
机器学习(一)之KNN算法
knn算法原理
①.计算机将计算所有的点和该点的距离
②.选出最近的k个点
③.比较在选择的几个点中那个类的个数多就将该点分到那个类中
KNN算法的特点:
knn算法的优点:精度高,对异常值不敏感,无数据假设
knn算法的缺点:时间复杂度和空间复杂度都比较高
knn算法中遇到的问题及其解决办法
1、当样本不平衡时,比如一个类的样本容量很大,其他类的样本容量很小,输入一个样本的时候,K个临近值中大多数都是大样本容量的那个类,这时可能就会导致分类错误。改进方法是对K临近点进行加权,也就是距离近的点的权值大,距离远的点权值小。
2、计算量较大,每个待分类的样本都要计算它到全部点的距离,根据距离排序才能求得K个临近点,改进方法是:先对已知样本点进行剪辑,事先去除对分类作用不大的样本。
knn算法数据范围:数值型和标称型
注意:数据是二维的,第一维表示样本,第二维表示特征(如手写数字算法,)
标称型:标称型目标变量的结果只在有限目标集中取值,如真与假(标称型目标变量主要用于分类)
数值型:数值型目标变量则可以从无限的数值集合中取值,如0.100,42.001等 (数值型目标变量主要用于回归分析)
knn算法的应用
案例:
import numpy as np
import pandas as pd
# KNeighborsClassifer 用于分类问题的处理
from sklearn.neighbors import KNeighborsClassifier
# 导入数据:
movie = pd.read_excel("./data/movies.xlsx",sheet_name=1)
movie
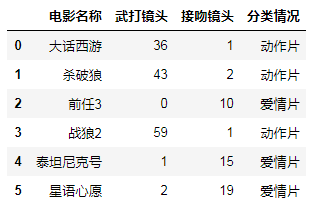
#根据电影的武打镜头和接吻镜头的数量判断电影的类型
#knn算法是有监督学习,需要样本训练数据,和目标值进行对照
提取数据:
x = movie.iloc[:,1:3]
y = movie["分类情况"]
# 此时K值等于5,即5个邻居
knn=KNeighborsClassifier(n_neighbors=5)
# 训练算法:fit()以X为训练数据,y为目标值拟合模型
knn.fit(x,y)
#数据进行l训练,已经建立了一个分类标准
#添加2个样本数据
x_text = pd.DataFrame({"武打镜头":[120,10],"接吻镜头":[5,80]})
# 使用算法预测目标样本的分类情况
knn.predict(x_text)
预测结果:
array(['动作片', '爱情片'], dtype=object)
#从结果可以看出:第一个样本被划分到动作片中,第二个样本被划分到爱情片中
#对样本进行估计被划分到哪个类的概率
knn.predict_proba(x_text)
估计结果结果:array([[0.6, 0.4], [0.4, 0.6]])
注意:knn算法是根据距离远近进行分类的划分,K为最近的样本。
当训练数据样本不均衡是,对数据处理的办法
给knn加权重,即weight = ["uniform","distance","calllable"] 即:均衡、距离、自定义
如:
knn=KNeighborsClassifier(n_neighbors=5,weights="distance")
算法的保存和算法的加载
当我们对算法进行了训练之后,想要再次使用该算法进行预测时,就不需要再次进行算法的训练了,直接使用保存的算法,对需要进行分类的样本进行分类就行
#算法保存
#应用模块
from sklearn.externals import joblib
#存储样本的方式:
joblib.dump(knn,filename = "./digit_detector.m")
#filename后边自定义后缀为m的文件名
#算法的加载
from sklearn.externals import joblib
#加载之前保存的算法
knn = joblib.load("./digit_detector.m")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号