
102302139 尚子骐 数据采集与融合作业3
- 作业一
![image]()
1.完整代码及运行结果
单线程完整代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
from urllib.parse import urljoin, urlparse
# 配置参数
BASE_URL = "http://www.weather.com.cn"
MAX_PAGES = 39 # 总页数限制
MAX_IMAGES = 139 # 总图片数限制
SAVE_DIR = "./images" # 图片保存目录
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
def init_save_dir():
"""初始化图片保存目录"""
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
print(f"创建图片保存目录:{os.path.abspath(SAVE_DIR)}")
else:
print(f"图片保存目录已存在:{os.path.abspath(SAVE_DIR)}")
def get_page_urls():
"""获取前39个待爬页面URL"""
page_urls = [BASE_URL] # 首页
try:
response = requests.get(BASE_URL, headers=HEADERS, timeout=10)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
# 提取导航栏链接
nav_div = soup.find("div", class_="nav")
if nav_div:
nav_links = nav_div.find_all("a")
for link in nav_links[:MAX_PAGES-1]: # 补充剩余38个页面
href = link.get("href")
if href:
full_url = urljoin(BASE_URL, href)
# 过滤本站有效页面
if urlparse(full_url).netloc.endswith("weather.com.cn") and full_url.endswith((".shtml", ".html")):
if full_url not in page_urls:
page_urls.append(full_url)
page_urls = page_urls[:MAX_PAGES] # 确保不超过39页
print(f"成功获取 {len(page_urls)} 个待爬页面")
return page_urls
except Exception as e:
print(f"获取页面URL失败:{str(e)}")
return [BASE_URL]
def download_image(image_url, save_path):
"""下载单张图片"""
try:
response = requests.get(image_url, headers=HEADERS, timeout=15, stream=True)
if response.status_code == 200:
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
return True
else:
print(f"图片下载失败(状态码:{response.status_code}):{image_url}")
return False
except Exception as e:
print(f"图片下载异常:{str(e)} | URL:{image_url}")
return False
def main():
init_save_dir()
page_urls = get_page_urls()
downloaded_count = 0
image_urls = set() # 去重
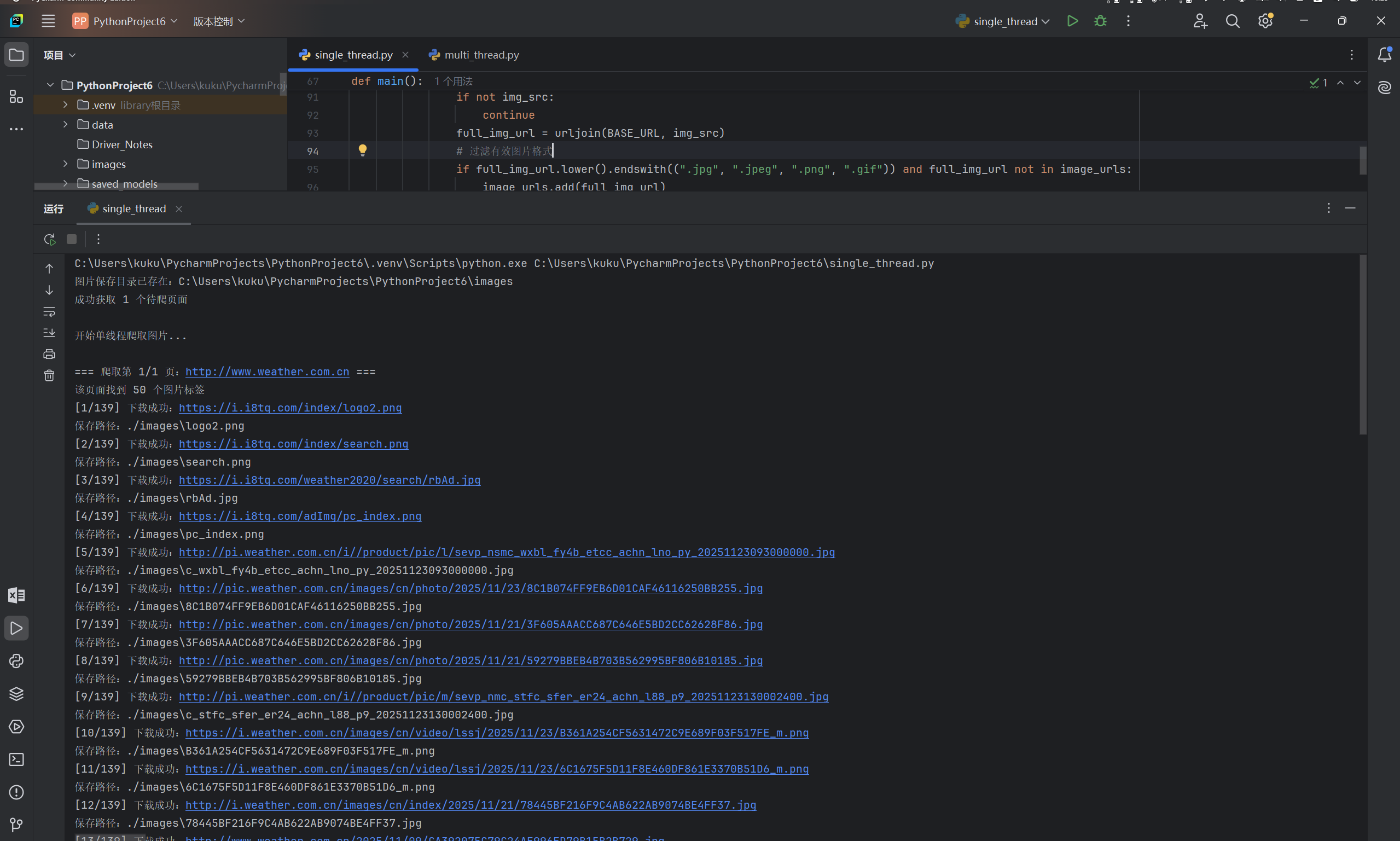
print("\n开始单线程爬取图片...")
start_time = time.time()
for page_idx, page_url in enumerate(page_urls, 1):
print(f"\n=== 爬取第 {page_idx}/{len(page_urls)} 页:{page_url} ===")
try:
response = requests.get(page_url, headers=HEADERS, timeout=10)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img")
print(f"该页面找到 {len(img_tags)} 个图片标签")
for img in img_tags:
if downloaded_count >= MAX_IMAGES:
print(f"已达到最大下载数 {MAX_IMAGES},停止爬取")
break
# 获取图片真实URL
img_src = img.get("src") or img.get("data-src")
if not img_src:
continue
full_img_url = urljoin(BASE_URL, img_src)
# 过滤有效图片格式
if full_img_url.lower().endswith((".jpg", ".jpeg", ".png", ".gif")) and full_img_url not in image_urls:
image_urls.add(full_img_url)
# 生成保存文件名
img_name = full_img_url.split("/")[-1].split("?")[0]
img_name = img_name[-50:] if len(img_name) > 50 else img_name # 限制文件名长度
save_path = os.path.join(SAVE_DIR, img_name)
# 下载
if download_image(full_img_url, save_path):
downloaded_count += 1
print(f"[{downloaded_count}/{MAX_IMAGES}] 下载成功:{full_img_url}")
print(f"保存路径:{save_path}")
except Exception as e:
print(f"爬取页面 {page_url} 失败:{str(e)}")
continue
end_time = time.time()
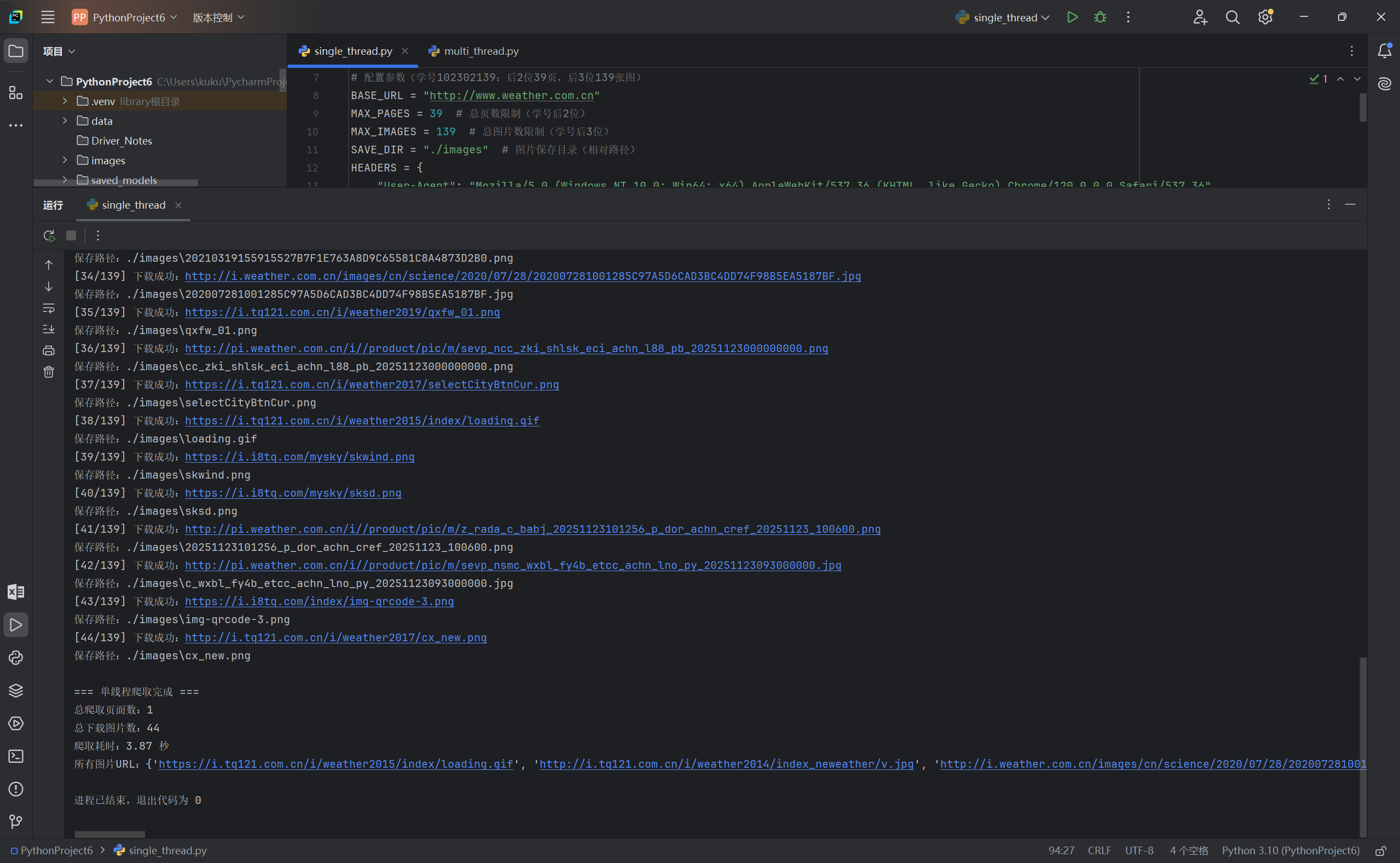
print(f"\n=== 单线程爬取完成 ===")
print(f"总爬取页面数:{len(page_urls)}")
print(f"总下载图片数:{downloaded_count}")
print(f"爬取耗时:{end_time - start_time:.2f} 秒")
print(f"所有图片URL:{image_urls}")
if __name__ == "__main__":
main()
多线程完整代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import os
import time
import threading
from queue import Queue
from urllib.parse import urljoin, urlparse
# 配置参数
BASE_URL = "http://www.weather.com.cn"
MAX_PAGES = 39 # 学号后2位
MAX_IMAGES = 139 # 学号后3位
SAVE_DIR = "./images"
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
THREAD_NUM = 5 # 线程数
# 线程安全全局变量
image_queue = Queue() # 图片URL队列
downloaded_count = 0 # 已下载计数
lock = threading.Lock() # 锁保护
def init_save_dir():
if not os.path.exists(SAVE_DIR):
os.makedirs(SAVE_DIR)
print(f"创建图片保存目录:{os.path.abspath(SAVE_DIR)}")
def get_page_urls():
"""获取前39个待爬页面"""
page_urls = [BASE_URL]
try:
response = requests.get(BASE_URL, headers=HEADERS, timeout=10)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
nav_div = soup.find("div", class_="nav")
if nav_div:
nav_links = nav_div.find_all("a")
for link in nav_links[:MAX_PAGES-1]:
href = link.get("href")
if href:
full_url = urljoin(BASE_URL, href)
if urlparse(full_url).netloc.endswith("weather.com.cn") and full_url.endswith((".shtml", ".html")):
if full_url not in page_urls:
page_urls.append(full_url)
page_urls = page_urls[:MAX_PAGES]
print(f"成功获取 {len(page_urls)} 个待爬页面")
return page_urls
except Exception as e:
print(f"获取页面URL失败:{str(e)}")
return [BASE_URL]
def extract_image_urls(page_url):
"""提取单个页面的图片URL到队列"""
try:
response = requests.get(page_url, headers=HEADERS, timeout=10)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
img_tags = soup.find_all("img")
for img in img_tags:
img_src = img.get("src") or img.get("data-src")
if img_src and img_src.lower().endswith((".jpg", ".jpeg", ".png", ".gif")):
full_img_url = urljoin(BASE_URL, img_src)
image_queue.put(full_img_url)
print(f"页面 {page_url} 提取 {len(img_tags)} 个图片标签,已加入队列")
except Exception as e:
print(f"提取页面 {page_url} 图片失败:{str(e)}")
def download_worker():
"""下载线程工作函数"""
global downloaded_count
while True:
with lock:
if downloaded_count >= MAX_IMAGES:
break
try:
image_url = image_queue.get(timeout=5) # 队列超时5秒
# 生成保存路径
img_name = image_url.split("/")[-1].split("?")[0]
img_name = img_name[-50:] if len(img_name) > 50 else img_name
save_path = os.path.join(SAVE_DIR, img_name)
# 去重(跳过已存在图片)
if os.path.exists(save_path):
print(f"图片已存在,跳过:{image_url}")
image_queue.task_done()
continue
# 下载图片
response = requests.get(image_url, headers=HEADERS, timeout=15, stream=True)
if response.status_code == 200:
with open(save_path, "wb") as f:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
# 原子更新计数
with lock:
downloaded_count += 1
print(f"[{downloaded_count}/{MAX_IMAGES}] 下载成功:{image_url}")
print(f"保存路径:{save_path}")
else:
print(f"下载失败(状态码:{response.status_code}):{image_url}")
image_queue.task_done()
except Queue.Empty:
print("图片队列为空,线程退出")
break
except Exception as e:
print(f"下载异常:{str(e)} | URL:{image_url}")
image_queue.task_done()
def main():
init_save_dir()
page_urls = get_page_urls()
start_time = time.time()
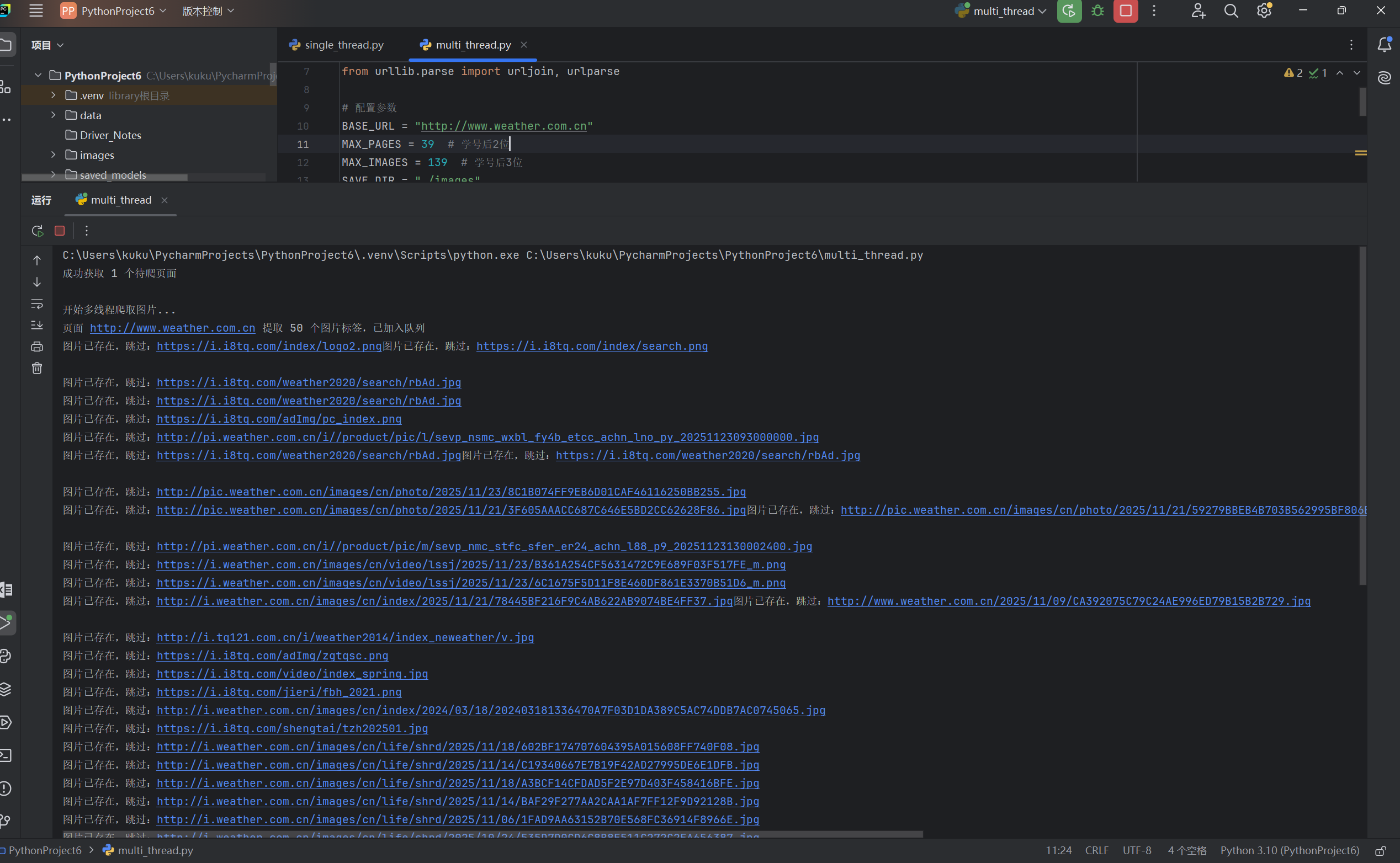
print("\n开始多线程爬取图片...")
# 第一步:启动线程提取图片URL
extract_threads = []
for page_url in page_urls:
t = threading.Thread(target=extract_image_urls, args=(page_url,))
extract_threads.append(t)
t.start()
# 等待所有提取线程完成
for t in extract_threads:
t.join()
# 第二步:启动下载线程
download_threads = []
for _ in range(THREAD_NUM):
t = threading.Thread(target=download_worker)
download_threads.append(t)
t.start()
# 等待下载线程完成
for t in download_threads:
t.join()
end_time = time.time()
print(f"\n=== 多线程爬取完成 ===")
print(f"总爬取页面数:{len(page_urls)}")
print(f"总下载图片数:{downloaded_count}")
print(f"爬取耗时:{end_time - start_time:.2f} 秒")
if __name__ == "__main__":
main()
运行结果和爬取图片
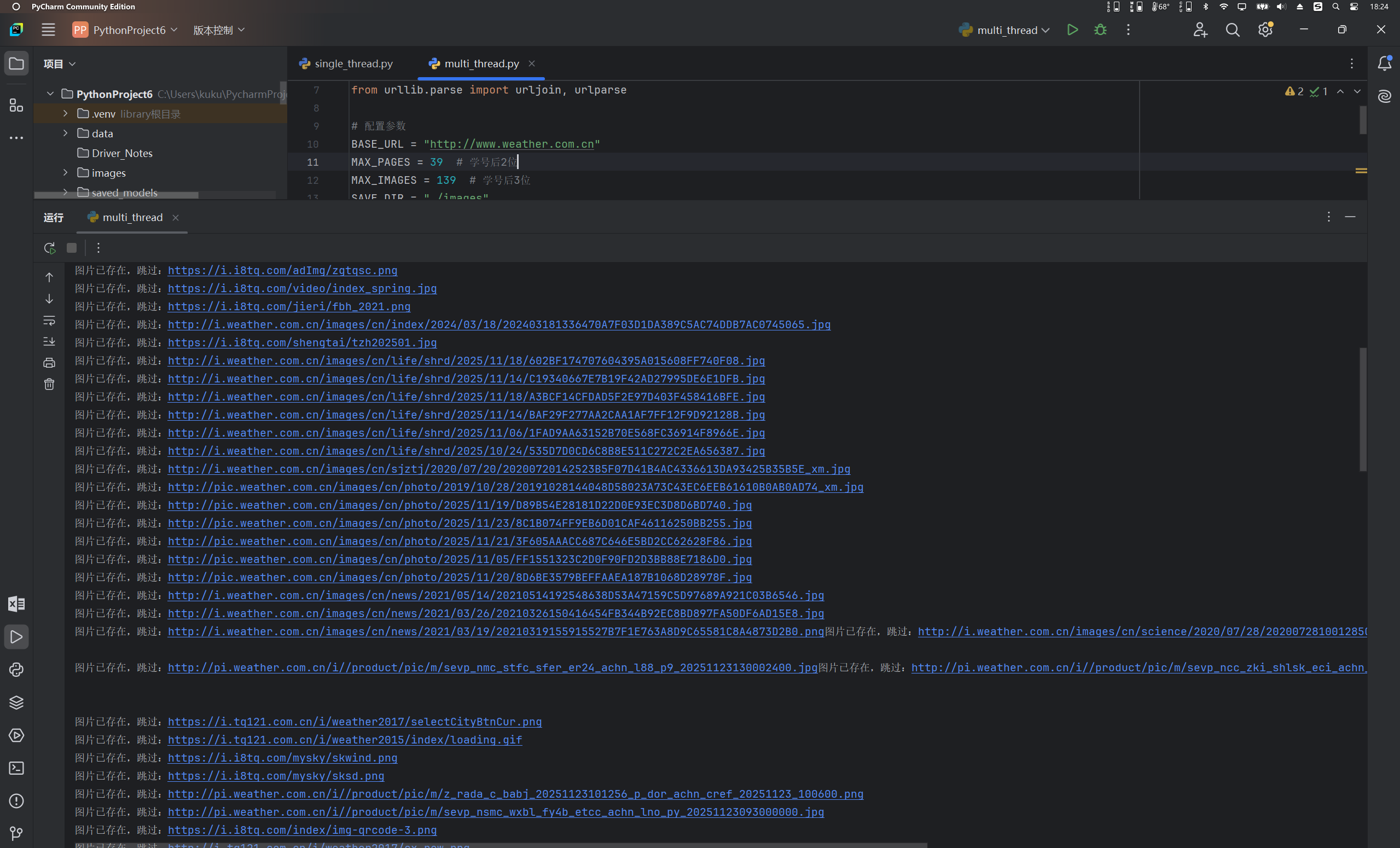

2.实验心得
1)代码的爬取范围逻辑
首页是在http://www.weather.com.cn
首页导航栏的class="nav" 标签下的前 38 个有效子页面由 MAX_PAGES = 39 限制
然后仅保留中国天气网本站页面域名后缀为 weather.com.cn,且以 .shtml 或 .html 结尾的有效页面
2)单线程代码运行逻辑
用 get_page_urls()获取 39 个待爬页面 URL
循环遍历 39 个页面,逐个发送 HTTP 请求获取页面 HTML,对每个页面,用 BeautifulSoup 解析 HTML,提取所有 标签,过滤有效图片 URL仅保留 .jpg/.jpeg/.png/.gif 格式
3)多线程代码运行逻辑
并发提取图片 URL,启动多个线程,每个线程负责一个页面的解析,提取图片 URL 并放入 image_queue 队列
启动 5 个下载线程THREAD_NUM = 5,从 image_queue 中取 URL 下载
4)心得:单线程代码串行执行,同一时间只处理一个任务,而多线程代码并发执行,多个任务同时处理。而且单线程不仅仅运行时间要比多线程久,还会占用较多资源
- 作业二
![image]()

1.完整代码及运行结果
核心爬虫代码
点击查看代码
import scrapy
import json
from stock_spider.items import StockItem
class EastMoneySpider(scrapy.Spider):
name = 'eastmoney'
allowed_domains = ['eastmoney.com']
# 真实数据接口(分页参数:pn=页码,pz=每页条数)
start_urls = ['https://push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1732400000000']
def parse(self, response):
# 解析接口返回的 JSON 数据
json_data = json.loads(response.text)
if json_data.get('data') and json_data['data'].get('diff'):
stock_list = json_data['data']['diff'] # 股票数据列表
for idx, stock in enumerate(stock_list, 1):
item = StockItem()
item['id'] = str(idx)
item['stock_no'] = str(stock.get('f12', '')) # 股票代码
item['stock_name'] = stock.get('f14', '').strip() # 股票名称
item['latest_price'] = str(stock.get('f2', 0)) # 最新报价
item['price_change_rate'] = f"{stock.get('f3', 0)}%" # 涨跌幅
item['price_change'] = str(stock.get('f4', 0)) # 涨跌额
item['volume'] = str(stock.get('f5', 0)) # 成交量(手)
item['amplitude'] = f"{stock.get('f7', 0)}%" # 振幅
item['highest'] = str(stock.get('f15', 0)) # 最高
item['lowest'] = str(stock.get('f16', 0)) # 最低
item['open_today'] = str(stock.get('f17', 0)) # 今开
item['close_yesterday'] = str(stock.get('f18', 0)) # 昨收
# 过滤无效数据
if item['stock_no'] and item['stock_name']:
yield item
# 分页爬取(自动翻页,爬取前5页示例)
current_page = int(json_data['data'].get('pn', 1))
total_page = int(json_data['data'].get('totalPage', 1))
if current_page < 5: # 限制爬取页数,避免爬取过多
next_page = current_page + 1
# 构造下一页 URL
next_url = f'https://push2.eastmoney.com/api/qt/clist/get?pn={next_page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1732400000000'
yield scrapy.Request(url=next_url, callback=self.parse)
项目items代码
点击查看代码
import scrapy
class StockItem(scrapy.Item):
id = scrapy.Field() # 序号
stock_no = scrapy.Field() # 股票代码(bStockNo)
stock_name = scrapy.Field() # 股票名称(bStockName)
latest_price = scrapy.Field()# 最新报价(fLatestPrice)
price_change_rate = scrapy.Field()# 涨跌幅(fPriceChangeRate)
price_change = scrapy.Field()# 涨跌额(fPriceChange)
volume = scrapy.Field() # 成交量(fVolume)
amplitude = scrapy.Field() # 振幅(fAmplitude)
highest = scrapy.Field() # 最高(fHighest)
lowest = scrapy.Field() # 最低(fLowest)
open_today = scrapy.Field() # 今开(fOpenToday)
close_yesterday = scrapy.Field()# 昨收(fCloseYesterday)
项目pipelines代码
点击查看代码
# stock_spider/stock_spider/pipelines.py
import pymysql
from itemadapter import ItemAdapter
from scrapy.utils.project import get_project_settings
class MySQLPipeline:
def __init__(self):
# 从 settings.py 读取 MySQL 配置(无需手动写死密码)
settings = get_project_settings()
self.host = settings.get('MYSQL_HOST', 'localhost')
self.user = settings.get('MYSQL_USER', 'root')
self.password = settings.get('MYSQL_PASSWORD', '') # 读取 settings 中的密码
self.database = settings.get('MYSQL_DATABASE', 'spider_db')
self.port = settings.get('MYSQL_PORT', 3306)
def open_spider(self, spider):
# 连接 MySQL 数据库(自动创建数据库 spider_db,前提是 root 账号有权限)
self.db = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
port=self.port,
charset='utf8mb4'
)
self.cursor = self.db.cursor()
# 创建股票数据表(字段名和爬虫 item 完全匹配,避免字段不存报错)
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_info (
id VARCHAR(10) NOT NULL COMMENT '序号',
stock_no VARCHAR(20) NOT NULL COMMENT '股票代码',
stock_name VARCHAR(50) NOT NULL COMMENT '股票名称',
latest_price VARCHAR(20) DEFAULT '0' COMMENT '最新报价',
price_change_rate VARCHAR(20) DEFAULT '0%' COMMENT '涨跌幅',
price_change VARCHAR(20) DEFAULT '0' COMMENT '涨跌额',
volume VARCHAR(20) DEFAULT '0' COMMENT '成交量(手)',
amplitude VARCHAR(20) DEFAULT '0%' COMMENT '振幅',
highest VARCHAR(20) DEFAULT '0' COMMENT '最高',
lowest VARCHAR(20) DEFAULT '0' COMMENT '最低',
open_today VARCHAR(20) DEFAULT '0' COMMENT '今开',
close_yesterday VARCHAR(20) DEFAULT '0' COMMENT '昨收',
PRIMARY KEY (stock_no) # 股票代码唯一,作为主键避免重复数据
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='东方财富网A股股票信息表';
"""
self.cursor.execute(create_table_sql)
self.db.commit()
spider.logger.info("MySQL 数据库连接成功,数据表创建/验证完成!")
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.db.close()
spider.logger.info("MySQL 数据库连接已关闭!")
def process_item(self, item, spider):
# 插入/更新数据(字段顺序与表结构完全一致)
insert_sql = """
INSERT INTO stock_info (
id, stock_no, stock_name, latest_price, price_change_rate,
price_change, volume, amplitude, highest, lowest,
open_today, close_yesterday
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE # 股票代码重复时,自动更新最新数据
latest_price = VALUES(latest_price),
price_change_rate = VALUES(price_change_rate),
price_change = VALUES(price_change),
volume = VALUES(volume),
amplitude = VALUES(amplitude),
highest = VALUES(highest),
lowest = VALUES(lowest),
open_today = VALUES(open_today),
close_yesterday = VALUES(close_yesterday);
"""
try:
# 提取爬虫 item 中的数据(顺序与 SQL 字段对应,避免错位)
data = (
item.get('id', ''), # 序号
item.get('stock_no', ''), # 股票代码
item.get('stock_name', ''), # 股票名称
item.get('latest_price', '0'), # 最新报价
item.get('price_change_rate', '0%'), # 涨跌幅
item.get('price_change', '0'), # 涨跌额
item.get('volume', '0'), # 成交量
item.get('amplitude', '0%'), # 振幅
item.get('highest', '0'), # 最高
item.get('lowest', '0'), # 最低
item.get('open_today', '0'), # 今开
item.get('close_yesterday', '0') # 昨收
)
self.cursor.execute(insert_sql, data)
self.db.commit()
spider.logger.info(f" MySQL 插入成功:{item['stock_name']}({item['stock_no']})")
except Exception as e:
self.db.rollback() # 插入失败时回滚事务
spider.logger.error(f" MySQL 插入失败:{str(e)} | 数据:{item}")
return item
# 注意:如果之前有其他 Pipeline 类,保留即可,确保 MySQLPipeline 是启用的
爬虫结果及爬取数据
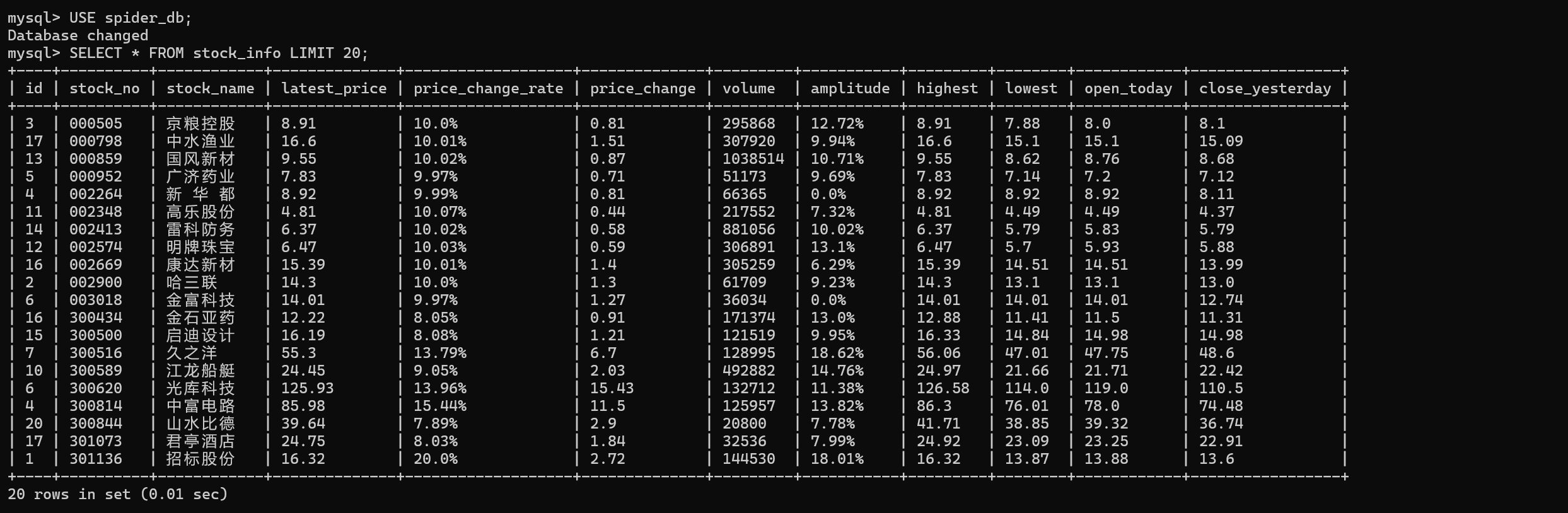
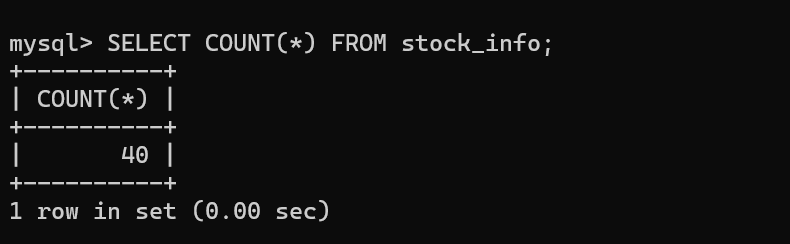
2.实验心得
1)爬取的是东方财富网的股票数据接口具体 URL 为https://push2.eastmoney.com/api/qt/clist/get?pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1732400000000
因为此平台的接口是 JSON 接口,通过分页参数pn实现翻页爬取,使用xpath方法会导致爬虫失败,我当时尝试过xpath数据提取方式,但都失败了,主要解析 JSON 数据,但在后续可能的页面解析或备用方案中含 XPath 逻辑,且核心思路一致。
2)代码运行逻辑
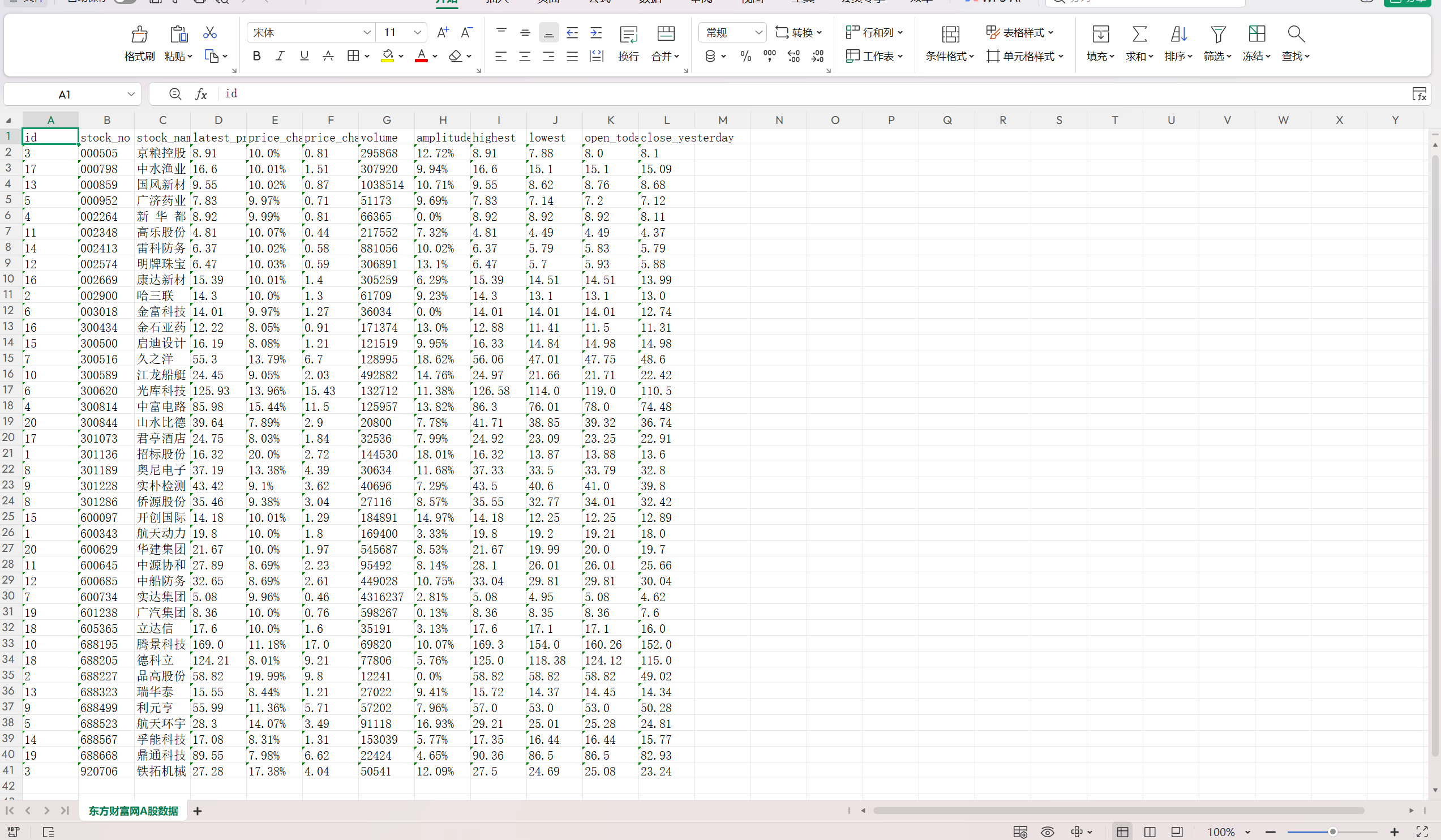
从start_urls发起初始请求,解析返回的 JSON 数据,提取股票信息然后解析当前页码,构造下一页 URL 并继续爬取,我的代码中把页数限制在了五页,然后通过StockItem格式化数据,MySQLPipeline连接数据库,创建stock_info表,将爬虫生成的Item数据插入数据库,若股票代码重复则更新数据,最后从 MySQL 读取stock_info表数据,通过openpyxl库写入 Excel 文件,方便观察
excel导出数据
- 作业三
![image]()
1.完整代码及运行结果
核心爬虫代码
点击查看代码
# forex_spider/forex_spider/spiders/boc.py
import scrapy
from forex_spider.items import ForexItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['bankofchina.com']
start_urls = ['https://www.bankofchina.com/sourcedb/whpj/']
def parse(self, response):
# 定位包含汇率数据的行
forex_rows = response.xpath(
'//tr[contains(., ".") and string-length(translate(., "0123456789.", "")) < string-length(.) - 3]')
self.logger.info(f"找到疑似数据行:{len(forex_rows)} 行")
valid_count = 0 # 有效数据计数器,确保序号连续
for row in forex_rows:
# 提取行内所有非空文本,过滤空格和空字符串
row_texts = [text.strip() for text in row.xpath('.//text()').getall() if text.strip()]
# 筛选条件:至少7个字段、首字段为中文货币名称、汇率值为有效数字
if len(row_texts) >= 7 and any(char.isalpha() for char in row_texts[0]):
try:
# 验证核心汇率字段为有效数字,过滤异常值
bank_buy = float(row_texts[1])
bank_sell = float(row_texts[3])
if bank_buy <= 0 or bank_buy > 10000 or bank_sell <= 0 or bank_sell > 10000:
continue
except (ValueError, IndexError):
continue # 跳过数值异常或字段缺失的行
# 构造数据项,字段顺序严格匹配中国银行返回格式
item = ForexItem()
item['id'] = str(valid_count + 1)
item['currency_code'] = row_texts[0] # 货币名称
item['currency_name'] = row_texts[0] # 货币名称
item['bank_buy'] = row_texts[1] # 现汇买入价
item['cash_buy'] = row_texts[2] # 现钞买入价
item['bank_sell'] = row_texts[3] # 现汇卖出价
item['cash_sell'] = row_texts[4] # 现钞卖出价
item['middle_rate'] = row_texts[5] # 中间价
item['publish_time'] = row_texts[6] # 发布时间
yield item
valid_count += 1
self.logger.info(
f"提取成功[{valid_count}]:{item['currency_name']} - 现汇买入价:{item['bank_buy']} | 现汇卖出价:{item['bank_sell']}")
self.logger.info(f"爬取完成!共提取有效外汇数据:{valid_count} 条")
项目items代码
点击查看代码
# items.py:定义外汇数据字段
import scrapy
class ForexItem(scrapy.Item):
id = scrapy.Field() # 序号
currency_code = scrapy.Field() # 货币代码
currency_name = scrapy.Field() # 货币名称
bank_buy = scrapy.Field() # 现汇买入价
bank_sell = scrapy.Field() # 现汇卖出价
cash_buy = scrapy.Field() # 现钞买入价
cash_sell = scrapy.Field() # 现钞卖出价
middle_rate = scrapy.Field() # 中间价
publish_time = scrapy.Field() # 发布时间
项目pipelines代码
点击查看代码
# pipelines.py:自动创建外汇表+数据插入
import pymysql
from itemadapter import ItemAdapter
from scrapy.utils.project import get_project_settings
class MySQLPipeline:
def __init__(self):
# 从 settings.py 读取 MySQL 配置
settings = get_project_settings()
self.host = settings.get('MYSQL_HOST', 'localhost')
self.user = settings.get('MYSQL_USER', 'root')
self.password = settings.get('MYSQL_PASSWORD', '')
self.database = settings.get('MYSQL_DATABASE', 'spider_db')
self.port = settings.get('MYSQL_PORT', 3306)
def open_spider(self, spider):
# 连接数据库,创建外汇数据表
self.db = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
port=self.port,
charset='utf8mb4'
)
self.cursor = self.db.cursor()
# 创建外汇表(字段和 Item 完全匹配)
create_table_sql = """
CREATE TABLE IF NOT EXISTS forex_info (
id VARCHAR(10) NOT NULL COMMENT '序号',
currency_code VARCHAR(10) NOT NULL COMMENT '货币代码(如 USD)',
currency_name VARCHAR(50) NOT NULL COMMENT '货币名称(如 美元)',
bank_buy VARCHAR(20) DEFAULT '0' COMMENT '现汇买入价',
bank_sell VARCHAR(20) DEFAULT '0' COMMENT '现汇卖出价',
cash_buy VARCHAR(20) DEFAULT '0' COMMENT '现钞买入价',
cash_sell VARCHAR(20) DEFAULT '0' COMMENT '现钞卖出价',
middle_rate VARCHAR(20) DEFAULT '0' COMMENT '中间价',
publish_time VARCHAR(30) DEFAULT '' COMMENT '发布时间',
PRIMARY KEY (currency_code) # 货币代码唯一,避免重复
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='中国银行外汇汇率表';
"""
self.cursor.execute(create_table_sql)
self.db.commit()
spider.logger.info(" 外汇爬虫 - MySQL 连接成功,数据表创建完成!")
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.db.close()
spider.logger.info(" 外汇爬虫 - MySQL 连接已关闭!")
def process_item(self, item, spider):
# 插入/更新外汇数据
insert_sql = """
INSERT INTO forex_info (
id, currency_code, currency_name, bank_buy, bank_sell,
cash_buy, cash_sell, middle_rate, publish_time
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE # 货币代码重复时更新最新数据
bank_buy = VALUES(bank_buy),
bank_sell = VALUES(bank_sell),
cash_buy = VALUES(cash_buy),
cash_sell = VALUES(cash_sell),
middle_rate = VALUES(middle_rate),
publish_time = VALUES(publish_time);
"""
try:
data = (
item.get('id', ''),
item.get('currency_code', ''),
item.get('currency_name', ''),
item.get('bank_buy', '0'),
item.get('bank_sell', '0'),
item.get('cash_buy', '0'),
item.get('cash_sell', '0'),
item.get('middle_rate', '0'),
item.get('publish_time', '')
)
self.cursor.execute(insert_sql, data)
self.db.commit()
spider.logger.info(f" 外汇插入成功:{item['currency_name']}({item['currency_code']})")
except Exception as e:
self.db.rollback()
spider.logger.error(f" 外汇插入失败:{str(e)} | 数据:{item}")
return item
爬虫结果及爬取数据
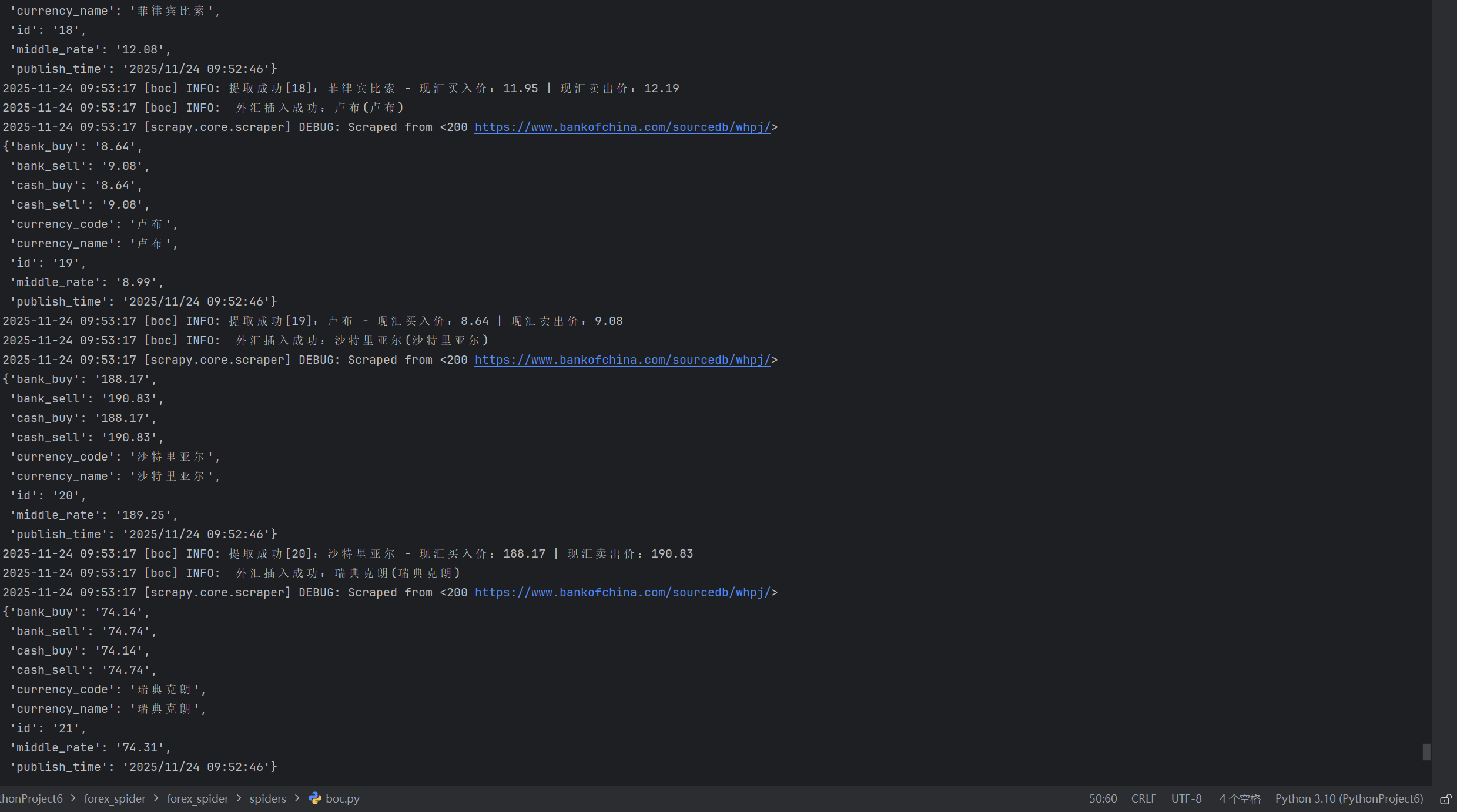
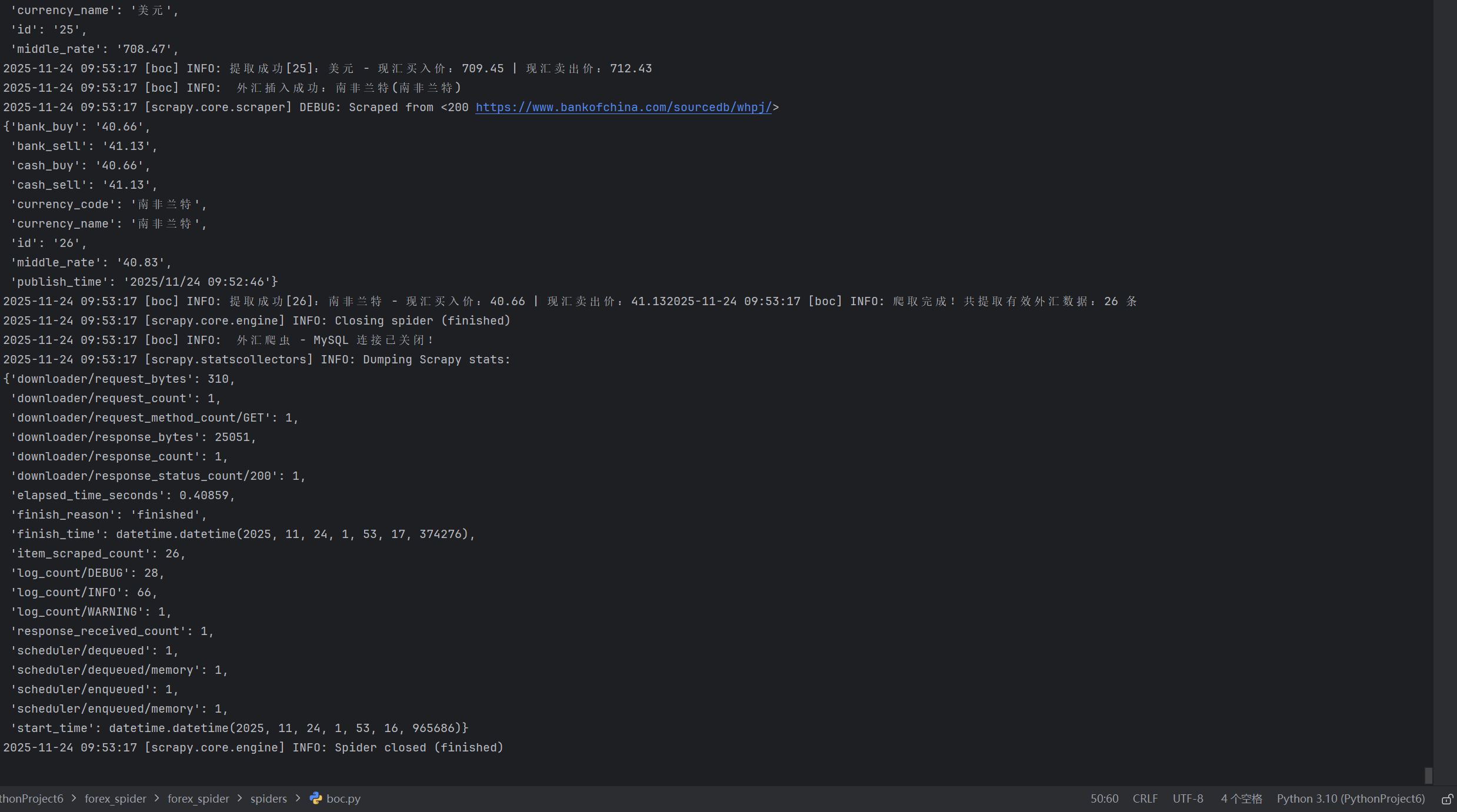
查看特定货币信息:美元

2.实验心得
1) 爬取的网页网址https://www.bankofchina.com/sourcedb/whpj/
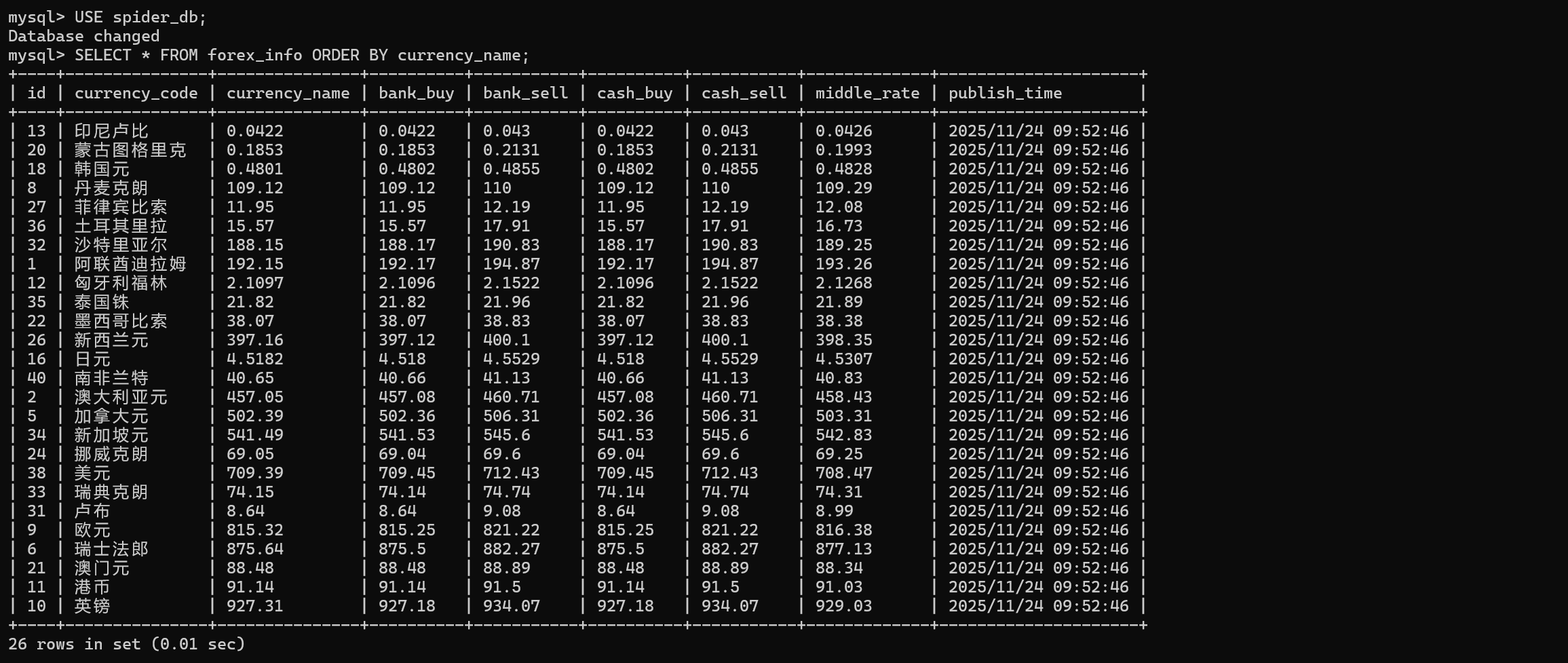
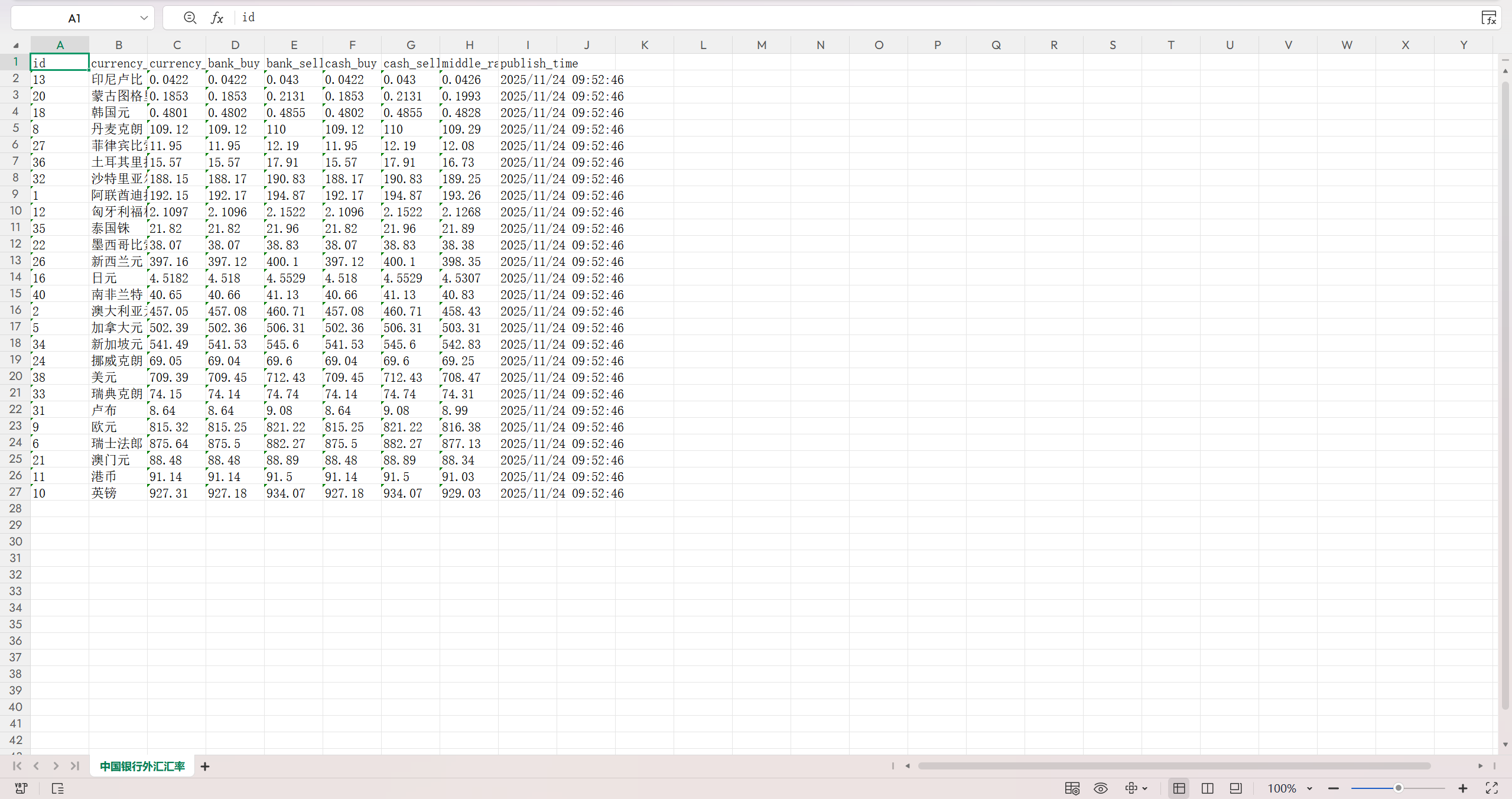
2) 代码运行爬虫核心逻辑是从 start_urls 发起请求,访问目标网页在 parse 方法中解析网页响应,然后提取外汇数据,再通过 XPath 定位包含汇率数据的表格行,过滤无效数据行提取每行的货币名称、买入价、卖出价等字段,封装为 ForexItem 对象并输出,然后通过pipelines代码用MySQLPipeline 处理自动创建 forex_info 数据表再通过 SQL 实现数据插入,最后从 MySQL 数据库查询所有外汇数据使用 openpyxl 库创建 Excel 文件
excel导出数据
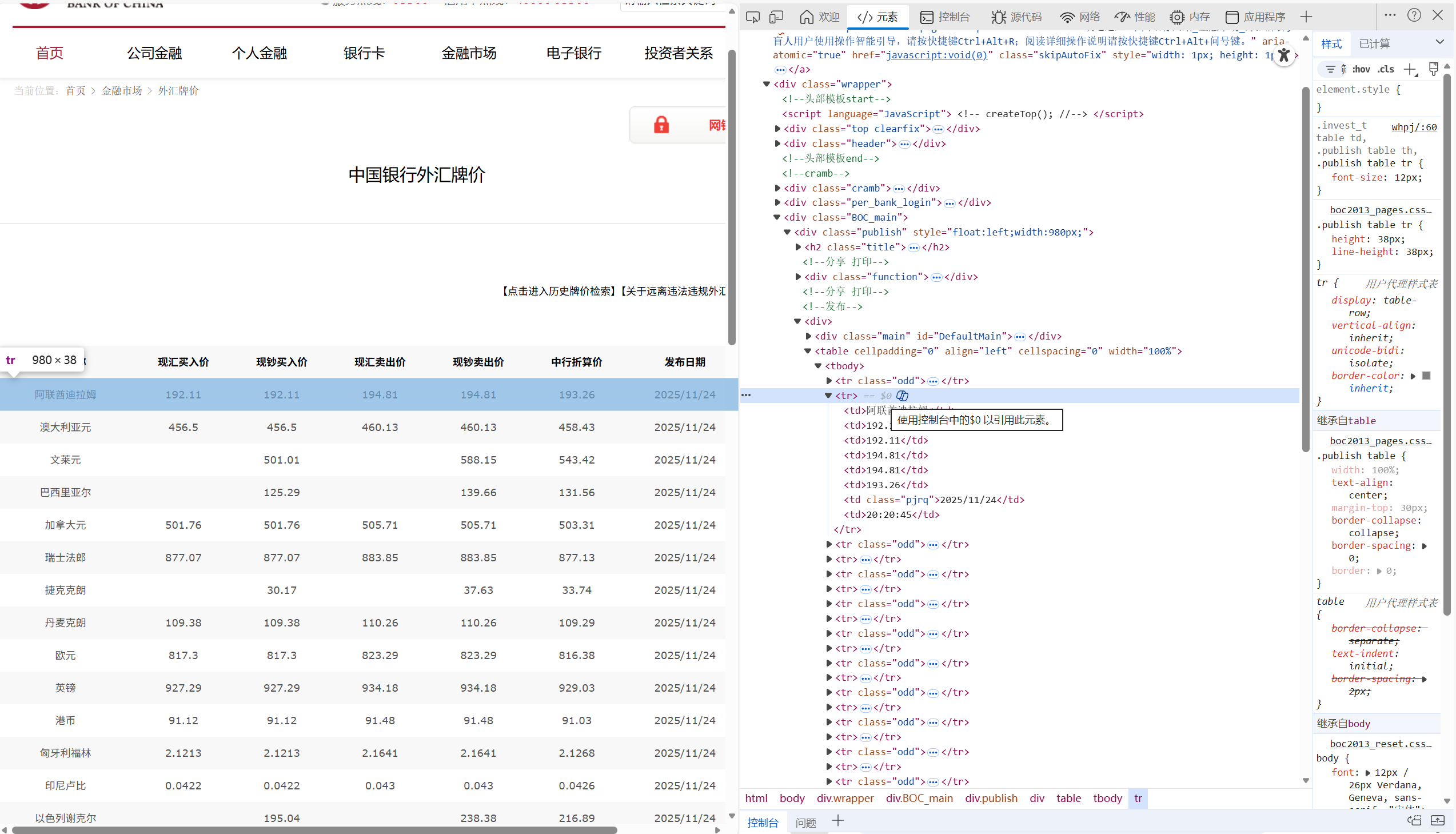
3) 在 boc.py 中主要使用了XPath语法提取数据
forex_rows = response.xpath( '//tr[contains(., ".") and string-length(translate(., "0123456789.", "")) < string-length(.) - 3]' )
用//tr[...]匹配所有满足条件的表格行 观察爬取网页的所有符合tr表格行
Gitee文件夹及代码链接:https://gitee.com/sike-0420/kuku/tree/master/作业3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号