


《SQL Server 2008从入门到精通》--20180723
1.架构
架构是一种独立于用户的逻辑分组,组中可以存储表,视图,存储过程等。假如表1在架构1中,表2在架构2中,用架构1的用户名登录时表2不可见。且未添加该架构的数据库不能被该架构的用户访问。
1.1.创建架构并在架构中创建表
执行如下语句
CREATE LOGIN hy WITH PASSWORD = '123456'
GO
--新建登录名
CREATE DATABASE schematest
GO
--新建数据库
USE schematest
GO
CREATE USER u_for_test FOR LOGIN hy
GO
CREATE SCHEMA dbo_Schema
go
--在schematest数据库下添加dbo_Schema
CREATE TABLE T1(id INT,NAME VARCHAR(20))
go
CREATE TABLE dbo_Schema.T2(Nid int,DD datetime)
go
GRANT SELECT ON SCHEMA :: dbo_Schema TO u_for_test;
--给u_for_test赋予SELECT权限
--重新使用hy登录即可。
用hy登录,打开未添加dbo_Schema架构的数据库,出现如下提示
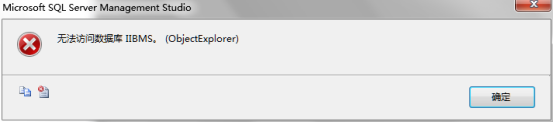
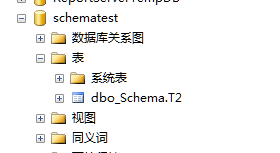
打开schematest数据库,展开表,dbo_Schema下的T2表可见,非dbo_Schema架构下的T1表不可见。
1.2.删除架构
删除架构前必须删除或者移动该架构的所有对象,不然删除操作将会失败。如执行下列语句
DROP SCHEMA dbo_Schema
GO
结果如图所示

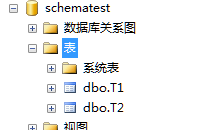
此时要将T2表删除或者移动到其他架构才能成功删除dbo_Schema
1.3.修改表的架构
如图所示,右键表名——设计——右侧属性栏中修改表的架构

如图所示,当把T2表所引用的架构修改为dbo后,可继续删除架构dbo_Schema操作。就能成功删除dbo.Schema
2.视图
视图是数据库中原始数据的一种变换,是查看表数据的一种方式,视图是一种逻辑对象,是虚拟的表,是一串SELECT语句,并不是真实的表。
2.1.新建视图
示例1:利用student表和class_student表的数据新建视图class_01,记录01班学生详细信息
Student表的数据如图所示

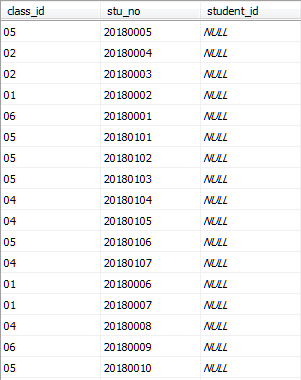
Class_student表的数据如图所示
执行下列语句新建视图class_01
CREATE VIEW class_01
AS
SELECT class_student.stu_no,class_id,stu_name,stu_sex,stu_age,stu_addr,stu_native_place,stu_birthday,stu_enter_score,stu_phone,stu_father_name,stu_mather_name
FROM class_student INNER JOIN student
ON class_student.stu_no=student.stu_no
WHERE class_id='01'
视图class_01的数据如图所示

注:视图只是一个SELECT语句,数据根据基表的数据改变而自动改变。
2.2.使用视图修改数据
示例2:有course表数据,基于course表新建视图coursetest,列名为course_id,course_name,credits。
Course表数据如图所示
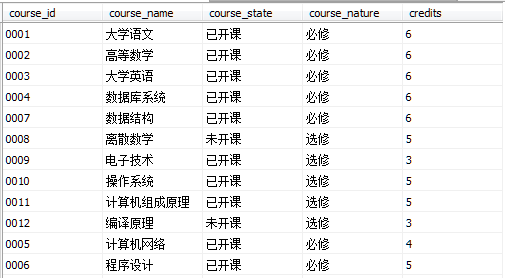
执行下列语句新建coursetest视图
CREATE VIEW coursetest
AS
SELECT course.course_id,course_name,credits FROM course
Coursetest视图数据如图所示
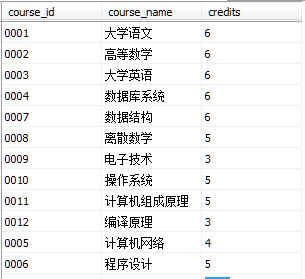
在coursetest视图中插入一行course_id为“0013”的数据
INSERT INTO coursetest(course_id,course_name,credits)
VALUES('0013','嵌入式系统开发','5')
Course表数据如图所示
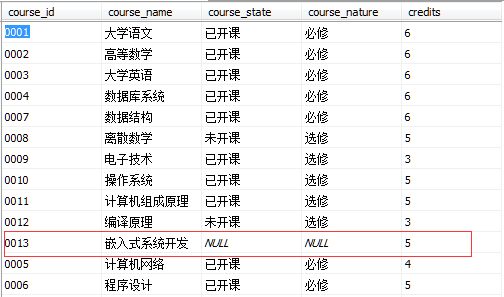
这行数据也被插入到course表中,在基于单张表的视图中可以通过增删改视图数据来更新基表数据,对基于多张表的视图不可更新。
2.3.删除视图
DROP VIEW coursetest
3.索引
3.1.聚集索引
聚集索引数据按照索引的顺序排序,查询速度比非聚集索引快。当插入数据时,按索引顺序对数据重新排序。打个比方,新华字典中按拼音查字就是聚集索引,找到了矮字就能按顺序查下去找到爱字。一个表只能有1个聚集索引
如果一个表在创建主键时没有聚集索引也没指定唯一非聚集索引,会对PRIMARY KEY字段自动创建聚集索引
3.2.非聚集索引
非聚集索引不按照索引顺序排序,制定了表中数据的逻辑顺序,采用指针指向数据页的形式。一个表可以拥有多个非聚集索引。打个比方,新华字典中按笔画查字就是非聚集索引,笔画索引顺序和字的顺序不一致,依靠指针来指向数据页。
3.3.创建索引
示例3:设置IndexDemo1表的id字段为PRIMARY KEY,看系统是否自动为该字段创建了聚集索引。执行下列语句
CREATE DATABASE IndexDemo
USE IndexDemo
CREATE TABLE IndexDemo1(
id INT NOT NULL,
A CHAR(10),
B VARCHAR(10),
CONSTRAINT PK_id PRIMARY KEY(id)
)
结果如图所示
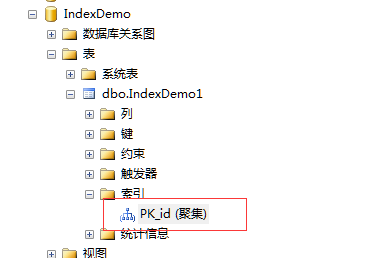
聚集索引以PRIMARY KEY的键名为索引名。
执行下列语句删除PRIMARY KEY
ALTER TABLE IndexDemo1
DROP CONSTRAINT PK_id
聚集索引PK_id也同时被删除了。
示例4:在示例3的IndexDemo1表中,插入几行数据,添加聚集索引,观察数据顺序,添加非聚集索引,观察数据顺序
IndexDemo1的数据如图所示(未添加索引)
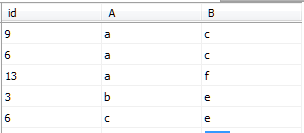
执行下列语句,为id列添加聚集索引
CREATE CLUSTERED INDEX clustered_index ON IndexDemo1(id)
添加聚集索引clustered_index后IndexDemo1表的数据如图所示
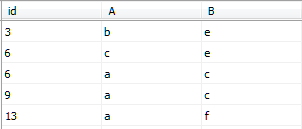
可以发现,表中数据按照id列从小到大进行排序。
此时在表中插入一条数据
INSERT INTO IndexDemo1(id,A,B)VALUES('7','g','f')
表中数据排序如图所示
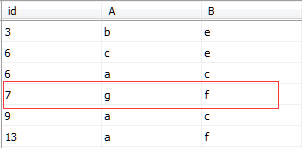
执行下列代码删除聚集索引clustered_index并对id列创建非聚集索引nonclustered_index
DROP INDEX IndexDemo1.clustered_index
GO--删除聚集索引clustered_index
CREATE NONCLUSTERED INDEX nonclustered_index ON IndexDemo1(id)
GO--创建非聚集索引nonclustered_index
表中的数据如图所示
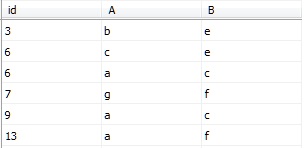
此时添加一条记录
INSERT INTO IndexDemo1(id,A,B)VALUES('8','g','f')
表中的数据如图所示
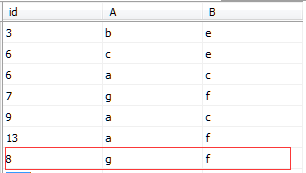
在未创建聚集索引,创建了非聚集索引的表中新插入的数据是添加在末行的。
3.4.修改索引
当数据更改时,有必要重新生成索引,重新组织索引或者禁止索引。
- 重新生成索引表示删除索引,并且重新创建索引。这样可以根据指定的填充度压缩页来删除碎片,回收磁盘空间,重新排序索引。
- 重新组织索引对索引碎片的整理程度低于重新生成索引。
- 禁止索引表示禁止用户访问索引。
示例5:对IndexDemo1表中的id列重新生成索引,重新组织索引和禁止索引。
执行下列语句
ALTER INDEX nonclustered_index ON IndexDemo1 REBUILD
--重新生成索引
ALTER INDEX nonclustered_index ON IndexDemo1 REORGANIZE
--重新组织索引
ALTER INDEX nonclustered_index ON IndexDemo1 DISABLE
--禁用索引
注:禁用索引后重新启用索引,只需重新生成索引就可以了。
3.5.查看索引
可以利用目录视图和系统函数查看索引。这样的函数有很多,不一一列举了。

3.6.查看索引碎片
右键索引名,在属性——碎片中查看碎片
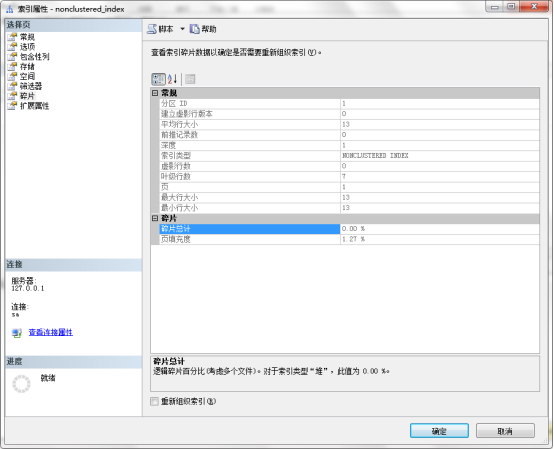
3.7.查看统计信息
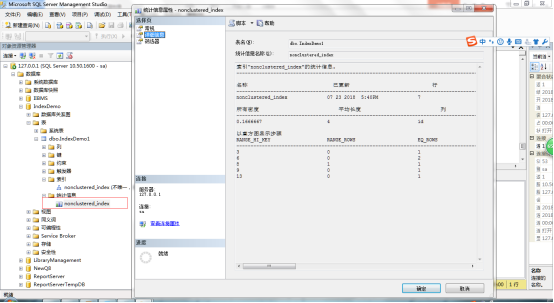
在表下的统计信息中,右键点击要查看统计信息的索引名,点击详细信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号