





ThreadPoolExecute一共有四种构造函数:如下
| 参数 | 含义 |
|---|---|
| corePoolSize | 核心线程池大小 |
| maximumPoolSize | 线程池最大容量大小 |
| keepAliveTime | 线程池空闲时,线程存活的时间 |
| TimeUnit | 线程活动保持时间的单位 |
| BlockingQueue<Runnable> | 任务队列,用于保存等待执行的任务的阻塞队列 |
| ThreadFactory | 用于设置线程的工厂 |
| RejectedExecutionHandler | 饱和策略 |
corePoolSize:线程池中最少的线程数,一个项目组总得有corePoolSize人坚守阵地,都是签订劳动合同了,不能随便撤。
maximumPoolSize:当项目很忙时,就得加人,请其他项目组的人来帮忙。但是公司空间有限,最多只能加到maximumPoolSize个人。当项目闲了,就得撤人了,最多能撤到corePoolSize个人
keepAliveTime & unit:上面提到项目根据忙闲来增减人员,那在编程世界里,如何定义忙和闲呢?如果一个线程在keepAliveTime(时间数字)* unit(时间单位)时间内都没有执行任务,说明这个线程很闲。如果此时线程数大于corePoolSize,这个线程就要被回收了
workQueue:就是任务队列
threadFactory:自定义如果创建线程,例如给线程指定一个有意义的名字
handler:workQueue满了(排期满了),再提交任务,该怎么处理呢?这个就是处理策略,线程池提供了4种策略,你也可以实现RejectedExecutionHandler接口来自定义策略
| 类 | 策略 |
|---|---|
| AbortPolicy | 丢弃任务,抛运行时异常(默认的处理策略) |
| CallerRunsPolicy | 执行任务 |
| DiscardPolicy | 忽视,什么都不会发生 |
| DiscardOldestPolicy | 丢弃队列里最近的一个任务,并执行当前任务 |
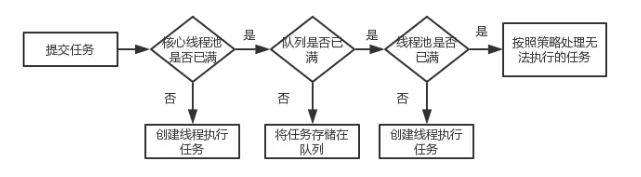
线程池的工作流程
可以参照一下源码理解一下下面的流程
1.线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行他们。
2.当调用execute()方法添加一个任务时,线程池会做如下判断:
a. 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务
b. 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列
c. 如果这时候队列满了,而且正在运行的线程数量小于maximunPoolSize,那么还是要创建非核心线程立刻运行这个任务
d. 如果队列满了,而且正在运行的线程数量大于或等于maximunPoolSize,那么线程池会抛出RejectedExecutionException
3.当一个线程完成任务时,它会从队列中取下一个任务来执行
4.当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小
可以用如下图来表示整体流程






到这里其实会有人疑问,那线程池具体使如何运行的
1.线程池在启动的时候就开始运行了,只不过一开始并没有线程也没有任务,当第一个任务进来时开开始创建核心线程
2.线程如何开始运行工作的,集中在Woker类上
Worker类
Worker类就是线程池中执行任务的类,主要源码和解释如下图:

所以Worker本身就是一个Runnable,它有两个属性thead、firstTask;那我们就可以来梳理一下整体的运行流程了:
线程池调用execute—>创建Worker(设置属性thead、firstTask)—>worker.thread.start()—>实际上调用的是worker.run()—>线程池的runWorker(worker)—>worker.firstTask.run()(如果firstTask为null就从等待队列中拉取一个)。
转了一大圈最终调用最开始传进来的任务的run方法,不过通过等待队列可以重复利用worker与worker中的线程,变化的只是firstTask;
总结
- 线程池的execute的作用是把任务放到等待队列中或者新建worker并把任务放到worker的firstTask,最后执行worker中的thread;
- Worker中的thread的start方法会执行Worker的run方法;
- Worker的run方法会调用线程池的runWorker方法;
- runWorker方法则是调用worker的firstTask的run方法,达到目的;
- 好处就是可以重复利用Worker与Worker中的thread,这也是线程池的优势。
3.当活跃线程(线程池中存在的线程)数小于核心线程数,此时依然是创建核心线程
4.当已经达到核心线程,但是小于最大线程,任务就以Woker添加到工作队列,getTask()方法会一直从线程池中获取任务处理
这里如果队列没满,依然是以核心线程处理
5.达到核心线程,工作队列慢,还没达到最大线程,就创建新的线程
- 判断是否允许核心线程超时或者当前活动线程数是否大于核心线程数(allowCoreThreadTimeOut默认为false)
-
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
- 判断当前活动线程数wc数是否大于最大线程数 || 允许超时 && 上次超时获取到的任务为null,接着判断如果wc>1,或者队列为空,则将工作线程数wc减1,并且返回一个null的task(此处就是判断是否为无用的线程的,如果无用,则在runWorker的processWorkerExit(w, completedAbruptly);这一行代码会把当前worker对象给销毁)
-
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) { if (compareAndDecrementWorkerCount(c)) return null; continue; }
- 根据timed来判断workQueue是超时等待获取队列任务,还是一直阻塞等待任务。
超时等待:当超过给定keepAliveTime时间还没有获取到任务时,则会返回null,此时Woker会被销毁
阻塞等待:一直阻塞,直到有任务进来

 浙公网安备 33010602011771号
浙公网安备 33010602011771号