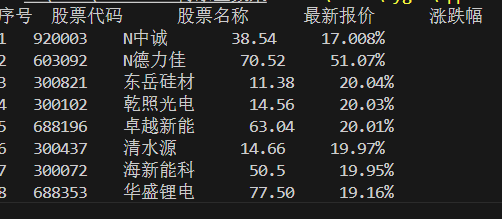
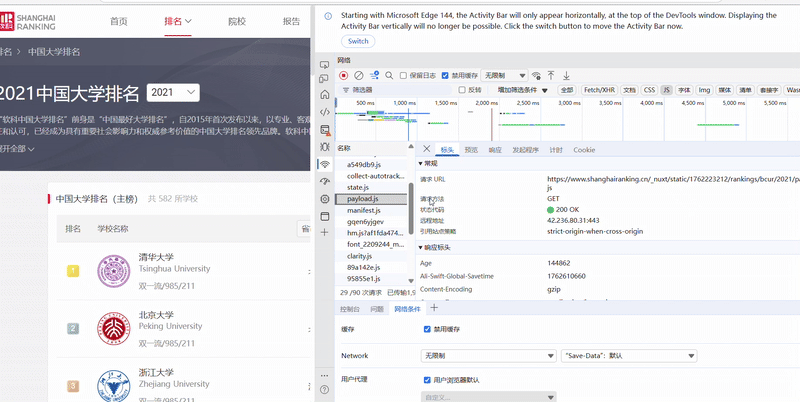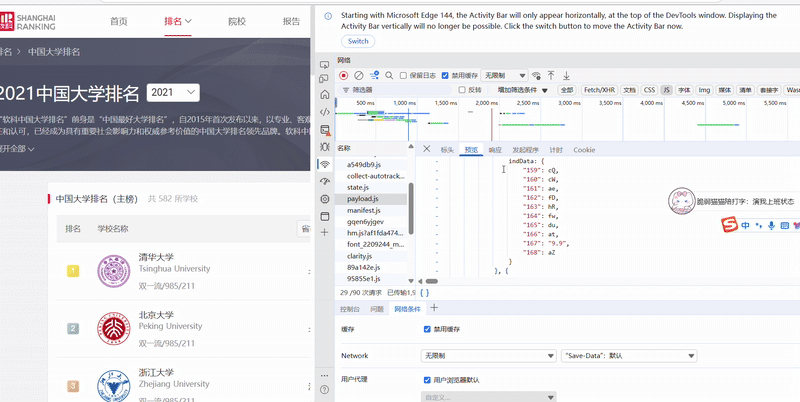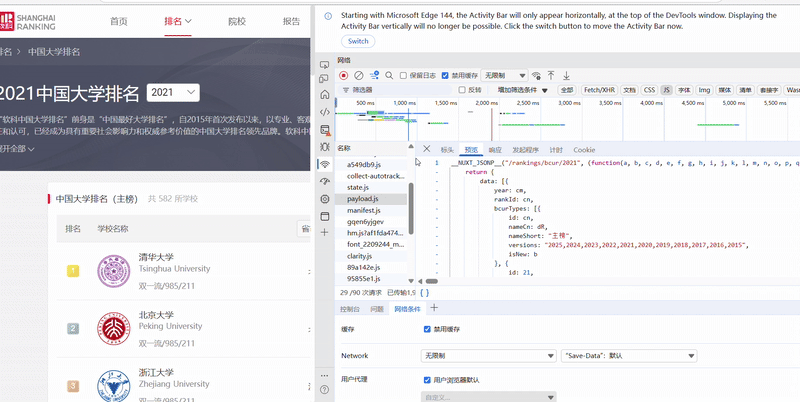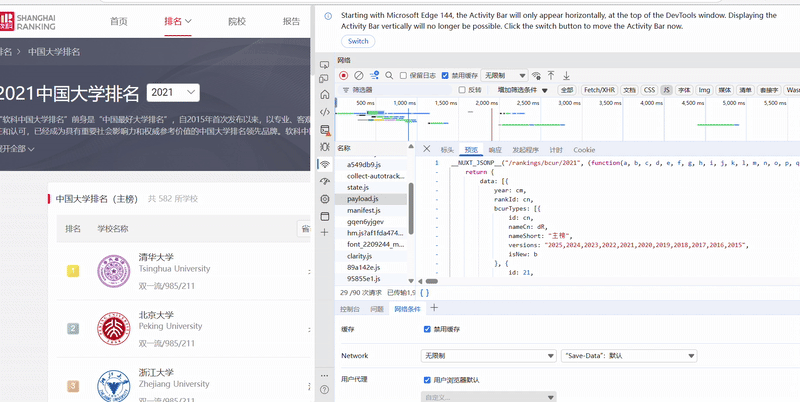
网页结构
通过检查页面,选取网络后刷新,点击JS后搜索get,便可得到如图内容


心得体会
学习到了可以通过调取api的方式爬取网页中的数据,同时数据的格式需要进行转换
爬取中国大学2021主榜所有院校信息,并存储在数据库中
内容
核心代码
点击查看代码
import json
import re
import requests
# 从URL下载JS文件
url = "https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/2021/payload.js"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
content = response.text
print("正在提取数据...")
pattern = r'univNameCn:"([^"]+)".*?province:([a-zA-Z]).*?univCategory:([a-zA-Z]).*?score:([\d.]+)'
matches = re.findall(pattern, content, re.DOTALL)
print(f"找到 {len(matches)} 所大学")
# 创建数据结构
universities = []
for match in matches:
universities.append({
'name': match[0],
'province_code': match[1],
'category_code': match[2],
'score': float(match[3])
})
# 省份和类型映射
province_map = {
'q': '北京', 'D': '上海', 'x': '浙江', 'k': '江苏', 'v': '湖北',
'u': '广东', 's': '陕西', 't': '四川', 'n': '山东', 'y': '安徽',
'w': '湖南', 'r': '辽宁', 'B': '黑龙江', 'C': '吉林', 'z': '江西',
'o': '河南', 'p': '河北', 'G': '山西', 'F': '福建', 'M': '重庆',
'N': '天津', 'H': '云南', 'I': '广西', 'J': '贵州', 'K': '甘肃',
'L': '内蒙古', 'O': '新疆', 'Y': '海南', 'az': '宁夏', 'aA': '青海',
'aB': '西藏'
}
category_map = {
'f': '综合', 'e': '理工', 'h': '师范', 'm': '农业', 'S': '林业'
}
# 按分数排序
universities_sorted = sorted(universities, key=lambda x: x['score'], reverse=True)
# 输出结果
print("\n| 排名 | 学校 | 省市 | 类型 | 总分 |")
print("|------|------|------|------|------|")
for idx, univ in enumerate(universities_sorted[:100], start=1):
province = province_map.get(univ['province_code'], univ['province_code'])
category = category_map.get(univ['category_code'], univ['category_code'])
print(f"| {idx} | {univ['name']} | {province} | {category} | {univ['score']} |")
结果

录屏
心得体会
在面对静态页面无法爬取全部内容时,可以通过寻找JS文件的方式来获取内容
Gitee链接
https://gitee.com/wugao00882999/data-collection/blob/master/ranking1.py
https://gitee.com/wugao00882999/data-collection/blob/master/stock1.py
https://gitee.com/wugao00882999/data-collection/blob/master/weather1.py
https://gitee.com/wugao00882999/data-collection/tree/master/%E4%BD%9C%E4%B8%9A1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号