

102302139 尚子骐 数据采集与融合作业1
- 作业一:
1. 完整代码以及运行结果
点击查看代码
import requests
from bs4 import BeautifulSoup
import time
def get_university_ranking(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', class_='rk-table')
if not table:
print("未找到排名数据表格")
return
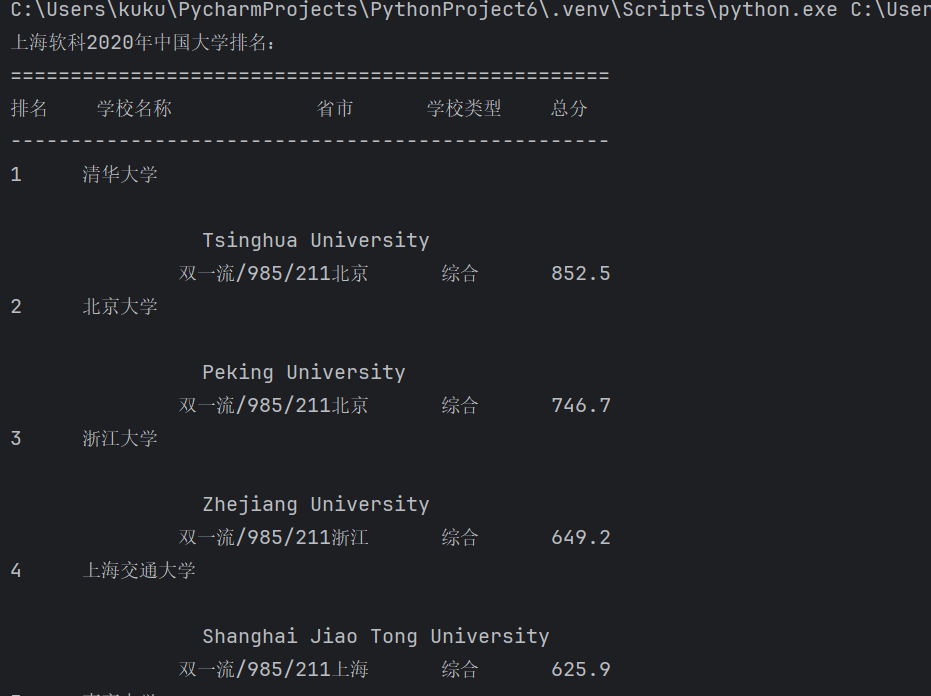
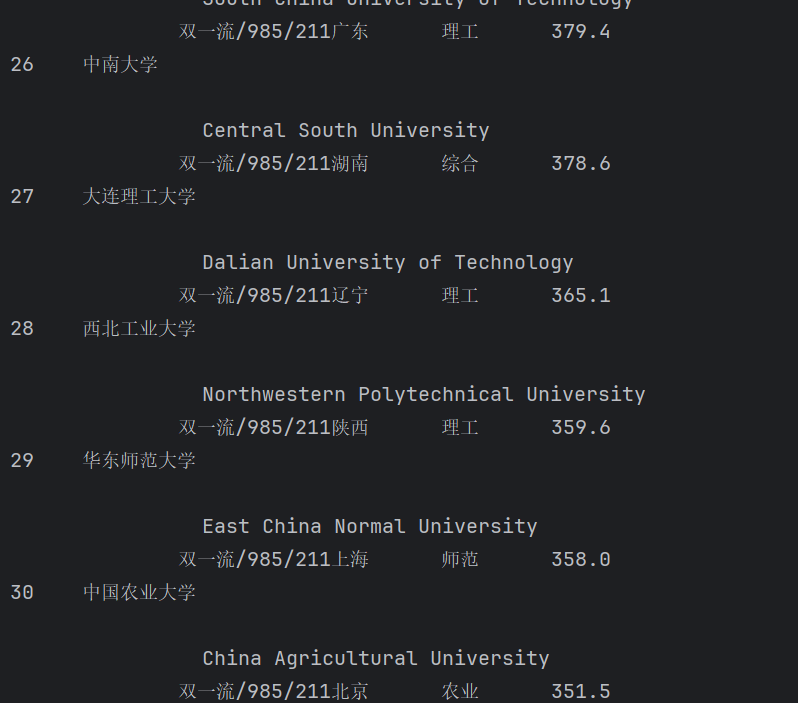
print(f"{'排名':<6}{'学校名称':<16}{'省市':<8}{'学校类型':<8}{'总分'}")
print("-" * 50)
rows = table.find_all('tr')[1:]
for row in rows:
cells = row.find_all('td')
if len(cells) >= 5:
rank = cells[0].text.strip()
name = cells[1].text.strip()
province = cells[2].text.strip()
category = cells[3].text.strip()
score = cells[4].text.strip()
print(f"{rank:<6}{name:<16}{province:<8}{category:<8}{score}")
except Exception as e:
print(f"爬取过程中出现错误: {str(e)}")
if __name__ == "__main__":
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
print("上海软科2020年中国大学排名:")
print("=" * 50)
get_university_ranking(url)
time.sleep(2)
2. 实验心得
-
运用BeautifulSoup 解析HTML文档 查看网页源码以及结构
![屏幕截图 2025-10-26 200743]()
-
网络请求代码
response = requests.get(url, headers=headers) response.raise_for_status() response.encoding = response.apparent_encoding -
HTML解析关键代码
soup = BeautifulSoup(response.text, 'html.parser') table = soup.find('table', class_='rk-table') -
数据提取逻辑
rows = table.find_all('tr')[1:] for row in rows: cells = row.find_all('td') if len(cells) >= 5: rank = cells[0].text.strip() name = cells[1].text.strip() province = cells[2].text.strip() category = cells[3].text.strip() score = cells[4].text.strip() -
定义目标URL主程序入口
if __name__ == "__main__": url = "http://www.shanghairanking.cn/rankings/bcur/2020" get_university_ranking(url) time.sleep(2) -
设置请求头 → 2. 获取网页 → 3. 解析HTML → 4. 定位表格 → 5. 提取数据 → 6. 格式化输出完成本次用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
-
作业二:
1. 完整代码及运行结果
点击查看代码
import urllib3
import time
from urllib.parse import quote
from urllib3.exceptions import InsecureRequestWarning
from bs4 import BeautifulSoup
import re
import json
import sys
sys.stdout.reconfigure(encoding='utf-8')
sys.stderr.reconfigure(encoding='utf-8')
urllib3.disable_warnings(InsecureRequestWarning)
http = urllib3.PoolManager()
def crawl_dangdang_books_v2(keyword, max_items=60):
"""智能爬取策略:精准过滤商品"""
goods_list = []
page = 1
max_pages = 3 # 最多爬取3页
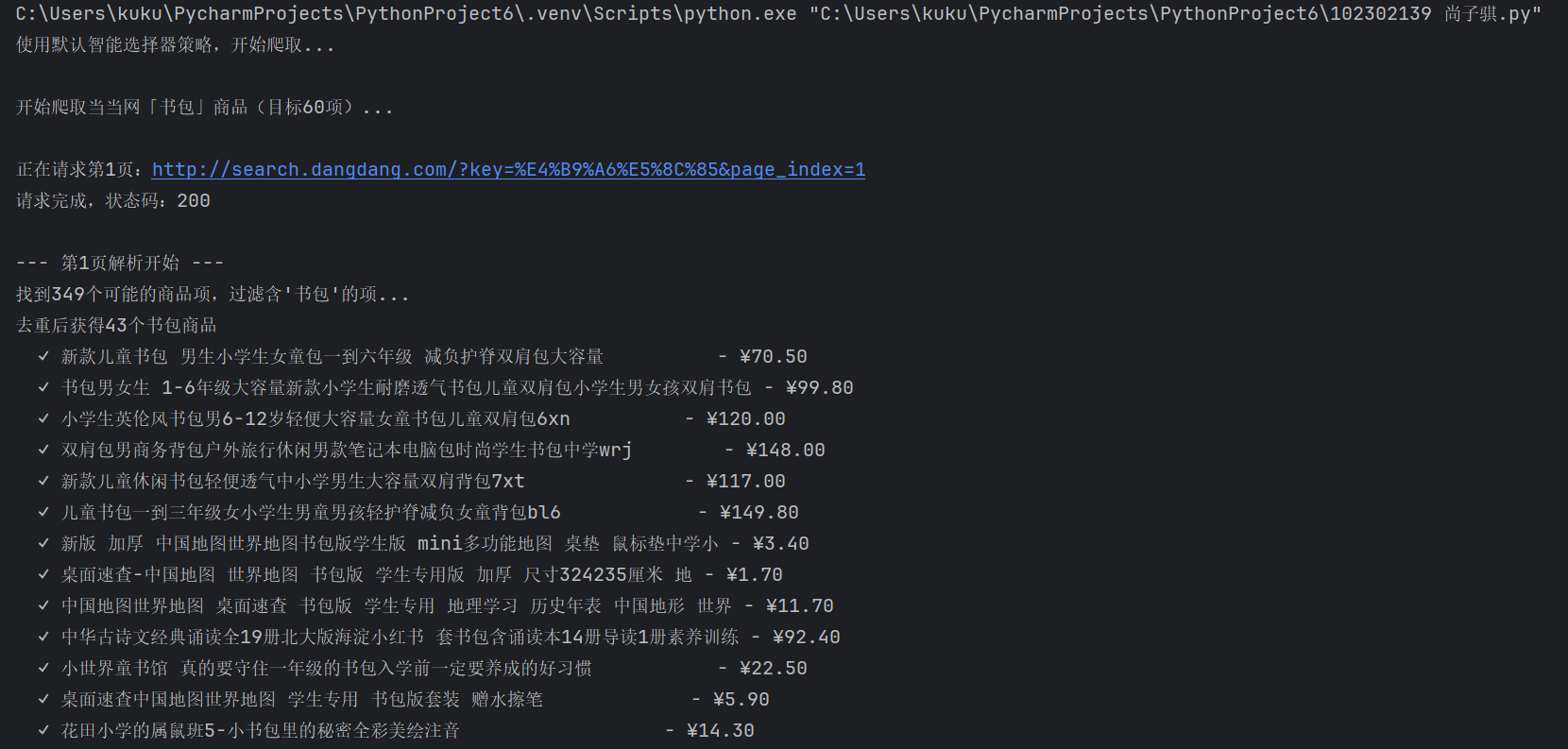
print(f"开始爬取当当网「{keyword}」商品(目标{max_items}项)...\n")
# 循环爬取,直到达到目标数量或页数上限
while page <= max_pages and len(goods_list) < max_items:
# 编码关键词,构造请求URL
encoded_keyword = quote(keyword, encoding="utf-8")
url = f"http://search.dangdang.com/?key={encoded_keyword}&page_index={page}"
print(f"正在请求第{page}页:{url}")
# 模拟浏览器请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9",
"Referer": "http://www.dangdang.com/",
"Accept-Charset": "gbk,utf-8"
}
try:
# 发送请求
response = http.request("GET", url, headers=headers, timeout=10)
print(f"请求完成,状态码:{response.status}")
except Exception as e:
print(f"第{page}页请求异常:{e}")
page += 1
time.sleep(2)
continue
# 状态码非200则跳过当前页
if response.status != 200:
print(f"第{page}页状态码异常:{response.status}")
page += 1
continue
# 解码HTML(当当网用gbk编码)
try:
html = response.data.decode("gbk", errors="replace")
except UnicodeDecodeError:
html = response.data.decode("utf-8", errors="replace")
soup = BeautifulSoup(html, 'html.parser')
products = []
print(f"\n--- 第{page}页解析开始 ---")
# 策略1:提取含"书包"的商品项
product_items = soup.find_all(['li', 'div'], class_=True)
print(f"找到{len(product_items)}个可能的商品项,过滤含'书包'的项...")
for item in product_items:
item_text = item.get_text(strip=True)
if "书包" not in item_text:
continue # 跳过不含"书包"的项
product_info = extract_product_info(item)
if product_info and product_info['name'] and product_info['price']:
products.append(product_info)
# 策略2:若结果少,补充提取数据属性中的商品
if len(products) < 10:
print("策略1结果较少,尝试策略2...")
products.extend(extract_by_data_attributes(soup))
# 策略3:文本模式匹配补充
if len(products) < 10:
print("策略2结果较少,尝试策略3...")
products.extend(extract_by_text_patterns(html))
# 去重处理(根据商品名称)
unique_products = []
seen_names = set()
for product in products:
if product['name'] and product['name'] not in seen_names and "书包" in product['name']:
unique_products.append(product)
seen_names.add(product['name'])
print(f"去重后获得{len(unique_products)}个书包商品")
# 添加到结果列表(控制总数)
for product in unique_products:
if len(goods_list) < max_items:
# 清理商品名称特殊字符
clean_name = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s\-\_]', '', product['name']).strip()
goods_list.append({
"name": clean_name,
"price": f"¥{product['price']}",
"price_value": float(product['price'])
})
print(f" ✓ {clean_name[:40]:<40} - ¥{product['price']}")
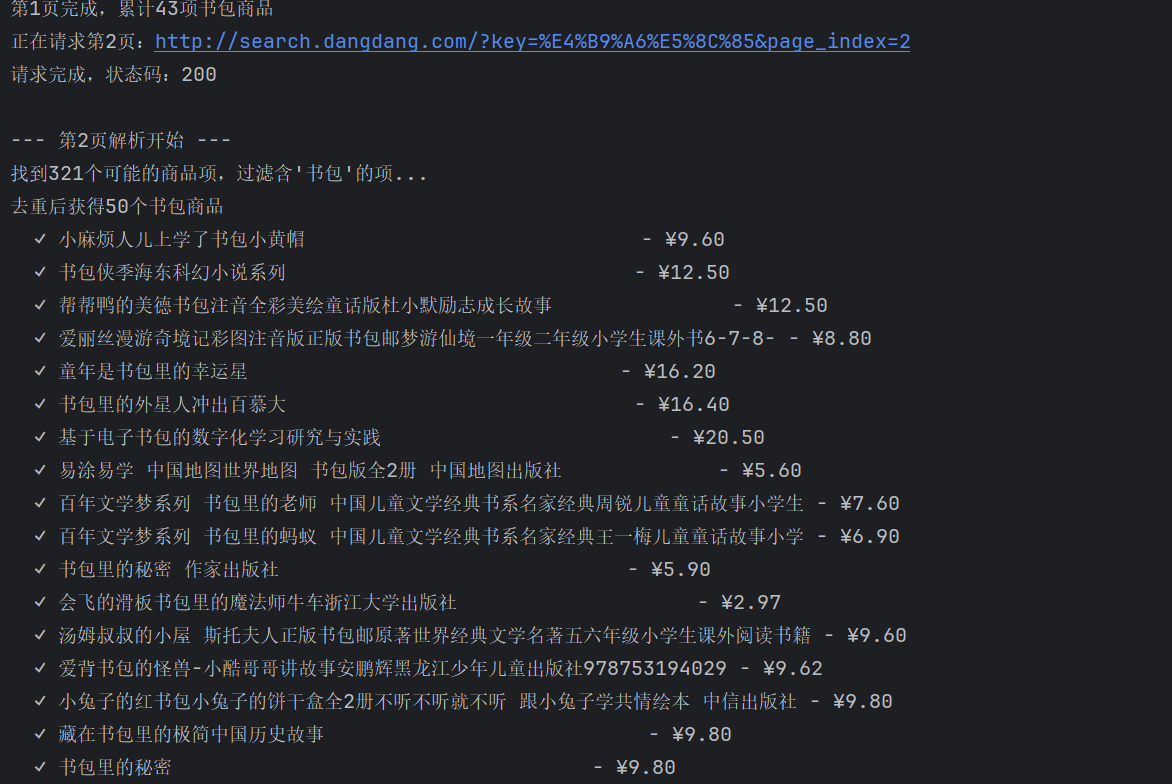
print(f"第{page}页完成,累计{len(goods_list)}项书包商品")
page += 1
time.sleep(1) # 爬取间隔避免请求过频
return goods_list
def extract_product_info(item):
"""从商品项中提取名称和价格"""
try:
name = None
price = None
# 提取商品名称(优先dd_name属性)
name_elem = item.find('a', attrs={'dd_name': '商品标题'})
if name_elem:
name = name_elem.get('title', '').strip() or name_elem.get_text(strip=True)
if not name:
name_elem = item.find('a', attrs={'title': True})
if name_elem:
name = name_elem.get('title', '').strip() or name_elem.get_text(strip=True)
if not name:
img_elem = item.find('img', attrs={'alt': True})
if img_elem:
name = img_elem.get('alt', '').strip()
# 提取价格
price_elem = item.find('span', class_='search_now_price')
if not price_elem:
price_elem = item.find('p', class_='price')
if not price_elem:
price_elem = item.find('span', class_=re.compile(r'price|money|now'))
if price_elem:
price_text = price_elem.get_text(strip=True)
price_match = re.search(r'¥?\s*(\d+\.?\d*)', price_text)
if price_match:
price = price_match.group(1)
# 清理格式
if name:
name = re.sub(r'\s+', ' ', name)
name = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s\-\_]', '', name).strip()
return {'name': name, 'price': price}
except Exception as e:
return {'name': None, 'price': None}
def extract_by_data_attributes(soup):
"""从脚本标签的JSON数据中提取商品"""
products = []
scripts = soup.find_all('script')
for script in scripts:
script_text = script.get_text()
if 'product' in script_text.lower() and '书包' in script_text:
json_matches = re.findall(r'\{[^{}]*"name":[^{}]*"price":[^{}]*\}', script_text)
for match in json_matches:
try:
match = re.sub(r'(\w+):', r'"\1":', match)
data = json.loads(match)
if 'name' in data and 'price' in data and "书包" in str(data['name']):
products.append({
'name': str(data['name']).strip(),
'price': str(data['price']).strip()
})
except:
pass
return products
def extract_by_text_patterns(html):
"""通过正则匹配提取商品"""
products = []
# 匹配书包的名称价格
pattern = r'''
title="([^"]*书包[^"]*)" # 商品名称
[^>]*>
[^<]*
¥\s*(\d+\.?\d*) # 价格
'''
matches = re.findall(pattern, html, re.VERBOSE | re.IGNORECASE | re.DOTALL)
for name, price in matches:
if len(name) > 5 and float(price) > 0:
products.append({
'name': name.strip(),
'price': price
})
return products
def print_enhanced_comparison(goods_list):
"""打印爬取结果(按价格排序)"""
if not goods_list:
print("\n未获取到有效书包商品数据")
return
# 按价格排序
sorted_goods = sorted(goods_list, key=lambda x: x["price_value"])
# 打印结果表格
print("\n" + "=" * 100)
print(f"{'当当网书包爬取结果(按价格排序)':^100}")
print("=" * 100)
print(f"{'序号':<4} | {'价格':<8} | {'商品名称':<60}")
print("-" * 100)
for idx, item in enumerate(sorted_goods, 1):
short_name = item["name"][:58] + ".." if len(item["name"]) > 60 else item["name"]
print(f"{idx:<4} | {item['price']:<8} | {short_name:<60}")
print("=" * 100)
print(f"\n爬取完成,共获取{len(goods_list)}件有效书包商品")
# 程序入口
if __name__ == "__main__":
try:
print("使用默认智能选择器策略,开始爬取...\n")
books_data = crawl_dangdang_books_v2("书包", 60)
print_enhanced_comparison(books_data)
except Exception as e:
print(f"程序执行出错: {e}")
import traceback
traceback.print_exc()
# 激进爬取
def crawl_dangdang_books_v3(keyword, max_items=60):
goods_list = []
page = 1
print(f"开始爬取当当网「{keyword}」商品(目标{max_items}项)...\n")
while page <= 3 and len(goods_list) < max_items:
encoded_keyword = quote(keyword, encoding="utf-8")
url = f"http://search.dangdang.com/?key={encoded_keyword}&page_index={page}"
print(f"正在请求第{page}页:{url}")
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36"
}
try:
response = http.request("GET", url, headers=headers, timeout=10)
html = response.data.decode("gbk", errors="replace")
soup = BeautifulSoup(html, 'html.parser')
# 提取书包的商品名称
potential_names = []
for a in soup.find_all('a', href=True):
title = a.get('title', '').strip()
if title and len(title) > 10 and "书包" in title:
potential_names.append(title)
# 提取价格
prices = []
price_pattern = re.compile(r'¥\s*(\d+\.?\d*)')
for text in soup.stripped_strings:
match = price_pattern.search(text)
if match:
prices.append(match.group(1))
# 匹配名称和价格
min_len = min(len(potential_names), len(prices))
for i in range(min_len):
if len(goods_list) < max_items:
clean_name = re.sub(r'[^\u4e00-\u9fa5a-zA-Z0-9\s\-\_]', '', potential_names[i])
goods_list.append({
"name": clean_name,
"price": f"¥{prices[i]}",
"price_value": float(prices[i])
})
print(f" 找到: {clean_name[:40]:<40} - ¥{prices[i]}")
print(f"第{page}页完成,找到{min_len}个书包商品,累计{len(goods_list)}项")
page += 1
time.sleep(1)
except Exception as e:
print(f"第{page}页出错:{e}")
page += 1
continue
return goods_list


2. 实验心得
- 观察要爬网页当当网的商品价格的提取源码
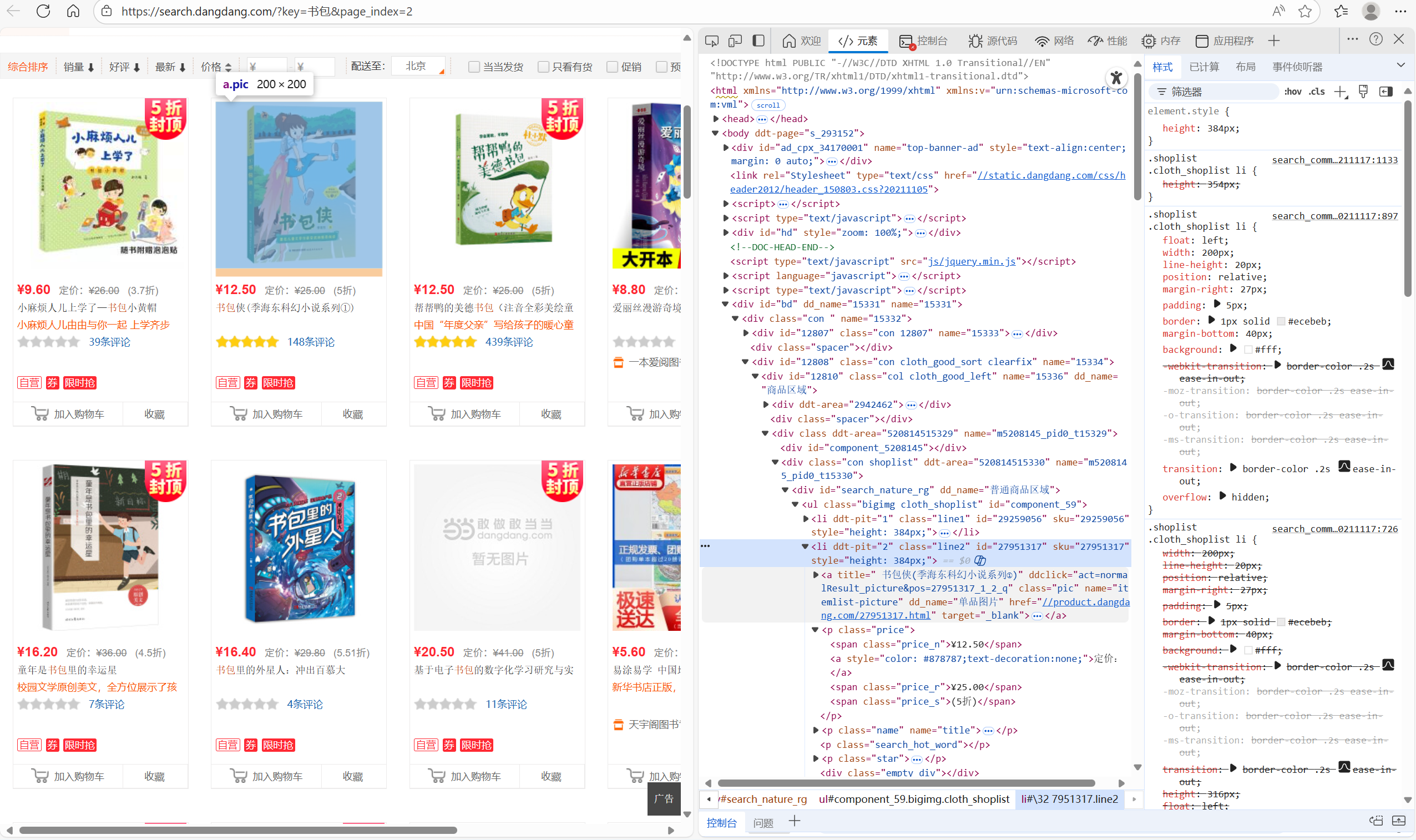

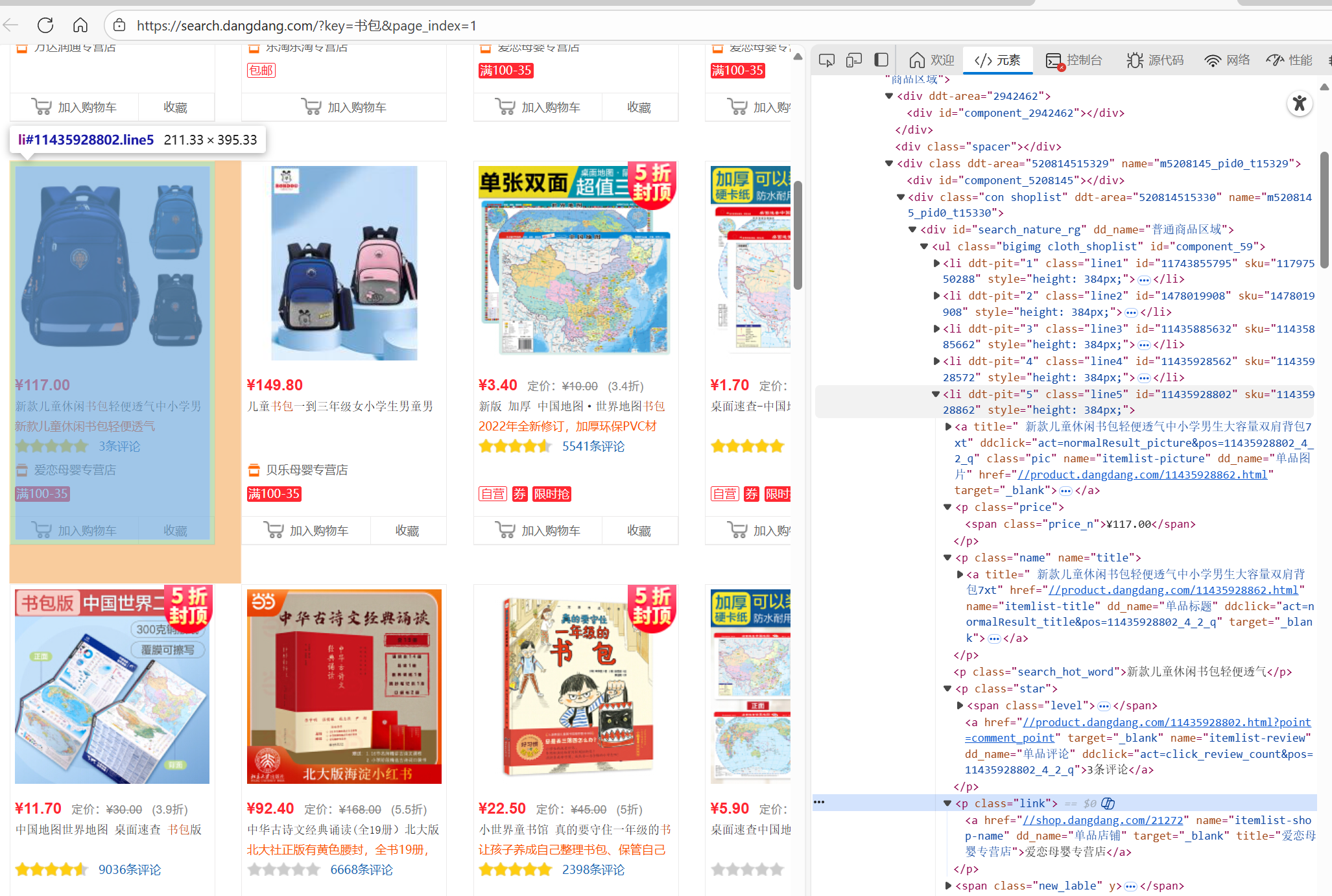
- 分析正则表达式含义
- 匹配商品名称 title="(["]*书包["])"
title=":匹配 HTML 中title属性的开头。
(["]*书包["]):
括号 () 表示捕获组(用于提取匹配到的内容)。
[^"]* 表示 “匹配任意非双引号字符,且可重复多次”。
中间的书包是关键词,确保只匹配含 “书包” 的商品名称。 - 匹配价格 ¥\s(\d+.?\d)
¥:匹配人民币符号 “¥”。
\s:匹配 “任意空白字符(空格、制表符等),可重复多次”,用于兼容价格前的空格。
(\d+.?\d):
括号 () 表示捕获组,用于提取价格数值。
\d+ 表示 “匹配 1 个或多个数字”。
.? 表示 “匹配 0 个或 1 个小数点”。
\d* 表示 “匹配 0 个或多个数字”。
- 正则表达式抓取解释
代码中extract_by_text_patterns函数的正则是核心,用于从 HTML 文本中直接匹配 “书包” 商品的名称和价格,结构如下:title="([^"]*书包[^"]*)" # 匹配含“书包”的商品名称 [^>]*> [^<]* ¥\s*(\d+\.?\d*) # 匹配价格数值 - 各部分作用拆解:
title="(["]*书包["])":
title=":匹配 HTML 中title属性的开头。
(["]*书包["]):
括号()是捕获组,用于提取匹配到的内容。
[^"]:匹配 “任意非双引号字符,可重复多次”,确保在双引号内匹配。
中间的书包是关键词,过滤无关商品,只保留含 “书包” 的名称。
[^>]> 和 [^<]:
这两部分是 “跳过无关内容” 的逻辑,匹配标签和文本中的非关键字符,确保正则能定位到价格区域。
¥\s(\d+.?\d):
¥:匹配人民币符号 “¥”。
\s:匹配 “任意空白字符,可重复多次”,兼容价格前的空格。
(\d+.?\d):
括号()是捕获组,提取价格数值。
\d+:匹配 “1 个或多个数字”。
.?:匹配 “0 个或 1 个小数点”。
\d:匹配 “0 个或多个数字”。 - 匹配效果示例:
对于 HTML 片段:<a title="小学生书包 轻便减负 蓝色款" href="...">...</a> <span class="price">¥29.90</span>
正则会匹配到:
捕获组 1(名称):小学生书包 轻便减负 蓝色款
捕获组 2(价格):29.90 - 作业三
1. 完整代码及运行结果
点击查看代码
import re
import urllib.request
import os
from colorama import Fore, Style, init
init(autoreset=True)
def get_html(url):
headers = {"User-Agent": "Mozilla/5.0"}
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as response:
html = response.read().decode("utf-8", errors="ignore")
return html
def get_jpg_links(html, base_url):
# 匹配 .jpg 文件链接
pattern = re.compile(r'src="([^"]+?\.jpg)"', re.IGNORECASE)
links = pattern.findall(html)
domain = re.match(r"(https?://[^/]+)", base_url).group(1)
full_links = []
for link in links:
if link.startswith("http"):
full_links.append(link)
elif link.startswith("/"):
full_links.append(domain + link)
else:
full_links.append(base_url.rsplit("/", 1)[0] + "/" + link)
return list(set(full_links))
def download_images(links, folder="images"):
if not os.path.exists(folder):
os.makedirs(folder)
for i, url in enumerate(links, start=1):
try:
filename = os.path.join(folder, f"img_{i}.jpg")
urllib.request.urlretrieve(url, filename)
print(Fore.GREEN + f"下载成功: {filename}")
except Exception as e:
print(Fore.RED + f"下载失败: {url} ({e})")
if __name__ == "__main__":
base_pages = [
"https://news.fzu.edu.cn/yxfd.htm",
"https://news.fzu.edu.cn/yxfd/1.htm",
"https://news.fzu.edu.cn/yxfd/2.htm",
"https://news.fzu.edu.cn/yxfd/3.htm",
"https://news.fzu.edu.cn/yxfd/4.htm",
"https://news.fzu.edu.cn/yxfd/5.htm",
]
all_links = []
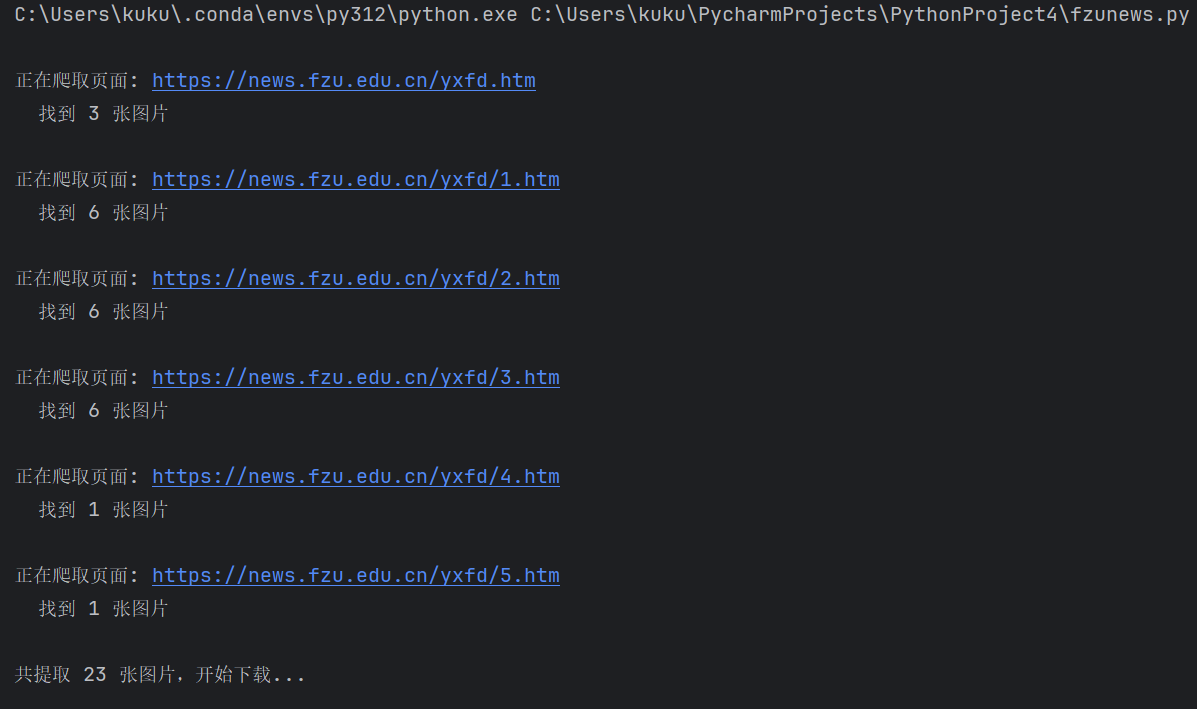
for page in base_pages:
print(f"\n正在爬取页面: {page}")
html = get_html(page)
links = get_jpg_links(html, page)
print(f" 找到 {len(links)} 张图片")
all_links.extend(links)
# 去重
all_links = list(set(all_links))
print(f"\n共提取 {len(all_links)} 张图片,开始下载...\n")
download_images(all_links)
print("\n 所有图片下载完成!")
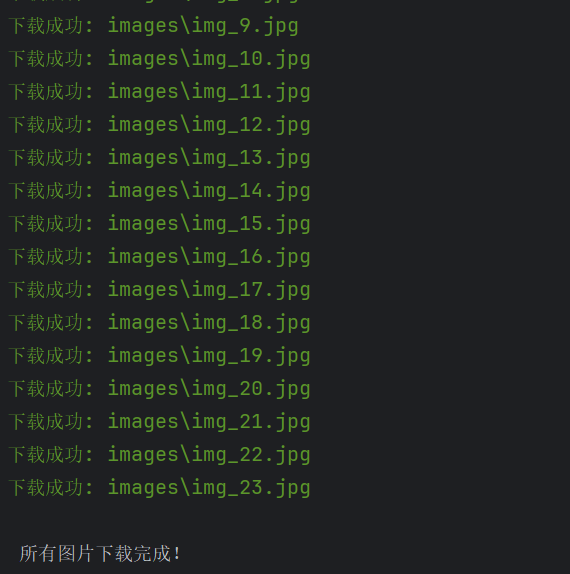
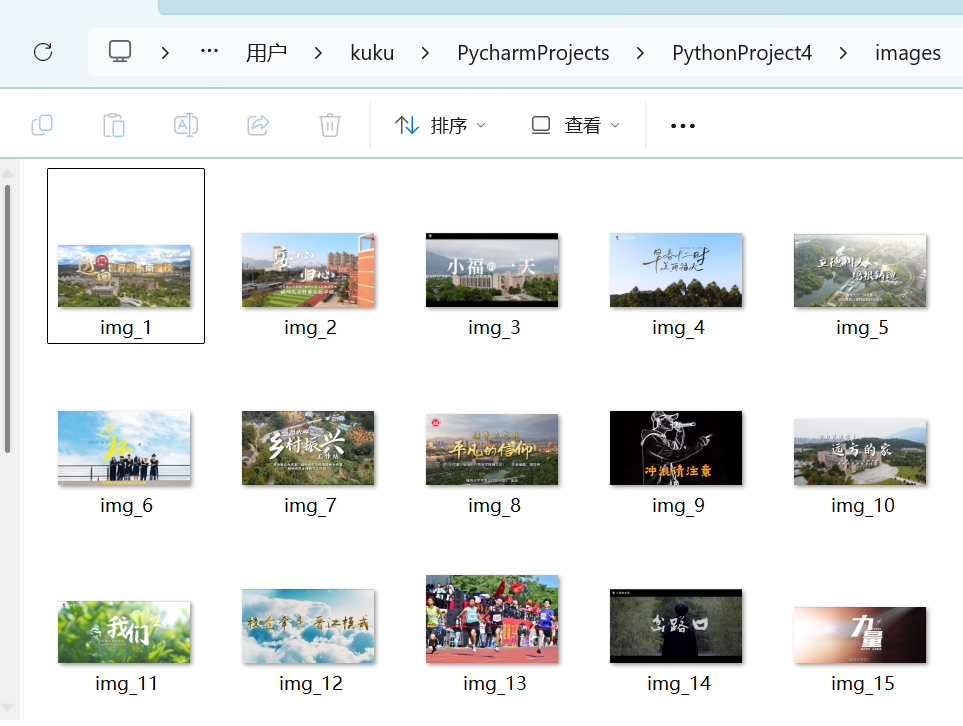
2. 心得体会
- 爬取指定网页中的所有 JPG 图片并下载到本地,正则表达式是实现图片链接提取的关键。
代码分为网页请求、图片链接提取、图片下载三个阶段:
网页请求:通过urllib.request模拟浏览器请求,获取目标网页的 HTML 内容。
图片链接提取:用正则表达式从 HTML 中匹配所有.jpg格式的图片链接,并处理相对路径为绝对路径。
图片下载:将提取的图片链接批量下载到本地文件夹,同时处理下载异常。 - 正则表达式解释
核心正则位于get_jpg_links函数中,用于匹配 HTML 中的 JPG 图片链接,表达式为src="([^"]+?\.jpg)"
并通过re.IGNORECASE忽略大小写。
src=":匹配 HTML 中图片标签的src属性开头。
([^"]+?.jpg):
["]+?:["]表示 “匹配任意非双引号字符”,+?表示 “尽可能少地匹配多次”(非贪婪模式),确保在双引号内精准截取链接。
.jpg:匹配.jpg后缀(.转义表示实际的小数点,jpg为图片格式)。
re.IGNORECASE:忽略大小写,兼容.JPG、.Jpg等格式的图片。 - 匹配效果示例:
正则会匹配到两个捕获组:
https://example.com/photo.jpg
/static/images/pic.JPG - 这段代码我还运用到文件路径提取
提取到相对路径的链接后,代码会进行绝对路径转换:
若链接以http开头:直接作为绝对路径。
若链接以/开头:拼接域名(如https://news.fzu.edu.cn)形成绝对路径。
其他情况:拼接网页的上级路径形成绝对路径。
这样确保所有图片链接都能被正确访问和下载。
代码地址:https://gitee.com/sike-0420/kuku/tree/master/%E4%BD%9C%E4%B8%9A1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号