
表格拼接,融合
cbind(df1,df2) 横向添加表格,表格变宽,增加列数
rbind(df1,df2,...) 纵向合并多个数据集,表格变长,增加行数, 类似cat命令,要求列数相同
例子:
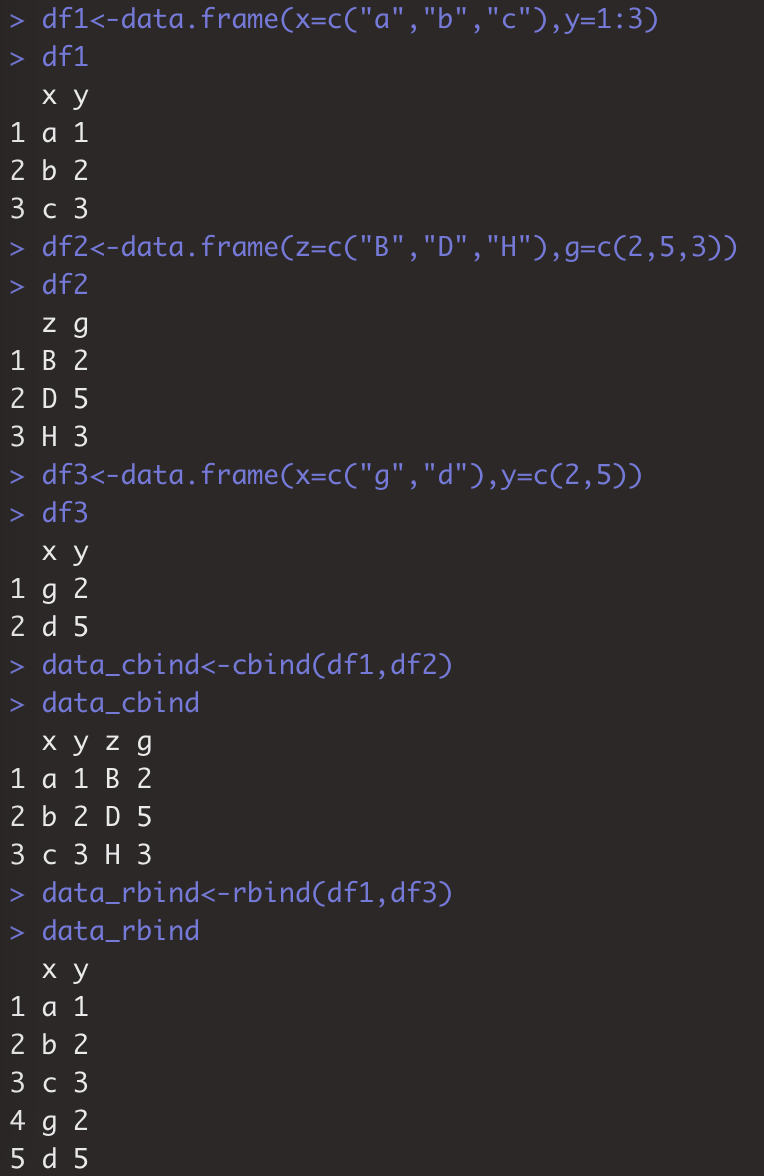
表格融合:针对数据框没有很好的保持一致。可用函数R内置的merge() 和dplyr的_join()函数。注:merge()可指定匹配列名,但运行较慢。
merge(数据框1,数据框2,all= ,[by=,by.x=,by.y= ])
注:merge()函数会自动寻找两个数据框的共有列,即by=共有列,也可以指定不同名的列即by.x指定左边数据框的依据列,by.y指定右边数据框的依据列。
all=FALSE时,只将数据框中共有列数值相同的那些行输出,类似两个数据框对共有列取交集。;all=TRUE时取并集,原本在该行没有得数据框值用NA替代。
例子:
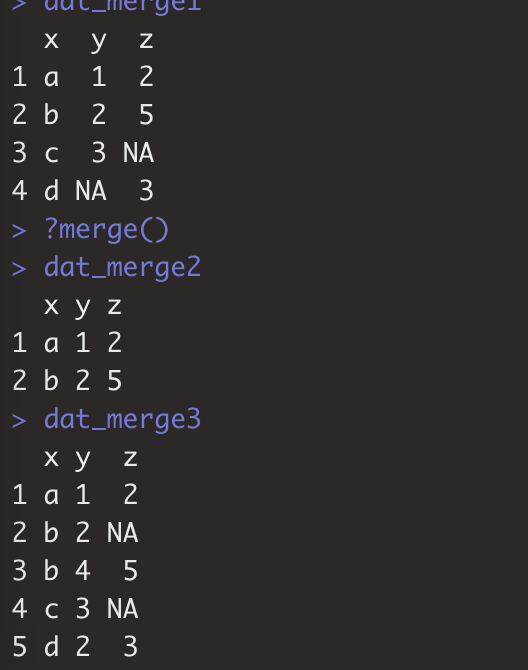
dat_merge1<-merge(df1,df2,by="x",all=TRUE)
dat_merge2<-merge(df1,df3,by.x="x",by.y="g")
dat_merge3<-merge(df1,df4,by=c("x","y"),all=TRUE)

结果:
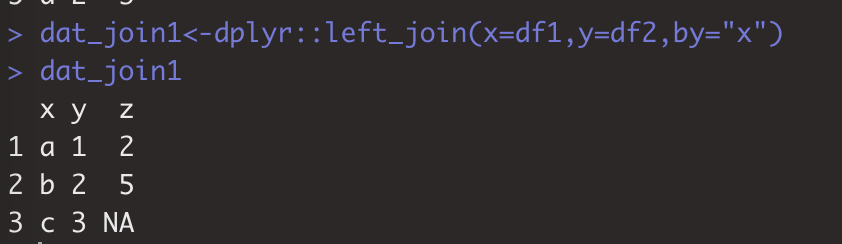
dplyr包提供left_join(),right_join(), inner_join(), full_join()四个函数。
dplyr::full_join()生成两个集合的并集,
dplyr::inner_join()保留交集key
dplyr::left_join() 只保留左数据框所有key
dplyr::right_join()只保留右边数据框所有key
注:空值填充NA。
by=c("x"="g"),指定两个数据框对应匹配列。
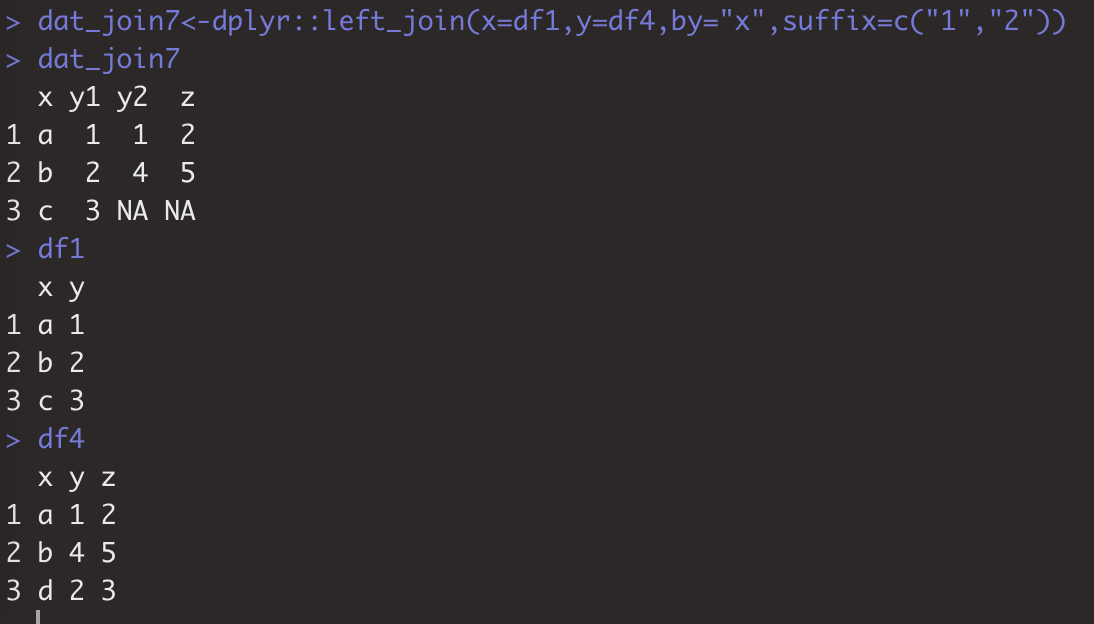
在合并过程有列在两个表中同名,但不作为匹配列,值不同,想保留这两列时候,用suffix参数给重复列名加后缀。
例子:
dat_join1<-dplyr::left_join(x=df1,y=df2,by="x")
dat_join2<-dplyr::right_join(x=df1,y=df2,by="x")
dat_join3<-dplyr::inner_join(x=df1,y=df2,by="x")
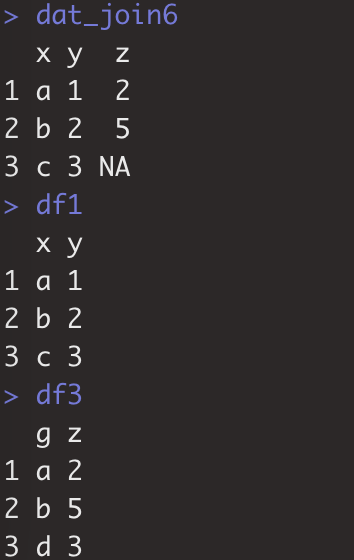
dat_join4<-dplyr::full_join(x=df1,y=df2,by="x")
dat_join4<-dplyr::full_join(x=df1,y=df2,by="x")
dat_join7<-dplyr::left_join(x=df1,y=df4,by="x",suffix=c("1","2"))

我用到的场景:
因为样本名重复,所以新入库样本在下检测时需要结合CNGB样本编号和样本名称,以及板号(96孔板整4板下单)
那么需要整合入库单编号和样本信息单:
library(tidyverse)
dplyr::inner_join()
rukudansan<-read.csv("~/Downloads/rukudanbianma.csv",header = TRUE,skip = 1)
rukudansan["客户样本名称"]
View(rukudansan)
rukudansan$客户样本名称
rukuxinxibiao<-read.csv("~/Downloads/yangbenxinxindan.csv",header = TRUE)
View(rukuxinxibiao)
rukuxinxibiao$客户样本名称
data_inner<-dplyr::inner_join(x=rukudansan,y=rukuxinxibiao,by="客户样本名称")
View(data_inner)
write_excel_csv(data_inner,"~/data_inner_excelcsv.csv")
history()
savehistory("~/Downloads/Untitled.Rhistory")
本文来自博客园,作者:BioinformaticsMaster,转载请注明原文链接:https://www.cnblogs.com/koujiaodahan/p/15359330.html
posted on 2021-10-01 14:14 BioinformaticsMaster 阅读(217) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号