flex_bison
flex_bison
flex
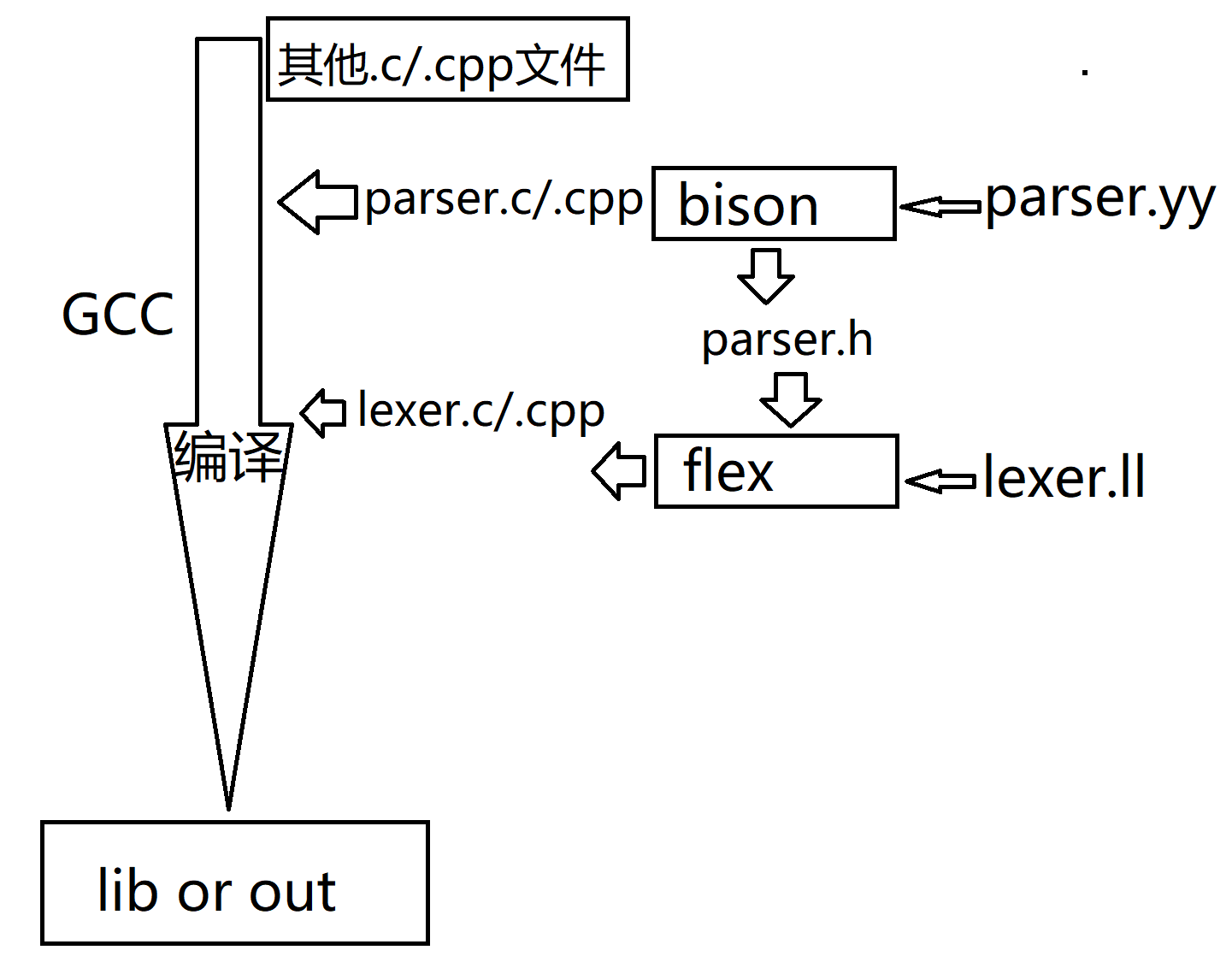
- flex词法分析器,可以利用正则表达式来生成匹配相应字符串的C语言代码,其语法格式基本同Lex相同。单词的描述称为模式(Lexical Pattern),模式一般用正规表达式进行精确描述。FLEX通过读取一个有规定格式的文本文件,输出一个C语言源程序。
- FLEX的输入文件称为LEX源文件,它内含正规表达式和对相应模式处理的C语言代码。LEX源文件的扩展名习惯上用.l表示。FLEX通过对源文件的扫描自动生成相应的词法分析函数int yylex(),并将之输出到名规定为lex.yy.c的文件中。实用时,可将其改名为lexyy.c。
- fex的输入是文件由3部分组成:definetion %% rules %% code 使用%%分隔
定义: definition %{ %} %% 规则: rules %% 用户代码:code- definetion的工作是定义变量声明及预编译宏定义等
%{ int a; int b; %}- 输入中的信息以正则表达式和C代码的形式组成,这些形式被称为规则rules,使用的是python正则表达
- code用户代码,支持c/c++
bison
- rules正则原子
-
python正则表达全原子操作
- 字符类
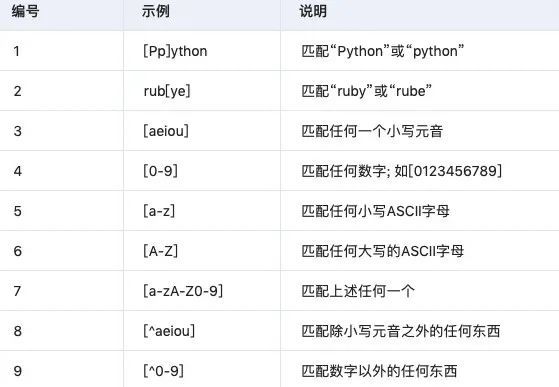
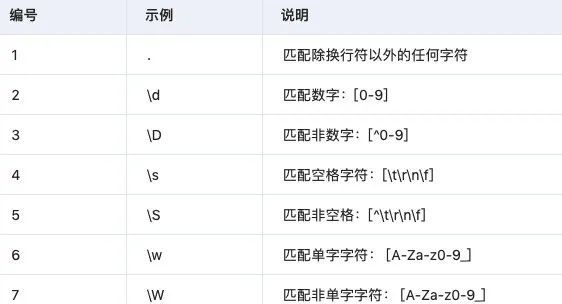
- 特殊字符类
- 重复匹配
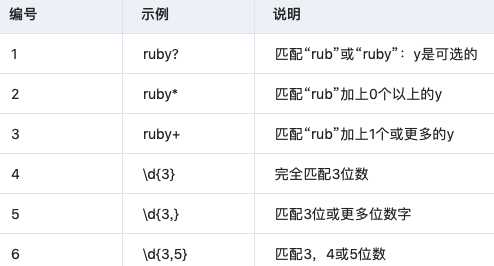
- 非贪婪重复
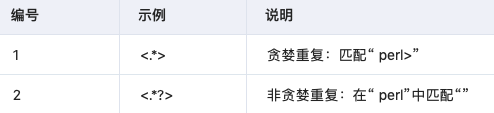
- 圆括号分组
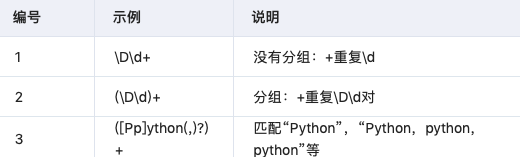
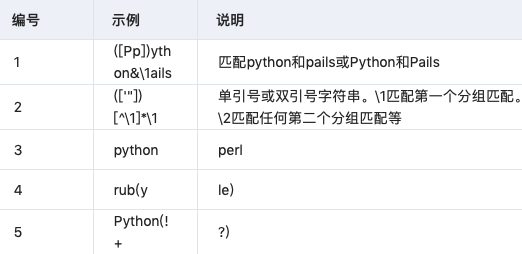
- 反向引用
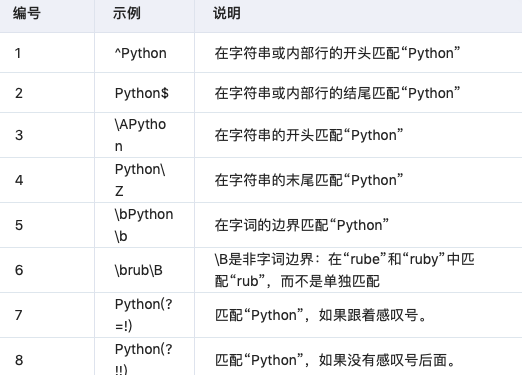
- 锚点
- 带括号特殊语法
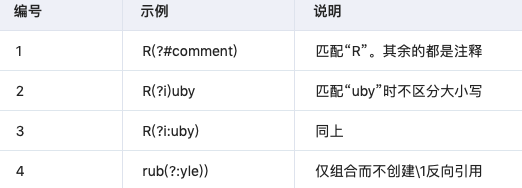
- 字符类
-
正则表达式的常用操作符
操作符 说明 实例 . 表示任何单个字符 [] 字符集,对单个字符给出取值范围 [abc]表示a,b,c,[a-z]表示a到z单个字符 [^] 非字符集,对单个字符给出排除范围 [^abc]表示非a或b或c的单个字符 * 前一个字符0次或无限次扩展 abc* 表示ab,abc,abcc,abccc等 + 前一个字符1次或无限次扩展 abc+ 表示abc,abcc,abccc等 ? 前一个字符0次或1次扩展 abc?表示ab,abc | 左右表达式任何一个 abc|def表示abc、def 更多操作 操作符 实例 扩展前一个字符m次 ab{2}c 表示abbc 扩展前一个字符m至n次(含n) ab{1,2}c 表示abc,abbc ^ 匹配字符串的开头 ^abc 表示 abc且在一个字符串的开头 $ 匹配字符串结尾 abc$ 表示abc且在一个字符串的结尾 () 分组标记,内部智能使用 | 操作符 (abc) 表示abc, (abc|def)表示abc,def \d 数字,等价于[0-9] \w 单词字符,等价于[A-Za-z0-9_] 字符 描述 \cx 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 \f 匹配一个换页符。等价于 \x0c 和 \cL。 \n 匹配一个换行符。等价于 \x0a 和 \cJ。 \r 匹配一个回车符。等价于 \x0d 和 \cM。 \s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。 \S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 \t 匹配一个制表符。等价于 \x09 和 \cI。 \v 匹配一个垂直制表符。等价于 \x0b 和 \cK。 -
经典正则表达式举例
--- --- ^[A-Za-z]+$ 由26个字母组成的字符串 ^[A-Za-z0-9]+$ 由26个字母和数字组成的字符串 ^-?\d+$ 整数形式的字符串 ^[1-9][1-9][0-9]$ 正整数星时代娿字符串 [1-9]\d 中国境内邮政编码,6位 [\u4e00-\u9fa5] 匹配中文字符 \d{3}-\d{8}|d{4}-\d 国内电话号码,010-68913536

 浙公网安备 33010602011771号
浙公网安备 33010602011771号