梯度提升决策树(GBDT)与XGBoost、LightGBM
一、Boosting
GBDT属于集成学习(Ensemble Learning)中的boosting算法。
Boosting算法过程如下:
(1) 分步去学习weak classifier,最终的strong claissifier是由分步产生的classifier’组合‘而成的
(2) 根据每步学习到的classifier去reweight样本(分错的样本权重加大,反之减小)
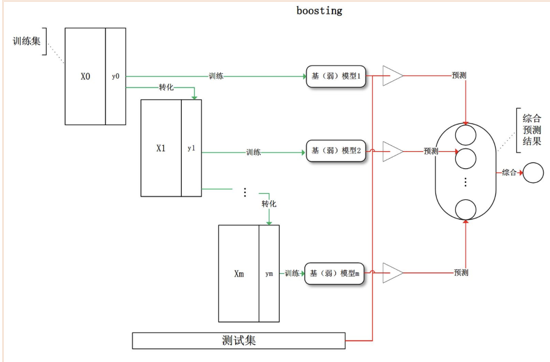
Boosting实际采用加法模型(classifier的线性组合)+前向分布,如果每次在Boosting中的基函数(classifier)使用决策树的算法就是Boosting Tree.
Boosting更像是一种思想, gradient boosting是一种boosting的方法. 它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向,假设分步模型下当前模型是f(x),利用损失函数L的负梯度在f(x)下的值作为boosting tree算法中的残差(residual)去拟合一个回归树。
GBDT的全称是Gradient Boosting Decision Tree,Gradient Boosting和Decision Tree是两个独立的概念。因此我们先说说Boosting。Boosting的概念很好理解,意思是用一些弱分类器的组合来构造一个强分类器。因此,它不是某个具体的算法,它说的是一种理念。和这个理念相对应的是一次性构造一个强分类器。像支持向量机,逻辑回归等都属于后者。通常,我们通过相加来组合分类器,形式如下:
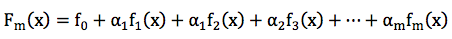
GBDT和xgboost和lightGBM在竞赛和工业界使用都非常频繁,能有效的应用到分类、回归、排序问题,GBDT 中的决策树是回归树,预测结果是一个数值,在点击率预测方面常用 GBDT,例如用户点击某个内容的概率。虽然使用起来不难,但是要能完整的理解还是有一点麻烦的。本文尝试一步一步梳理GB、GBDT并简要介绍xgboost、lightgbm,它们之间有非常紧密的联系,GBDT是以决策树(CART)为基学习器的GB算法,xgboost扩展和改进了GBDT,xgboost算法更快,准确率也相对高一些,lightgbm则是在xgboost的基础上,根据xgboost存在的缺点,进一步改进优化。。
二、 Gradient Boosting(GB)
机器学习中的学习算法的目标是为了优化或者说最小化loss Function, Gradient boosting的思想是迭代生多个(M个)弱的模型,然后将每个弱模型的预测结果相加,后面的模型Fm+1(x)基于前面学习模型的Fm(x)的效果生成的,关系如下:


GB算法的思想很简单,关键是怎么生成h(x)?
如果损失函数是回归问题的平方误差,很容易想到最理想的h(x)应该是能够完全拟合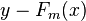 ,这就是常说基于残差的学习,也就是Boosting Tree算法(《统计学习方法》中的算法8.3:回归树算法)。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题的损失函数为
,这就是常说基于残差的学习,也就是Boosting Tree算法(《统计学习方法》中的算法8.3:回归树算法)。残差学习在回归问题中可以很好的使用,但是为了一般性(分类,排序问题),实际中往往是基于loss Function 在函数空间的的负梯度学习,对于回归问题的损失函数为![]() 时,残差和负梯度也是相同的。
时,残差和负梯度也是相同的。 中的f,不要理解为传统意义上的函数,而是一个函数向量
中的f,不要理解为传统意义上的函数,而是一个函数向量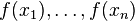 ,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”,由于此时基于损失函数空间的负梯度学习,因此就是Gradient Boosting Tree算法。
,向量中元素的个数与训练样本的个数相同,因此基于Loss Function函数空间的负梯度的学习也称为“伪残差”,由于此时基于损失函数空间的负梯度学习,因此就是Gradient Boosting Tree算法。
Boosting Tree算法是Gradient Boosting Tree算法的损失函数采用平方损失函数时的特殊情况,此时2(a)中损失函数的负梯度方向rmi= y - fm-1(xi),即我们所说的残差,此时2(c)中的cmj即为该区域Rmj中y的平均值。
所以GB算法的大致步骤如下图(《统计学习方法》中的算法8.4:梯度提升算法):

步骤(2)即为迭代生成M个基学习器的步骤
2(a)表示计算损失函数的负梯度在当前模型的值,将其作为残差的估计值(拟残差);
2(b)表示估计回归树叶子节点的区域,以拟合残差的近似值; 其实也就是把拟残差单做目标变量,划分目标区域,然后结合(c)进一步生成回归树。
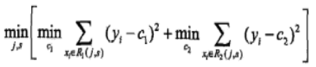 ,以损失函数为平方损失函数时寻找切分点的公式为例,损失函数为其他函数时,
,以损失函数为平方损失函数时寻找切分点的公式为例,损失函数为其他函数时,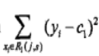 用
用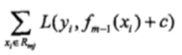 替换。
替换。
2(c)表示利用线性搜索估计叶子节点区域的值,使得损失函数最小化;
2(d)更新回归树;
三、Gradient Boosting Decision Tree
理解GBDT重点首先是Gradient Boosting,其次才是 Decision Tree。GBDT 是 Gradient Boosting 的一种具体实例,只不过这里的弱分类器是决策树。如果你改用其他弱分类器 XYZ(选择的前提是低方差和高偏差。框架服从boosting 框架即可。),你也可以称之为 Gradient Boosting XYZ。只不过 Decision Tree 很好用,GBDT 才如此引人注目。
GB算法中最典型的基学习器是决策树,尤其是CART,正如名字的含义,GBDT是GB和DT的结合。要注意的是这里的决策树是回归树,GBDT中的决策树是个弱模型(由于boosting模型会在每一轮的基础上更加拟合数据,可以保证bias,因此每个基学习器需要保证低variance,这与bagging模型的RF正好相反),深度较小一般不会超过5,叶子节点的数量也不会超过10,对于生成的每棵决策树乘上比较小的缩减系数(学习率<0.1),有些GBDT的实现加入了随机抽样(subsample 0.5<=f <=0.8)提高模型的泛化能力。通过交叉验证的方法选择最优的参数。因此GBDT实际的核心问题在于2(b),基学习器的生成,也就是CART回归树的生成。在我之前的博客中已经详述了CART回归树的生成,在这就不再介绍了。
四、GBDT用于分类
GBDT中的DT是回归树,但GBDT也可以解决分类问题,解决办法是用softmax来产生原本离散型label的概率,进而可以用解决回归问题的思路来解决分类问题。
以下内容摘自博客https://www.cnblogs.com/ModifyRong/p/7744987.html,感谢博主的分享,具体GBDT用于分类的例子在博客中有详细介绍。


五、XGBoost
Xgboost是GB算法的高效实现,xgboost中的基学习器除了可以是CART(gbtree)也可以是线性分类器(gblinear)。下面所有的内容来自原始paper,包括公式。
(1). xgboost在目标函数中显示的加上了正则化项,基学习为CART时,正则化项与树的叶子节点的数量T和叶子节点的值有关。
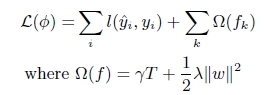
(2). GB中使用Loss Function对f(x)的一阶导数计算出伪残差用于学习生成fm(x),xgboost不仅使用到了一阶导数,还使用二阶导数。
第t次的loss:
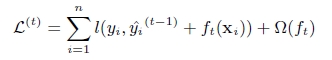
对上式做二阶泰勒展开:g为一阶导数,h为二阶导数
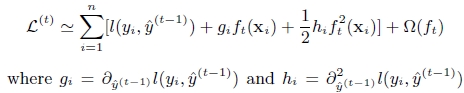
(3). 上面提到CART回归树中寻找最佳分割点的衡量标准是最小化均方差,xgboost寻找分割点的标准是最大化,lamda,gama与正则化项相关
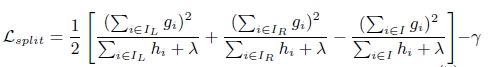
xgboost算法的步骤和GB基本相同,都是首先初始化为一个常数,gb是根据一阶导数ri,xgboost是根据一阶导数gi和二阶导数hi,迭代生成基学习器,相加更新学习器。
xgboost与gdbt除了上述三点的不同,xgboost在实现时还做了许多优化:
-
- 在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
- xgboost考虑了训练数据为稀疏值的情况,可以为缺失值或者指定的值指定分支的默认方向,这能大大提升算法的效率,paper提到50倍。
- 特征列排序后以块的形式存储在内存中,在迭代中可以重复使用;虽然boosting算法迭代必须串行,但是在处理每个特征列时可以做到并行。
- 按照特征列方式存储能优化寻找最佳的分割点,但是当以行计算梯度数据时会导致内存的不连续访问,严重时会导致cache miss,降低算法效率。paper中提到,可先将数据收集到线程内部的buffer,然后再计算,提高算法的效率。
- xgboost 还考虑了当数据量比较大,内存不够时怎么有效的使用磁盘,主要是结合多线程、数据压缩、分片的方法,尽可能的提高算法的效率。
六、LightGBM
概括来说,lightGBM主要有以下特点:
-
-
基于Histogram的决策树算法
-
带深度限制的Leaf-wise的叶子生长策略
-
直方图做差加速
-
直接支持类别特征(Categorical Feature)
-
Cache命中率优化
-
基于直方图的稀疏特征优化
-
多线程优化
-
前2个特点使我们尤为关注的。
Histogram算法
直方图算法的基本思想:先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。遍历数据时,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效算法,因为它不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。
Leaf-wise则是一种更为高效的策略:每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。
Leaf-wise的缺点:可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
七、总结
本文详细介绍了集成模型中的Boosting思想,以及gradient Boosting、GBDT的算法流程,XGBoost以及lightGBM都是在GB以及GBDT基础上的优化和改进,本文并没有详细分析原理,仅简单的对比了优缺点。
总结GBDT的部分优点:
GBDT 它的非线性变换比较多,表达能力强,而且不需要做复杂的特征工程和特征变换。
GBDT是拿Decision Tree作为GBM里的弱分类器,GBDT的优势 首先得益于 Decision Tree 本身的一些良好特性,具体可以列举如下:
- Decision Tree 可以很好的处理 missing feature,这是他的天然特性,因为决策树的每个节点只依赖一个 feature,如果某个 feature 不存在,这颗树依然可以拿来做决策,只是少一些路径。像逻辑回归,SVM 就没这个好处。
-
Decision Tree 可以很好的处理各种类型的 feature,也是天然特性,很好理解,同样逻辑回归和 SVM 没这样的天然特性。
-
对特征空间的 outlier 有鲁棒性,因为每个节点都是 x < 𝑇 的形式,至于大多少,小多少没有区别,outlier 不会有什么大的影响,同样逻辑回归和 SVM 没有这样的天然特性。
-
如果有不相关的 feature,没什么干扰,如果数据中有不相关的 feature,顶多这个 feature 不出现在树的节点里。逻辑回归和 SVM 没有这样的天然特性(但是有相应的补救措施,比如逻辑回归里的 L1 正则化)。
-
数据规模影响不大,因为我们对弱分类器的要求不高,作为弱分类器的决策树的深 度一般设的比较小,即使是大数据量,也可以方便处理。像 SVM 这种数据规模大的时候训练会比较麻烦。
当然 Decision Tree 也不是毫无缺陷,通常在给定的不带噪音的问题上,他能达到的最佳分类效果还是不如 SVM,逻辑回归之类的。但是,我们实际面对的问题中,往往有很大的噪音,使得 Decision Tree 这个弱势就不那么明显了。而且,GBDT 通过不断的叠加组合多个小的 Decision Tree,他在不带噪音的问题上也能达到很好的分类效果。换句话说,通过GBDT训练组合多个小的 Decision Tree 往往要比一次性训练一个很大的 Decision Tree 的效果好很多。因此不能把 GBDT 理解为一颗大的决策树,几颗小树经过叠加后就不再是颗大树了,它比一颗大树更强。
参考链接:
https://cloud.tencent.com/developer/article/1005611
http://blog.csdn.net/gavin__zhou/article/details/71156715
https://www.cnblogs.com/wxquare/p/5541414.html
https://www.cnblogs.com/bentuwuying/p/6667267.html
https://www.cnblogs.com/ModifyRong/p/7744987.html
http://blog.csdn.net/niaolianjiulin/article/details/76584785

 浙公网安备 33010602011771号
浙公网安备 33010602011771号