Mysql索引
InnoDB索引模型
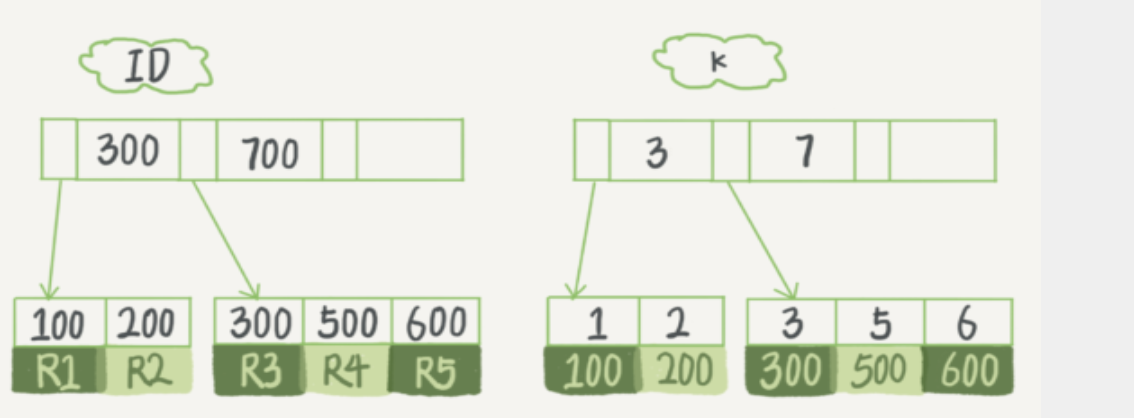
主键索引的叶子节点存的是整行数据,主键索引也被称为聚集索引。
非主键索引的叶子节点内容是主键的值。非主键索引也被称为非聚集索引或二级索引。
基于主键索引和普通索引的查询有何区别?
- 若查询SQL为 select * from T where ID = 300,即主键查询,只需搜索ID这棵B+树。
- 若查询SQL为 select * from T where K = 3,即普通索引查询,需要先搜索K这棵B+树,得到ID值为300,再到ID索引树搜索一次,这个过程称为 "回表"。
也就是说,基于非主键索引的查询需要多扫描一棵索引树,因此,我们在查询时尽量使用主键查询。
为什么InnoDB最好以自增列作为主键?
- InnoDB引擎表是基于B+树的索引组织表(IOT);
- 每个表都需要有一个聚集索引(clustered index);
- 所有的行记录都存储在B+树的叶子节点(leaf pages of the tree);
- 基于聚集索引的增、删、改、查的效率相对是最高的;
- 如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择其作为聚集索引;
- 如果没有显示定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引做为主键索引;
- 如果连唯一索引也没有,则InnoDB会选择内置6字节长的ROWID做为主键(ROWID随着行记录的写入而主键递增,是隐含的,不可引用);
主键索引
- 数据的存储的逻辑顺序和索引的顺序是相同的。
- 每个表可以有多个索引,但表的存储顺序只能有一种, Innodb是按照主键索引的顺序来组织表。
- 采用一个没有业务用途的自增属性列作为主键: 数据类型int/bigint
- Innodb选择主键为聚簇索引,查询性能受益于NOT NULL优化
Innodb聚簇索引选择顺序:显式主键、第1个不为空的唯一索引、rowID(6byte)
索引维护
B+树为了维护索引有序性,插入新值的时候需要坐必要的维护。

如果插入新的行ID为700,则只需在R5后插入一条数据;
如果插入的新行ID为400,则需要逻辑上挪动500和600的数据,空出位置。但如果R5所在页已满,根据B+树的算法,此时需要申请一个新的数据页,然后挪动部分数据过去。这个过程称为页分裂。在这种情况下,性能自然会受影响;
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低约50%;
当然有分裂就有合并。当相邻两个页由于删除了数据,利用率很低之后,会将数据页做合并。页合并的过程,可以认为是分裂过程的逆过程;
索引维护规则:
-INSERT
- 在Clustered B+Tree上插入一条记录
- 在所有其他Secondary B+Tree上插入一条记录(仅包含索引字段和主键)
-DELETE
- 在Clustered B+Tree上删除一条记录
- 在所有其他Secondary B+Tree上删除二级索引记录
-UPDATE非主键列
- 在Clustered B+Tree上更新记录
-UPDATE主键列
- 在Clustered B+Tree删除原有的记录(只是标记为DELETED,并不真正删除)。
- 在Clustered B+Tree插入一条新的记录。
- 在每一个Secondary B+Tree上删除原有的记录。
- 在每一个Secondary B+Tree上插入一个条新的记录。
-UPDATE辅助索引的键值
- 在Clustered B+Tree上更新数据
- 在每一个Secondary B+Tree上删除原有的记录。
- 在每一个Secondary B+Tree上插入一个条新的记录。
常见索引类型
唯一索引
不允许索引具有相同的行(禁止重复key)
唯一约束和主键是一样的
允许有null值
一个表只能有一个主键,但可以有多个唯一索引
唯一索引 VS 普通索引
从查询上来讲:
- 对于普通索引来说,查找到满足条件的第一个记录后,需要查找下一个记录,直到碰到第一个不满足条件的记录
- 对于唯一索引来说,由于索引定义了唯一性,查找到第一个满足条件的记录后,就会停止继续检索
从更新上来讲:

1. 如果目标页在内存中
- 对于唯一索引,找到3和5之间的位置,判断有无冲突,若无则插入值,语句执行结束。
- 对于普通索引,找到3和5之间的位置,直接插入值,语句执行结束。
2.如果目标页不在内存中
- 对于唯一索引,需要将数据页读入内存,判断有无冲突,若无则插入值,语句执行结束。
- 对于普通索引,则是将更新记录在change buffer,语句执行就结束了。
总结:
- 查询上:普通索引只是比唯一索引多了一个一次指针寻找和一次计算,由于数据是按页读取的,数据几乎都在内存中,所以性能相差不大。
-
更新上:如果数据不在内存中,唯 一索引需要将数据从磁盘上读取到内存中,这样会引发随机读,导致IO消耗增多,而普通索引可以利用change buffer,IO上边要节省很多。性能相差会很多,所以如果可以在业务端保证数据的唯一性,那就可以使用普通索引。
联合索引
联合索引:表中两个或两个以上的列创建的索引 (create index idx_age_height on T(age,height);)
联合索引建议:
- where条件中,同时出现的列可以加联合索引
- 选择性大的列放在索引的最左边,最左匹配原则
联合索引失效情况:
- 通过索引扫描的行记录数超过全表的10-20%,优化器不会走索引,而变成全表扫描
- 联合索引中,第一个索引列使用范围查询,只能使用到部分索引。
- 联合索引中,第一个查询条不是最左前缀列。
- 模糊查询条件列最左以通配符%开始(可以放到子查询里面)
- 两个单列索引,一个用于检索,一个用于排序,这种情况下只能使用到一个索引。因为查询语句中只能使用一个索引,考虑建立联合索引。
- 查询字段上面有索引,但使用了函数运算
覆盖索引
覆盖索引:就是包含了所有查询字段(where,select,ordery by,group by包含的字段)的索引,执行计划中,Extra=Using idex

覆盖索引的好处:
- 避免 Innodb 表进行索引的二次查询
Innodb是以聚集索引的顺序来存储的,二级索引在叶子节点中保存有行的主键信息,如果用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了IO操作,提升了查询效率。
- 可以把随机 IO 变成顺序 IO 加快查询效率
由于覆盖索引是按键值的顺序存储的,对比随机从磁盘读取每一行的数据IO要少,因此利用覆盖索引,可以把磁盘的随机读取IO转变成索引查找的顺序IO。
索引的选取规则
1、复合索引:选择索引列的顺序
- 尽量把字段长度小的列放在联合索引的最左侧(因为字段长度越小,一页能存储的数据量越大,IO性能也就越好)
- 区分度最高的放在联合索引的最左侧(区分度=列中不同值的数量/列的总行数)
- 使用最频繁的列放到联合索引的左侧(这样可以比较少的建立一些索引)
2、表关联查询
- 类型和大小要相同,可以使用索引。 VARCHAR(10)和 CHAR(10)大小相同,但 VARCHAR(10)与 CHAR(15)不相同。
- 字符串列之间比较,两列应使用相同的字符集。例如,将utf8列与 latin1列进行比较会不使用索引。
- 将字符串列与时间或数字列进行比较时,在没有转换情况下,不使用索引。
3、常见的索引列建议
- WHERE 字段
- ORDER BY、GROUP BY、DISTINCT 中的字段 不要将符合1和2中字段的列都建立一个索引,通常将1、2中的字段建立联合索引效果更好
- 多表join的关联列
4、通过索引扫描的行记录数超过全表的10%~30%左右,优化器不会走索引,而变成全表扫描
5、避免使用双%号的查询条件。 (如果无前置%,只有后置%,是可以用到列上的索引的)
覆盖索引、前缀索引、索引下推,在满足语句需求的情况下,尽量少地访问资源是数据库设计的重要原则之一。我们在使用数据库的时候,尤其是在设计表结构时,也要以减少资源消耗为目标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号