

102302139 尚子骐 数据采集与融合作业2
- 作业一
1. 完整代码及运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import sqlite3
from datetime import datetime
import logging
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
CITY_URLS = {
"北京": "https://www.weather.com.cn/weather/101010100.shtml",
"上海": "https://www.weather.com.cn/weather/101020100.shtml",
"广州": "https://www.weather.com.cn/weather/101280101.shtml",
"深圳": "https://www.weather.com.cn/weather/101280601.shtml",
"成都": "https://www.weather.com.cn/weather/101270101.shtml"
}
# 数据库操作类
class WeatherDB:
def __init__(self, db_name="weather.db"):
self.conn = sqlite3.connect(db_name)
self.cursor = self.conn.cursor()
self._create_table()
def _create_table(self):
"""创建天气表"""
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS daily_weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city TEXT NOT NULL,
forecast_date TEXT NOT NULL, -- 预报日期
weather TEXT, -- 天气状况
temperature TEXT, -- 温度范围
wind TEXT, -- 风向风力
crawl_time TIMESTAMP NOT NULL -- 爬取时间
)
''')
self.conn.commit()
def insert_data(self, data):
"""插入数据"""
try:
self.cursor.executemany('''
INSERT INTO daily_weather
(city, forecast_date, weather, temperature, wind, crawl_time)
VALUES (?, ?, ?, ?, ?, ?)
''', data)
self.conn.commit()
logging.info(f"成功插入 {len(data)} 条数据")
except Exception as e:
self.conn.rollback()
logging.error(f"插入数据失败: {e}")
def close(self):
self.conn.close()
# 爬取天气数据
def crawl_weather(city, url):
"""爬取单个城市的7日天气预报"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "lxml")
# 解析7日数据
forecast_list = soup.select("ul.t.clearfix li")[:7]
result = []
crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for item in forecast_list:
#日期
date = item.find("h1").text.strip()
#天气状况
weather = item.find("p", class_="wea").text.strip()
#温度
temp_high = item.find("p", class_="tem").find("span").text if item.find("p", class_="tem").find(
"span") else ""
temp_low = item.find("p", class_="tem").find("i").text.strip()
temperature = f"{temp_high}/{temp_low}" if temp_high else temp_low
#风向风力
wind = item.find("p", class_="win").find("i").text.strip()
result.append((city, date, weather, temperature, wind, crawl_time))
logging.info(f"成功获取 {city} 的7日天气预报")
return result
except Exception as e:
logging.error(f"爬取 {city} 失败: {e}")
return []
if __name__ == "__main__":
#初始化数据库
db = WeatherDB()
#批量爬取城市天气
all_weather = []
for city, url in CITY_URLS.items():
weather_data = crawl_weather(city, url)
all_weather.extend(weather_data)
#插入数据库
if all_weather:
db.insert_data(all_weather)
#关闭数据库
db.close()
logging.info("爬取任务完成")
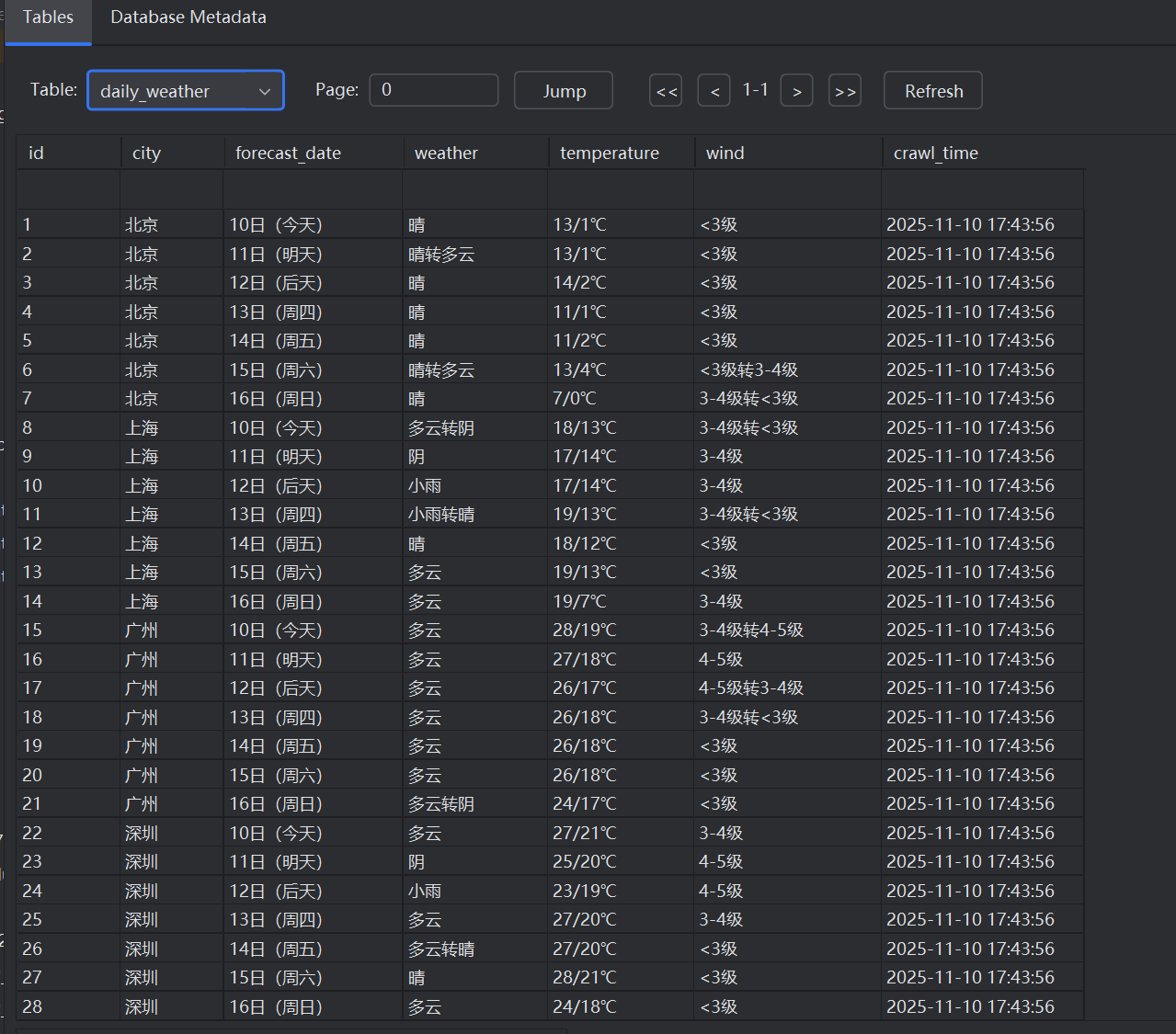
2. 实验心得
- 代码拆解
核心爬虫逻辑
点击查看代码
def crawl_weather(city, url):
"""爬取单个城市的7日天气预报"""
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/114.0.0.0 Safari/537.36"
}
try:
# 发起请求
response = requests.get(url, headers=headers, timeout=10)
response.encoding = "utf-8" # 确保中文正常显示
soup = BeautifulSoup(response.text, "lxml") # 解析HTML
# 提取7日预报数据(页面中ul.t.clearfix下的li标签)
forecast_list = soup.select("ul.t.clearfix li")[:7] # 取前7天数据
result = []
crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 记录爬取时间
# 解析每一天的天气数据
for item in forecast_list:
date = item.find("h1").text.strip() # 日期(如"10日(今天)")
weather = item.find("p", class_="wea").text.strip() # 天气状况(如"晴")
# 温度处理(最高温可能为空,只保留最低温)
temp_high = item.find("p", class_="tem").find("span").text if item.find("p", class_="tem").find("span") else ""
temp_low = item.find("p", class_="tem").find("i").text.strip() # 最低温
temperature = f"{temp_high}/{temp_low}" if temp_high else temp_low # 拼接温度格式
wind = item.find("p", class_="win").find("i").text.strip() # 风向风力(如"东北风3级")
result.append((city, date, weather, temperature, wind, crawl_time)) # 组装数据
logging.info(f"成功获取 {city} 的7日天气预报")
return result
except Exception as e:
logging.error(f"爬取 {city} 失败: {e}")
return []
点击查看代码
class WeatherDB:
def __init__(self, db_name="weather.db"):
self.conn = sqlite3.connect(db_name) # 连接数据库
self.cursor = self.conn.cursor()
self._create_table() # 初始化表结构
def _create_table(self):
"""创建存储天气数据的表"""
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS daily_weather (
id INTEGER PRIMARY KEY AUTOINCREMENT,
city TEXT NOT NULL, # 城市名
forecast_date TEXT NOT NULL, # 预报日期
weather TEXT, # 天气状况
temperature TEXT, # 温度范围
wind TEXT, # 风向风力
crawl_time TIMESTAMP NOT NULL # 爬取时间
)
''')
self.conn.commit()
def insert_data(self, data):
"""批量插入天气数据"""
try:
self.cursor.executemany('''
INSERT INTO daily_weather
(city, forecast_date, weather, temperature, wind, crawl_time)
VALUES (?, ?, ?, ?, ?, ?)
''', data) # 批量插入
self.conn.commit()
logging.info(f"成功插入 {len(data)} 条数据")
except Exception as e:
self.conn.rollback() # 失败时回滚
logging.error(f"插入数据失败: {e}")
网络请求:通过requests.get发起请求,response.raise_for_status()确保请求成功,response.encoding = response.apparent_encoding自动适配网页编码。
HTML 解析:用BeautifulSoup的html.parser解析器定位到类为rk-table的表格。
数据提取:从表格的行(tr)和单元格(td)中提取排名、学校名称、省份、类型、得分等信息,并格式化打印。
主程序入口:指定目标 URL 并调用爬虫函数,time.sleep(2)是为了模拟合理的请求间隔
- 作业二
1. 完整代码及运行结果
点击查看代码
import requests
import sqlite3
import logging
from datetime import datetime
import re
# 解决SSL警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
#配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler()] # 确保日志输出到控制台
)
#腾讯财经股票接口
TENCENT_STOCK_API = "https://qt.gtimg.cn/q=sh000001,sh600000,sh600036,sh601318,sh601857,sh601939,sh601988,sh600030,sh601328,sh600519,sz000001,sz000858,sz002594,sz002415,sz300750,sz300059,sz300124,sz002230,sz002352,sz000651"
class StockDB:
def __init__(self):
#强制指定数据库保存到桌面
self.db_path = r"C:\Users\kuku\Desktop\stocks_tencent.db"
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
self._create_table()
logging.info(f"数据库已创建/连接,路径:{self.db_path}")
def _create_table(self):
#创建股票表
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT NOT NULL, -- 股票代码(如sh600000)
name TEXT NOT NULL, -- 股票名称
price REAL, -- 当前价格
change_amount REAL, -- 涨跌额
change_percent REAL, -- 涨跌幅(%)
open REAL, -- 开盘价
high REAL, -- 最高价
low REAL, -- 最低价
prev_close REAL, -- 昨收价
volume INTEGER, -- 成交量(手)
amount REAL, -- 成交额(万元)
crawl_time TIMESTAMP NOT NULL -- 爬取时间
)
''')
self.conn.commit()
def insert_data(self, data):
if not data:
logging.warning("没有数据可插入")
return
try:
self.cursor.executemany('''
INSERT INTO stock_data
(code, name, price, change_amount, change_percent, open, high, low,
prev_close, volume, amount, crawl_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', data)
self.conn.commit()
logging.info(f"成功插入 {len(data)} 条数据到数据库")
except Exception as e:
self.conn.rollback()
logging.error(f"插入数据失败: {e}")
def close(self):
self.conn.close()
logging.info("数据库连接已关闭")
def crawl_tencent_stocks():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
"Referer": "https://finance.qq.com/",
"Accept": "*/*"
}
try:
logging.info("开始请求股票数据...")
response = requests.get(
TENCENT_STOCK_API,
headers=headers,
timeout=15,
verify=False
)
response.encoding = "gbk" #腾讯用GBK编码
content = response.text
logging.info("股票数据请求成功,开始解析...")
#用正则提取股票数据
stock_pattern = re.compile(r'v_(sh|sz)(\d+)="(.*?)"')
matches = stock_pattern.findall(content)
if not matches:
logging.warning("未匹配到任何股票数据(可能API格式变化)")
return []
result = []
crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
logging.info(f"匹配到 {len(matches)} 只股票,开始解析详细信息...")
for market, code, info in matches:
fields = info.split("~")
#腾讯股票字段索引
if len(fields) < 12:
logging.warning(f"股票 {code} 数据字段不完整,跳过")
continue
try:
#解析字段
stock_item = (
f"{market}{code}", #完整代码
fields[1] if len(fields) > 1 else "未知名称", # 名称
float(fields[3]) if fields[3] and fields[3] != "-" else 0.0, # 当前价格
float(fields[4]) if fields[4] and fields[4] != "-" else 0.0, # 涨跌额
float(fields[5]) if fields[5] and fields[5] != "-" else 0.0, # 涨跌幅
float(fields[6]) if fields[6] and fields[6] != "-" else 0.0, # 开盘价
float(fields[7]) if fields[7] and fields[7] != "-" else 0.0, # 最高价
float(fields[8]) if fields[8] and fields[8] != "-" else 0.0, # 最低价
float(fields[9]) if fields[9] and fields[9] != "-" else 0.0, # 昨收价
int(fields[10]) if fields[10] and fields[10] != "-" else 0, # 成交量
float(fields[11]) if fields[11] and fields[11] != "-" else 0.0, # 成交额
crawl_time
)
result.append(stock_item)
#打印解析成功的股票
logging.info(f"解析成功:{stock_item[1]}({stock_item[0]}) 价格:{stock_item[2]}")
except (ValueError, IndexError) as e:
logging.warning(f"解析股票 {code} 失败: {e},跳过")
continue
logging.info(f"数据解析完成,共获取 {len(result)} 条有效股票数据")
#打印前3条数据
if result:
logging.info("前3条数据示例:")
for item in result[:3]:
print(item)
return result
except requests.exceptions.RequestException as e:
logging.error(f"网络请求失败: {e}")
return []
except Exception as e:
logging.error(f"爬取过程发生错误: {e}")
return []
if __name__ == "__main__":
logging.info("===== 开始股票爬取任务 =====")
#初始化数据库
db = StockDB()
#爬取数据
stocks = crawl_tencent_stocks()
#插入数据
if stocks:
db.insert_data(stocks)
logging.info(f"任务完成,数据库文件已保存到:{db.db_path}")
else:
logging.warning("未获取到有效数据,数据库文件可能为空")
#关闭数据库
db.close()
logging.info("===== 任务结束 =====")
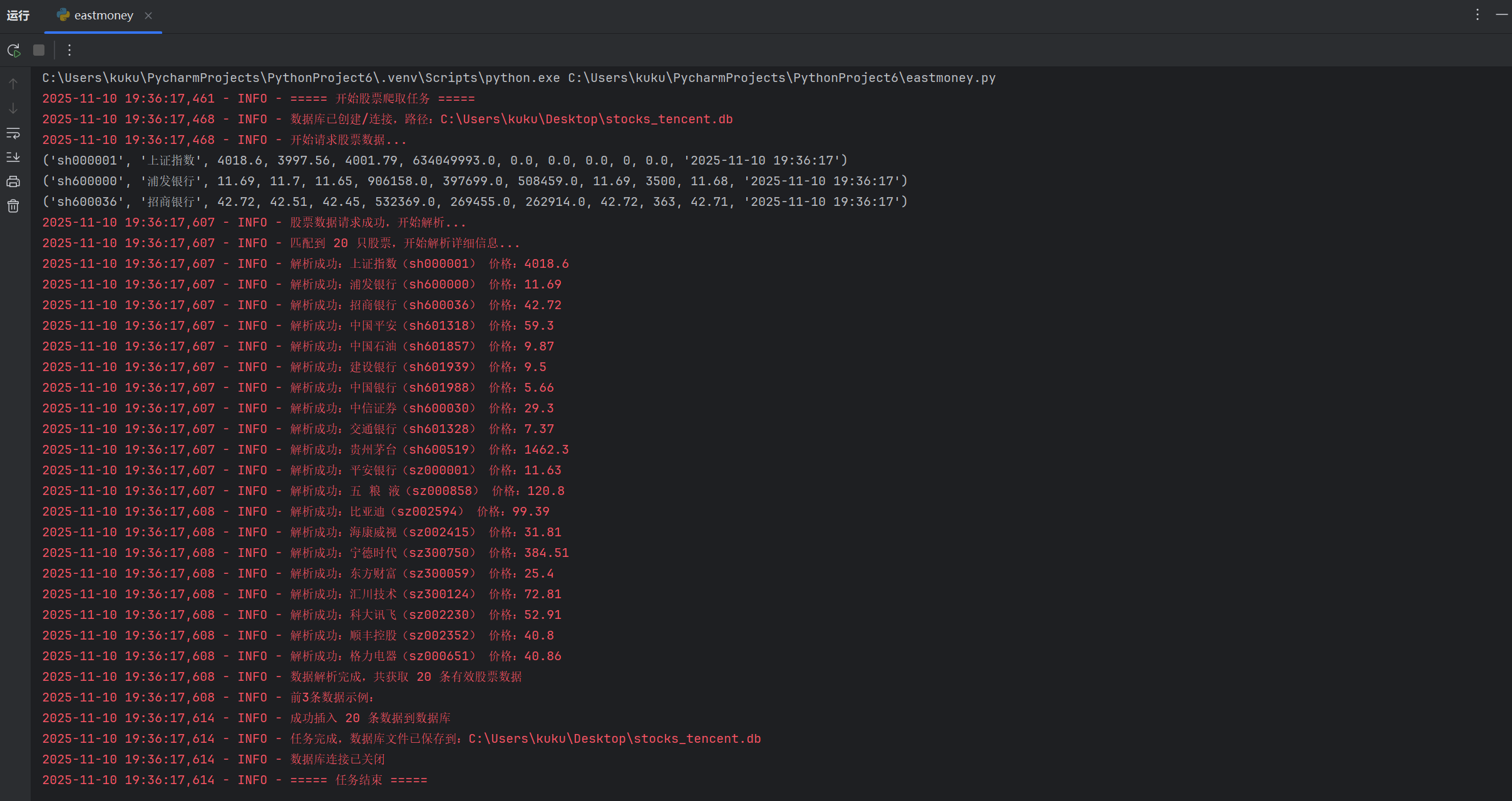
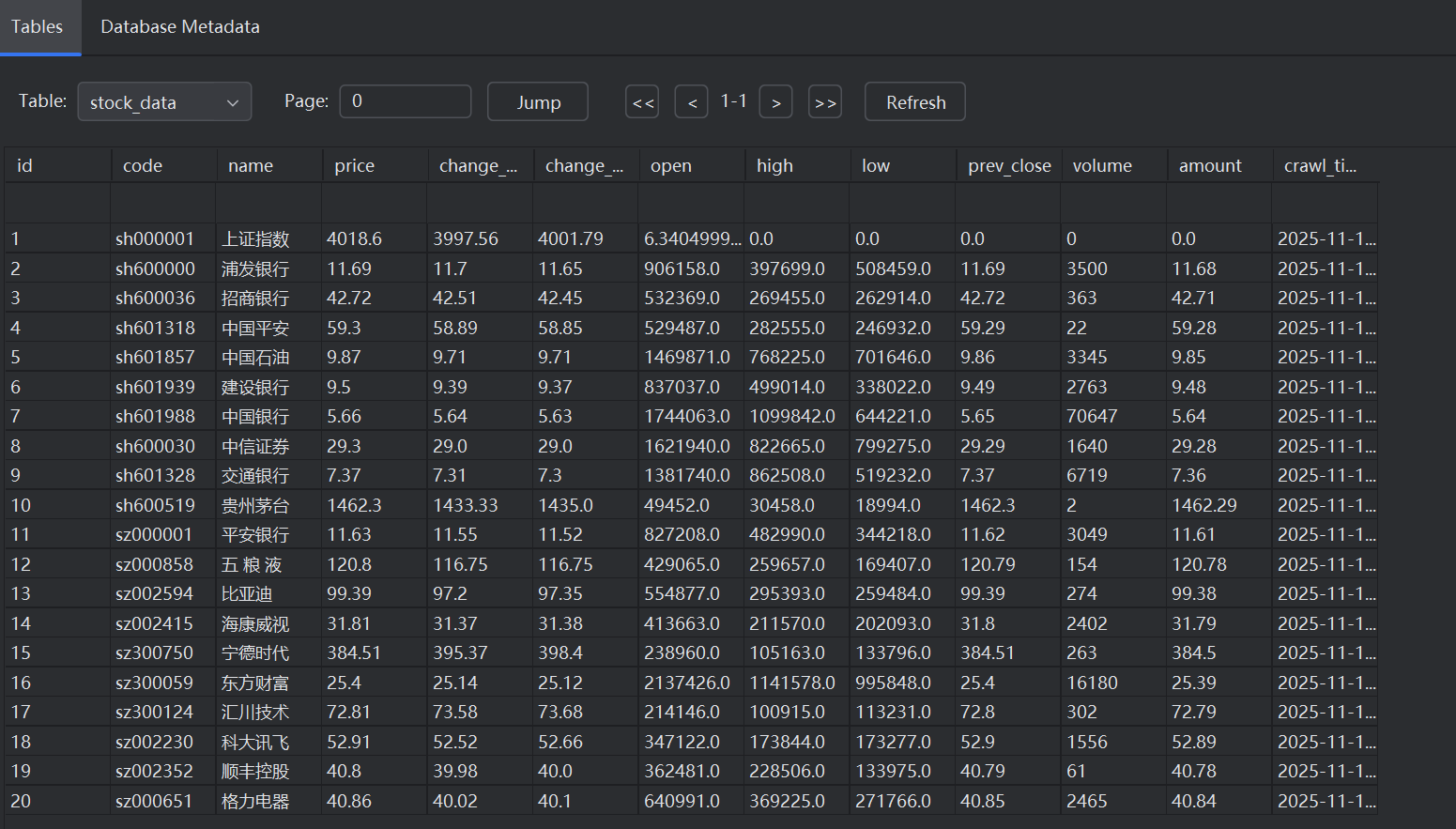
2. 实验心得
本次作业由于东方财富网的反爬机制,只能采取使用新浪股票的 API,在运行代码的过程中返回数据结构可能有细微调整,导致列表索引解析失败,api结构也发生了变化,我换了一个更稳定的股票数据源 ,使用腾讯财经的股票接口,最终完成本次实验的爬取。
- 核心代码块
1.正则提取与数据解析核心逻辑
点击查看代码
def crawl_tencent_stocks():
# (省略请求逻辑...)
# 用正则提取股票数据
stock_pattern = re.compile(r'v_(sh|sz)(\d+)="(.*?)"')
matches = stock_pattern.findall(content)
result = []
crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for market, code, info in matches:
fields = info.split("~") # 按~拆分字段
try:
# 解析并转换字段类型(价格、涨跌额等)
stock_item = (
f"{market}{code}", # 完整代码(如sh600000)
fields[1], # 股票名称
float(fields[3]), # 当前价格
float(fields[4]), # 涨跌额
float(fields[5]), # 涨跌幅
float(fields[6]), # 开盘价
float(fields[7]), # 最高价
float(fields[8]), # 最低价
float(fields[9]), # 昨收价
int(fields[10]), # 成交量
float(fields[11]), # 成交额
crawl_time
)
result.append(stock_item)
except (ValueError, IndexError):
continue
return result
2.数据库存储核心逻辑
点击查看代码
class StockDB:
def __init__(self):
self.db_path = r"C:\Users\kuku\Desktop\stocks_tencent.db"
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
self._create_table()
def _create_table(self):
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_data (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT NOT NULL, -- 股票代码
name TEXT NOT NULL, -- 股票名称
price REAL, -- 当前价格
change_amount REAL, -- 涨跌额
change_percent REAL, -- 涨跌幅
open REAL, -- 开盘价
high REAL, -- 最高价
low REAL, -- 最低价
prev_close REAL, -- 昨收价
volume INTEGER, -- 成交量
amount REAL, -- 成交额
crawl_time TIMESTAMP NOT NULL -- 爬取时间
)
''')
self.conn.commit()
def insert_data(self, data):
self.cursor.executemany('''
INSERT INTO stock_data
(code, name, price, change_amount, change_percent, open, high, low,
prev_close, volume, amount, crawl_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', data)
self.conn.commit()
r'v_(sh|sz)(\d+)="(.*?)"'
v_:匹配固定前缀
(sh|sz):分组匹配 “上海(sh)” 或 “深圳(sz)” 市场
(\d+):分组匹配股票代码(纯数字)
="(.*?)":非贪婪匹配双引号内的所有字段(即股票详细数据块)
4.代码运行全过程:初始化数据库 → 爬取股票数据 → 批量插入数据库 → 关闭连接,完成 “请求→提取→存储” 全流程。
- 作业三
1. 完整代码及运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import sqlite3
import logging
from datetime import datetime
import os
# 解决SSL警告
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[logging.StreamHandler()]
)
# 中国大学2021主榜网页地址(直接爬取HTML)
RANK_URL = "https://www.shanghairanking.cn/rankings/bcur/2021"
class UniversityDB:
def __init__(self):
self.db_path = os.path.join(r"C:\Users\kuku\Desktop", "university_rank_2021.db")
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
self._create_table()
logging.info(f"数据库已创建/连接,路径:{self.db_path}")
def _create_table(self):
self.cursor.execute('''
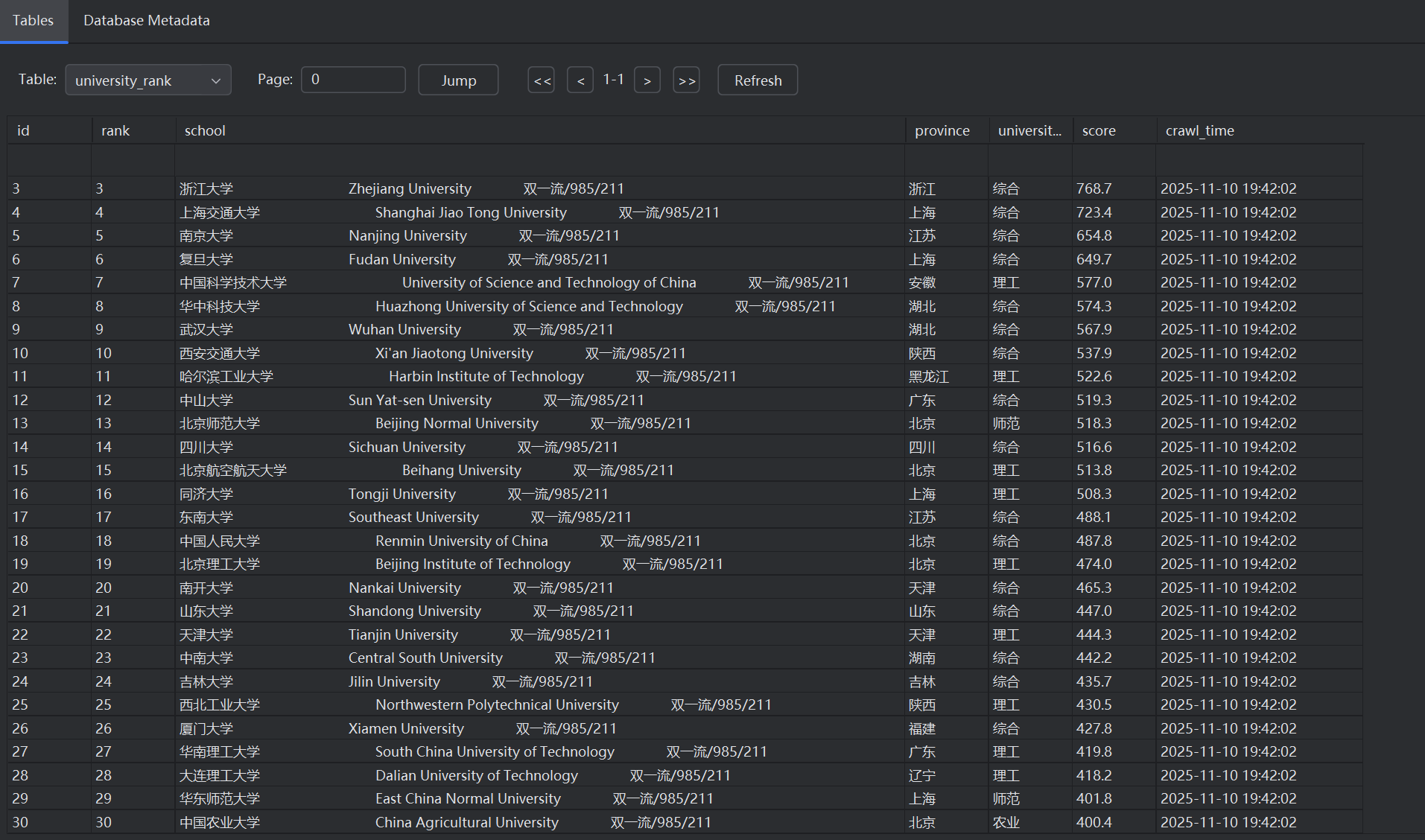
CREATE TABLE IF NOT EXISTS university_rank (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER NOT NULL, -- 排名
school TEXT NOT NULL, -- 学校名称
province TEXT, -- 省市
university_type TEXT, -- 类型
score REAL, -- 总分
crawl_time TIMESTAMP NOT NULL -- 爬取时间
)
''')
self.conn.commit()
def insert_data(self, data):
if not data:
logging.warning("没有数据可插入")
return
try:
self.cursor.executemany('''
INSERT INTO university_rank
(rank, school, province, university_type, score, crawl_time)
VALUES (?, ?, ?, ?, ?, ?)
''', data)
self.conn.commit()
logging.info(f"成功插入 {len(data)} 条数据")
except Exception as e:
self.conn.rollback()
logging.error(f"插入失败: {e}")
def close(self):
self.conn.close()
logging.info("数据库连接已关闭")
def crawl_universities():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9"
}
try:
logging.info("开始请求大学排名网页...")
response = requests.get(
RANK_URL,
headers=headers,
timeout=20,
verify=False
)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "lxml")
#从HTML表格中提取数据
table = soup.find("table", class_="rk-table")
if not table:
logging.error("未找到排名表格")
return []
#获取表格行数据
rows = table.find_all("tr")[1:]
result = []
crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for row in rows:
cols = row.find_all("td")
if len(cols) < 5: #确保有足够的列
continue
try:
#解析每一列数据
rank = int(cols[0].text.strip()) # 排名
school = cols[1].text.strip() # 学校名称
province = cols[2].text.strip() # 省市
u_type = cols[3].text.strip() # 类型
score = float(cols[4].text.strip()) # 总分
result.append((rank, school, province, u_type, score, crawl_time))
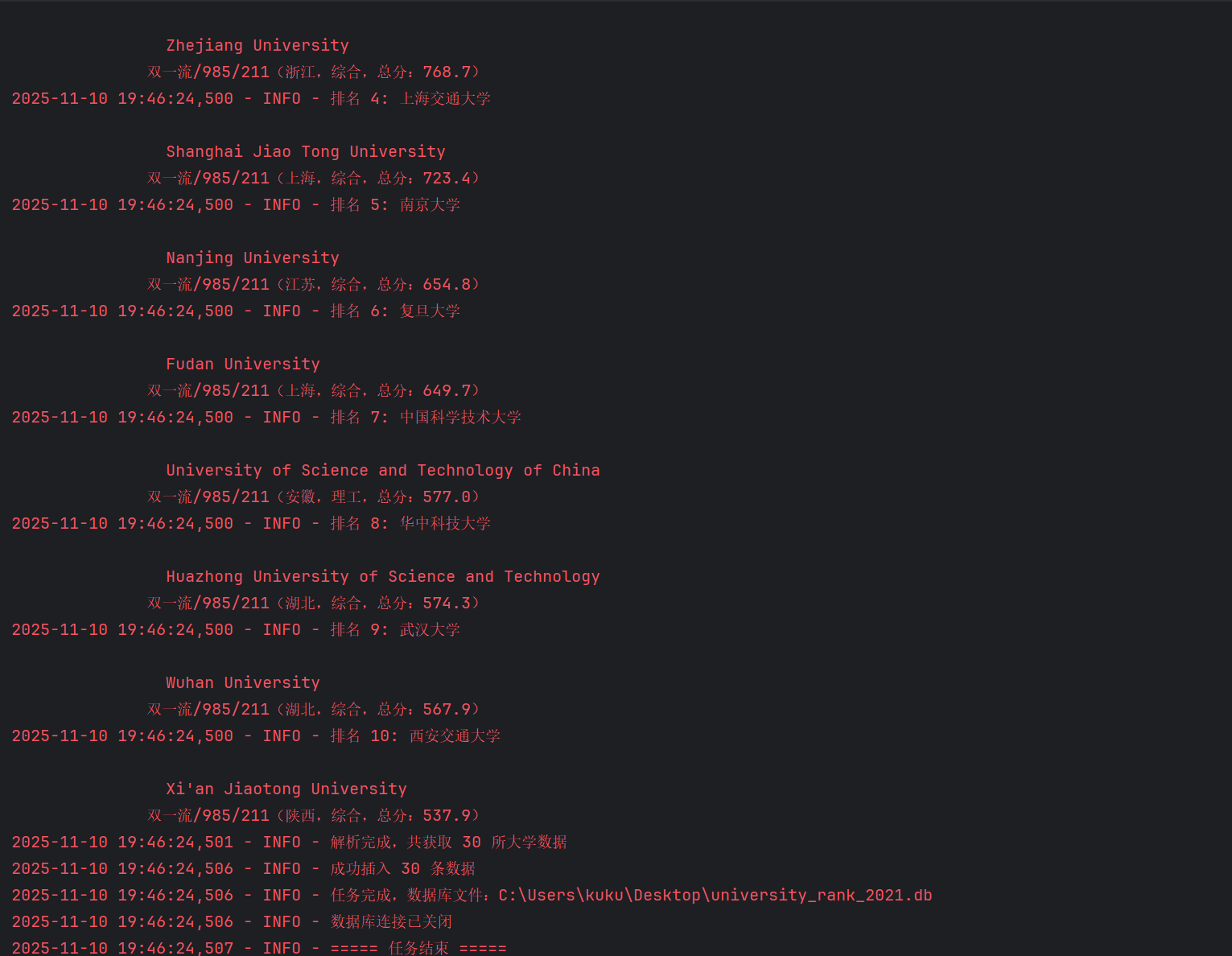
#打印前10名
if len(result) <= 10:
logging.info(f"排名 {rank}: {school}({province},{u_type},总分:{score})")
except (ValueError, IndexError) as e:
logging.warning(f"解析行数据失败: {e},跳过")
continue
logging.info(f"解析完成,共获取 {len(result)} 所大学数据")
return result
except requests.exceptions.RequestException as e:
logging.error(f"网络请求失败: {e}")
return []
except Exception as e:
logging.error(f"爬取异常: {e}")
return []
if __name__ == "__main__":
logging.info("===== 开始中国大学2021主榜爬取任务 =====")
db = UniversityDB()
universities = crawl_universities()
if universities:
db.insert_data(universities)
logging.info(f"任务完成,数据库文件:{db.db_path}")
else:
logging.warning("未获取到有效数据,请检查网络是否能访问排名页面")
db.close()
logging.info("===== 任务结束 =====")
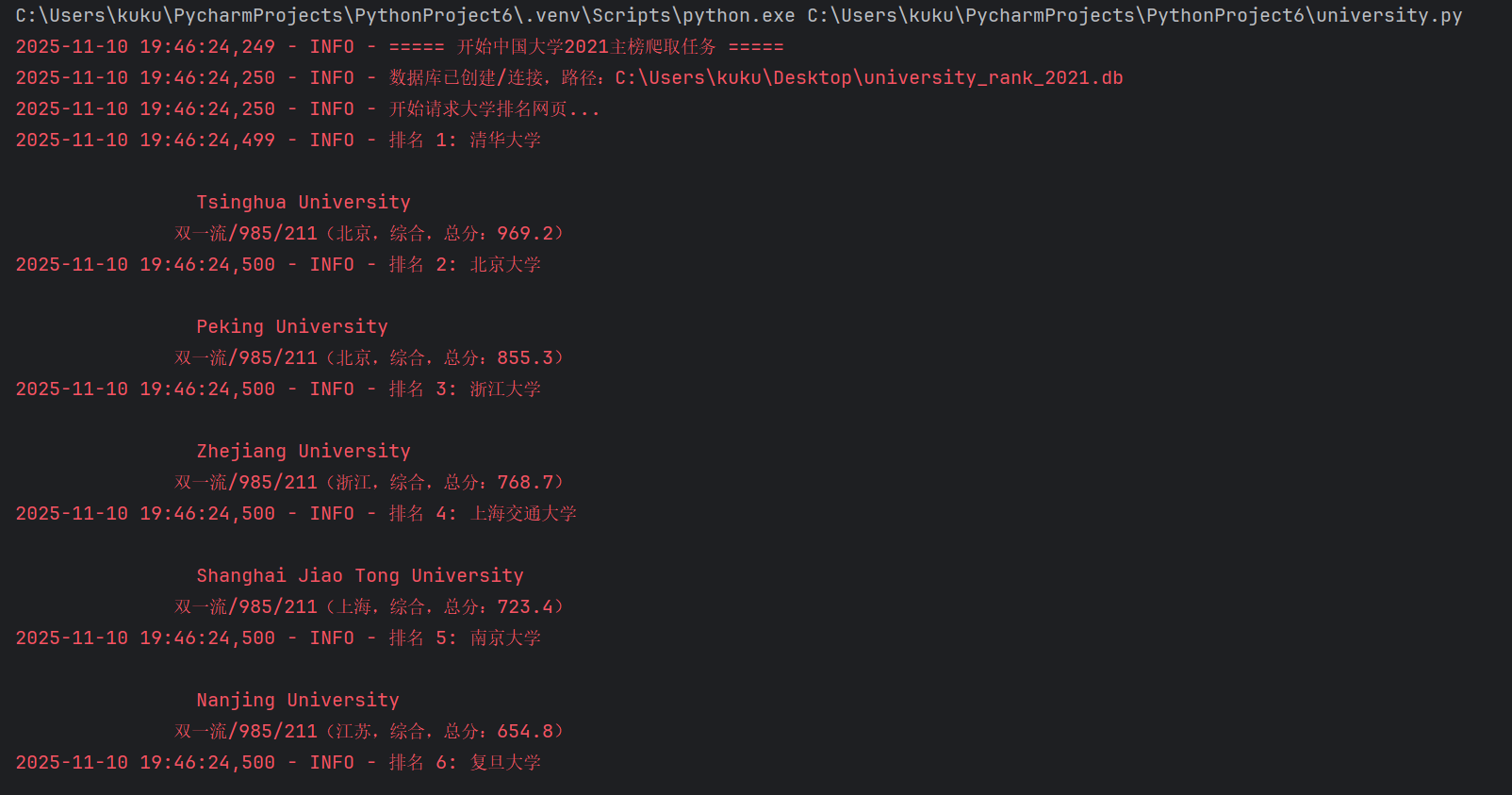
- F12调用过程
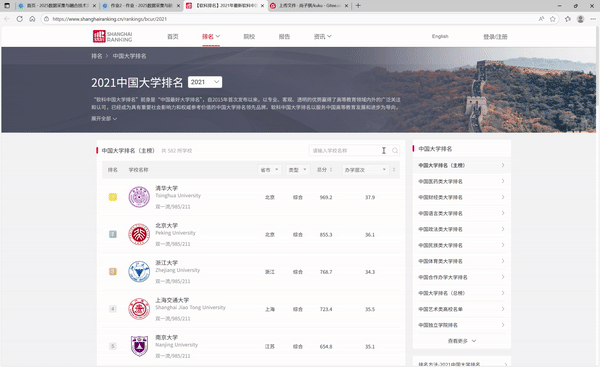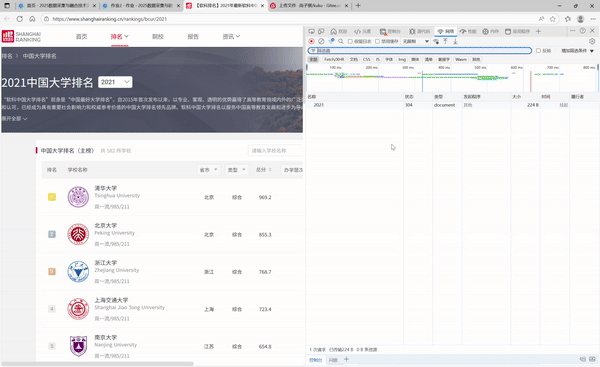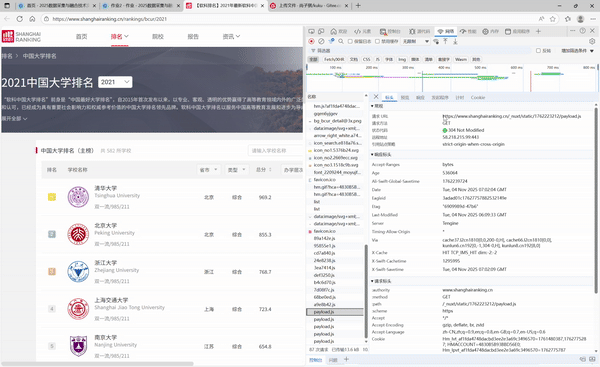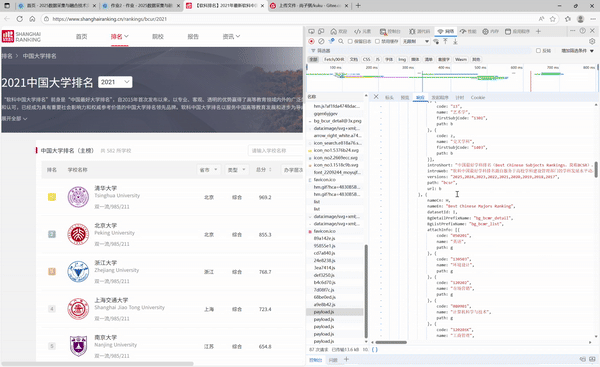
2. 实验心得
- 核心代码块
- 爬虫解析核心逻辑
点击查看代码
def crawl_universities():
# (省略请求头配置...)
try:
response = requests.get(RANK_URL, headers=headers, timeout=20, verify=False)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "lxml")
table = soup.find("table", class_="rk-table") # 定位排名表格
if not table:
logging.error("未找到排名表格")
return []
rows = table.find_all("tr")[1:] # 跳过表头行
result = []
crawl_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
for row in rows:
cols = row.find_all("td")
if len(cols) < 5:
continue
try:
rank = int(cols[0].text.strip()) # 排名(整数)
school = cols[1].text.strip() # 学校名称
province = cols[2].text.strip() # 省市
u_type = cols[3].text.strip() # 类型
score = float(cols[4].text.strip()) # 总分(浮点数)
result.append((rank, school, province, u_type, score, crawl_time))
# 打印前10名
if len(result) <= 10:
logging.info(f"排名 {rank}: {school}({province},{u_type},总分:{score})")
except (ValueError, IndexError) as e:
logging.warning(f"解析失败: {e},跳过")
continue
return result
except Exception as e:
logging.error(f"爬取异常: {e}")
return []
- 数据库存储核心逻辑
点击查看代码
class UniversityDB:
def __init__(self):
self.db_path = os.path.join(r"C:\Users\kuku\Desktop", "university_rank_2021.db")
self.conn = sqlite3.connect(self.db_path)
self.cursor = self.conn.cursor()
self._create_table()
def _create_table(self):
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS university_rank (
id INTEGER PRIMARY KEY AUTOINCREMENT,
rank INTEGER NOT NULL, -- 排名
school TEXT NOT NULL, -- 学校名称
province TEXT, -- 省市
university_type TEXT, -- 类型
score REAL, -- 总分
crawl_time TIMESTAMP NOT NULL -- 爬取时间
)
''')
self.conn.commit()
def insert_data(self, data):
self.cursor.executemany('''
INSERT INTO university_rank
(rank, school, province, university_type, score, crawl_time)
VALUES (?, ?, ?, ?, ?, ?)
''', data)
self.conn.commit()
通过BeautifulSoup的find和find_all方法,精准定位排名表格和每一行的列数据
对排名、总分等字段进行类型转换(如int()、float()),确保数据格式规范
最终将所有大学排名数据批量插入 SQLite 数据库,实现数据的持久化存储
4.在代码运行过程中官方 API 做了访问限制,我直接从网页 HTML 中解析数据,直接爬取网页 HTML:从排名页面的表格中提取数据,绕过 API 限制,稳定性极高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号