

102302147傅乐宜作业1
1.用requests和BeautifulSoup库方法爬取大学排名信息
内容
核心代码:
点击查看代码
import urllib.request
from bs4 import BeautifulSoup
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
response = urllib.request.urlopen(url)
html_content = response.read()
soup = BeautifulSoup(html_content, 'html.parser')
table = soup.find('table') #定位排行表
rows = table.find_all('tr')#获取表的每一行
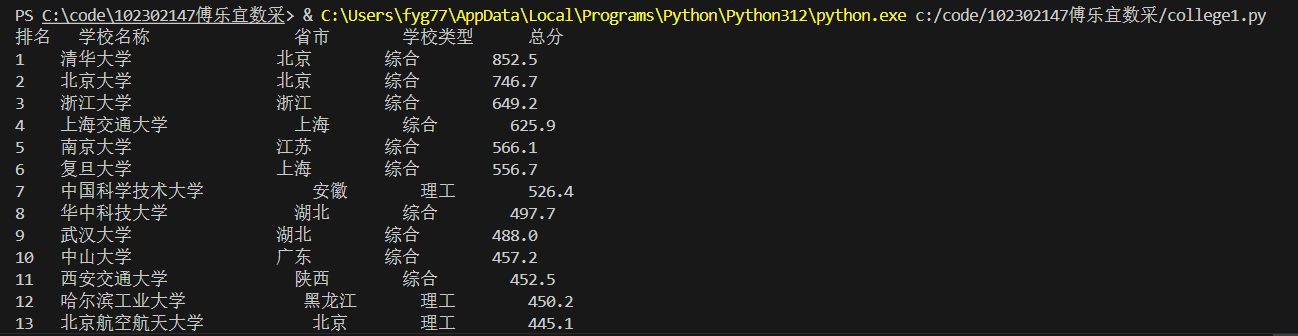
print(f"{'排名':<5}{'学校名称':<20}{'省市':<10}{'学校类型':<10}{'总分':<10}")
for row in rows[1:]:#第1个tr为表头,所以从1开始遍历
cols = row.find_all('td')#获取列
if cols:
rank = cols[0].get_text(strip=True)
university_name_span = cols[1].find('span', class_='name-cn')
university_name = university_name_span.get_text(strip=True) if university_name_span else cols[1].get_text(strip=True)
province_city = cols[2].get_text(strip=True)
university_type = cols[3].get_text(strip=True)
total_score = cols[4].get_text(strip=True)
print(f"{rank:<5}{university_name:<20}{province_city:<10}{university_type:<10}{total_score:<10}")
结果截图
心得体会
使用beautifulsoup可以很方便的找到元素,以及这种爬取方法只适用于静态页面,因此只有第一页的内容,如要翻页需要用selenium来模拟点击翻页
用requests和re库方法爬取商城书包
内容
核心代码:
点击查看代码
import requests
import re
def get_dangdang_bag():
url = 'https://search.dangdang.com/?key=%CA%E9%B0%FC&act=input'
response = requests.get(url)
response.encoding = "gbk"#注意编码
html_content = response.text
# 提取商品项
product_items = re.findall(r'<li[^>]*ddt-pit="\d+"[^>]*class="line\d+"[^>]*>.*?</li>', html_content, re.DOTALL)
# 解析并显示商品信息
print("序号 价格\t商品名称")
for index, item in enumerate(product_items, 1):
# 提取商品名称
name_match = re.search(r'title="([^"]*书包[^"]*)"', item)#确保商品有书包两字
name = name_match.group(1) if name_match else "unknow"
# 提取商品价格
price_match = re.search(r'<span class="price_n">\s*¥\s*([\d.]+)\s*</span>', item)
price = price_match.group(1) if price_match else "unknow"
print(f"{index:>2} ¥{price:>6} {name}")
if __name__ == "__main__":
get_dangdang_bag()

网页结构如图,li元素对应每个商品,a元素对应名称,span元素对应价格
结果截图如下

心得体会
要先选一个容易爬取,页面简洁的网页,用正则表达式匹配好麻烦,不如beautifulsoup
3.爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
内容
核心代码:
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import re
from urllib.parse import urljoin
def download_images(url, folder):
# 检查目标文件夹是否存在,如果不存在则创建
if not os.path.exists(folder):
os.makedirs(folder)
try:
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
except requests.exceptions.RequestException as e:
print(f"请求网页时出错:{e}")
return
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有图片链接
images = soup.find_all('img')
# 遍历图片链接并下载图片
for img in images:
# 获取图片的src属性
src = img.get('src')
if not src:
print("图片链接为空,跳过")
continue
# 处理相对路径
src = urljoin(url, src)
# 检查图片链接是否有效
try:
img_response = requests.head(src, allow_redirects=True)
if img_response.status_code != 200:
print(f"图片链接无效:{src}")
continue
except requests.exceptions.RequestException as e:
print(f"检查图片链接时出错:{e}")
continue
img_name = re.sub(r'[\\/*?:"<>|]', '_', src.split('/')[-1]) #替换非法字符
# 检查图片是否已下载
if os.path.exists(os.path.join(folder, img_name)):
print(f"图片已存在,跳过下载:{img_name}")
continue
# 下载图片
try:
img_response = requests.get(src, allow_redirects=True)
img_response.raise_for_status() # 检查请求是否成功
# 保存图片
with open(os.path.join(folder, img_name), 'wb') as f:
f.write(img_response.content)
print(f"下载图片:{img_name}")
except requests.exceptions.RequestException as e:
print(f"下载图片时出错:{e}")
def crawl_website(base_url, folder, num_pages):
# 遍历所有页面
for page in range(1, num_pages + 1):
# 构造翻页URL
if page == 1:
page_url = f"{base_url}.htm"
else:
page_url = f"{base_url}/{7-page}.htm"
print(f"正在爬取第 {page} 页:{page_url}")
download_images(page_url, folder)
print(f"第 {page} 页爬取完成。\n")
if __name__ == "__main__":
base_url = "https://news.fzu.edu.cn/yxfd" # 基础网址
folder = "downloaded_images" # 保存图片的文件夹
num_pages = 6 # 页数
crawl_website(base_url, folder, num_pages)

结果截图
心得体会
这种网页翻页的同时URL也跟着变,可以全部爬取,同时了解了图片在网页中是怎么存取的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号