
ClickHouse基础
ClickHouse的介绍这里不做描述,网上很多,可以参考书籍《ClickHouse原理解析与应用实践》
1)使用client链接server:clickhouse-client
clickhouser -- help 查看命令帮助
客户端常用参数
-- host ,-h 说明:服务端的host名称,默认是localhost
-- port 说明:连接的端口号,默认值是9000
--user,-u 说明:用户名。默认值:default
--password 说明: 密码,默认值:空字符串
--query,-q 说明:非交互模式下的查询语句
如:clickhouse-client -q 'show databases;'

--database,-d 说明:默认当前操作的数据库。默认值:default
--multiline,-m 说明:允许多行语句查询
--format,-f 说明:使用指定的默认格式输出结果
--time,-t 说明:飞交互模式下会打印查询执行的时间到窗口
--stacktrace 说明:如果出现异常,会打印堆栈跟踪信息
--config-file 说明:配置文件的名称
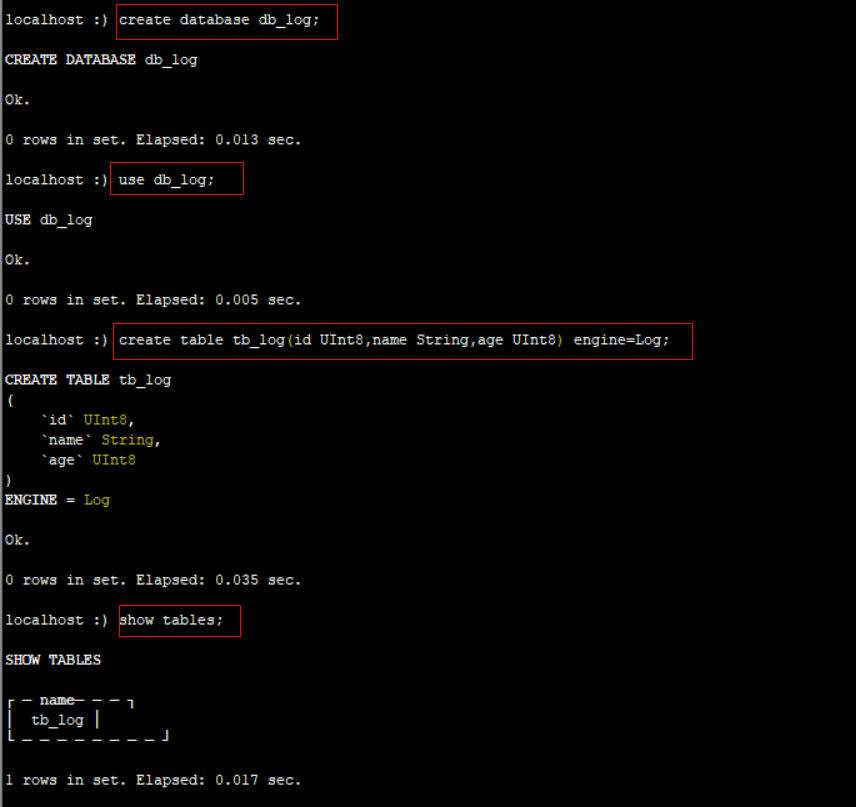
2) 常用的sql语法
-- 列出数据库列表 show databases;
-- 查看当前使用的数据库
select currentDatabase();
-- 列出数据库中表列表 show tables; -- 创建数据库 create database test; -- 删除一个表 drop table if exists test.t1; -- 创建第一个表 create table if not exists test.t1 ( id UInt16 ,name String ) ENGINE = Memory ; -- 插入测试数据 insert into test.t1 (id, name) values (1, 'zhangsan'), (2, 'lishi'); -- 查询 select * from test.t1;
3)数据类型
参考文档:https://clickhouse.tech/docs/en/sql-reference/data-types/
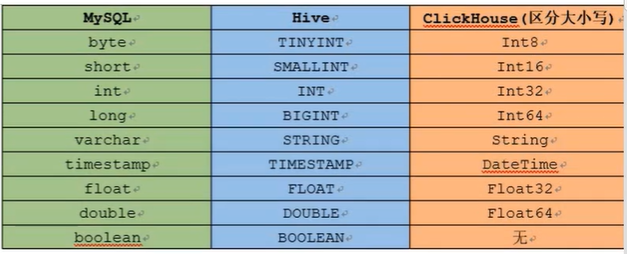
数据类型对应关系:
clickhouse string类型为单引号
复杂数据类型:
枚举:Enum
数组:Array
元组:Tuple
4)ClickHouse 引擎
① TinyLog:最简单的表的引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾
该引擎没有并发控制,如果同时从表中读取和写入数据,则读取操作将抛出异常;如果同时写入多个查询的表中,则数据将被破坏。
不支持索引。
这种表引擎的典型用法是write-once:首先只写入一次数据,然后根据需要多次读取。此引擎适用于相对较小的表(最多1,000,000行)。
如果有许多小表,则使用此表引擎是合适的,因为它需要打开的文件更少。当拥有大量的小表时,可能会掉在性能低下。
总结:存储在磁盘中,每列存储为一个文件,不支持索引,不支持并发。
小表适用,比如国家表,省份表。
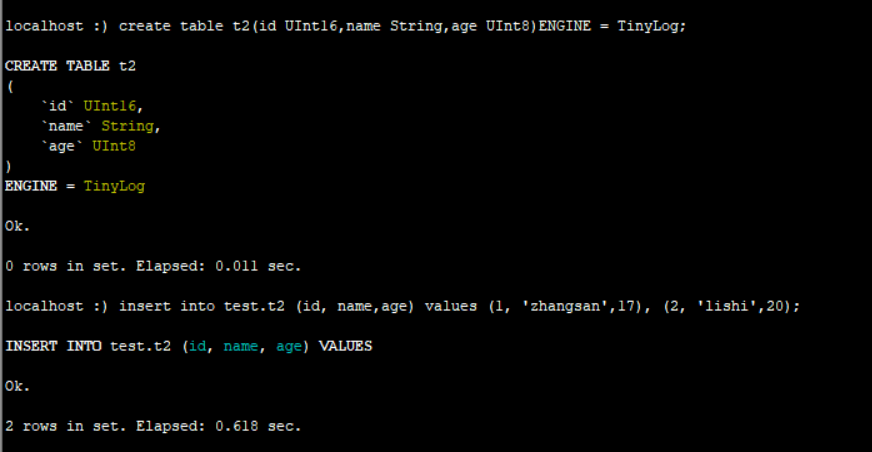
创建该引擎表: create table t2(id UInt16,name String,age UInt8)ENGINE = TinyLog;
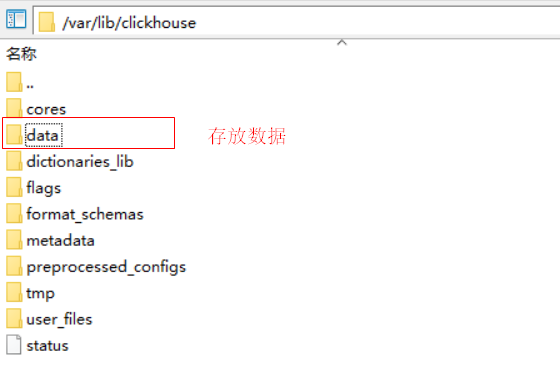
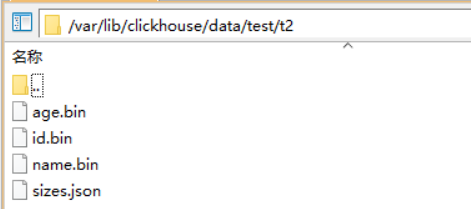
在/var/lib/clickhouse/data可以看到,上面写入t2表中的数据文件
每个字段数据写入一个bin文件中
②Log(数据分块记录偏移量)
![]()
日志与TinLog的不同之处在于,标记的小文件与列文件存在一起,这些标记写在每个数据快上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数,这使得可以在多个线程读取表数据。对于并发数据访问,可以同时执行读取操作,而写入则阻塞读取和其他写入。Log引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。
Log引擎适用于临时数据,write-once表以及测试或者演示目的。
建表
create table tb_log(id UInt8,name String,age UInt8) engine=Log;
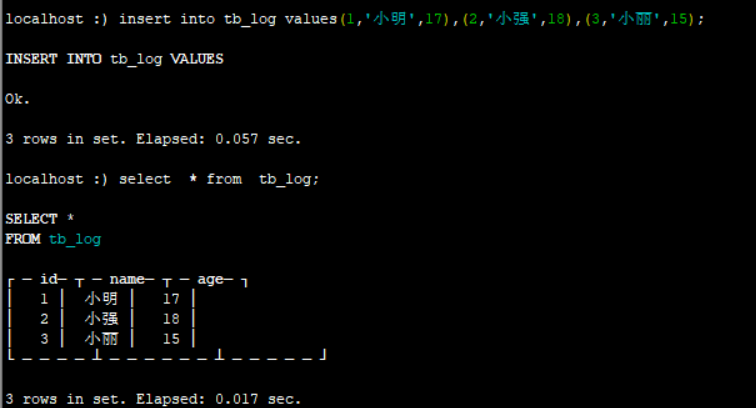
插入数据:
insert into tb_log values(1,'小明',17),(2,'小强',18),(3,'小丽',15)
cd /var/lib/clickhouse/data/db_log/tb_log下,可以看到每个字段都有一个bin文件,同时还有一个标记文件_marks.mrk

总结Log引擎:
数据存储在本地的默认位置
数据以列为文件存储
插入数据的时候是在文件后面追加数据
数据以xxx.bin文件按字段进行存储
size.json记录每个文件的大小
不支持索引
读写分离
③ Memory:内存引擎,数据以未压缩的原始形式直接保存在内存当中,服务器重启数据就会效性,读写操作不会相互阻塞,不支持索引。简单查询
下有非常非常高的性能(超过10G/s).
一般用到它的地方不多,除了用来测试,就是需要非常高的性能,同时数据量不太大(上限大概1亿行)的场景
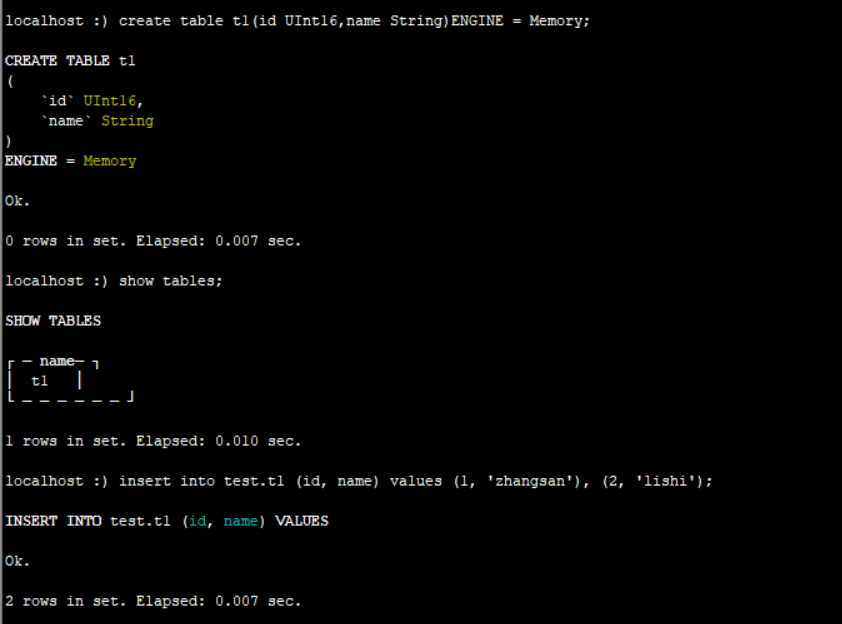
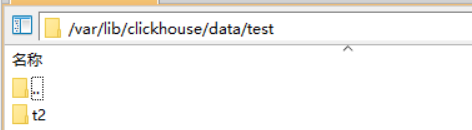
引擎为Memory的数据保存到内存中,不会写入磁盘,可以看到在/var/lib/clickhouse/data/test下面只有t2表
④ Merge:Merge引擎(不要跟MergeTree混淆)本身不存储数据,但可以用于同时从任意多个其他的表中读取数据。读是自动并行的,不支持写入。
读取时,那些真正读取到数据的表的索引(如果有的话)会被使用。
Merge引擎的参数:一个数据库名和一个用于匹配表名的正则表达式.
例如:
create database db_merge;
use db_merge;
create table t1(id UInt16,name String) ENGINE=TinyLog;
create table t2(id UInt16,name String) ENGINE=TinyLog;
create table t3(id UInt16,name String) ENGINE=TinyLog;
insert into t1(id,name) values(1,'张三');
insert into t2(id,name) values(2,'李四');
insert into t3(id,name) values(3,'王五');
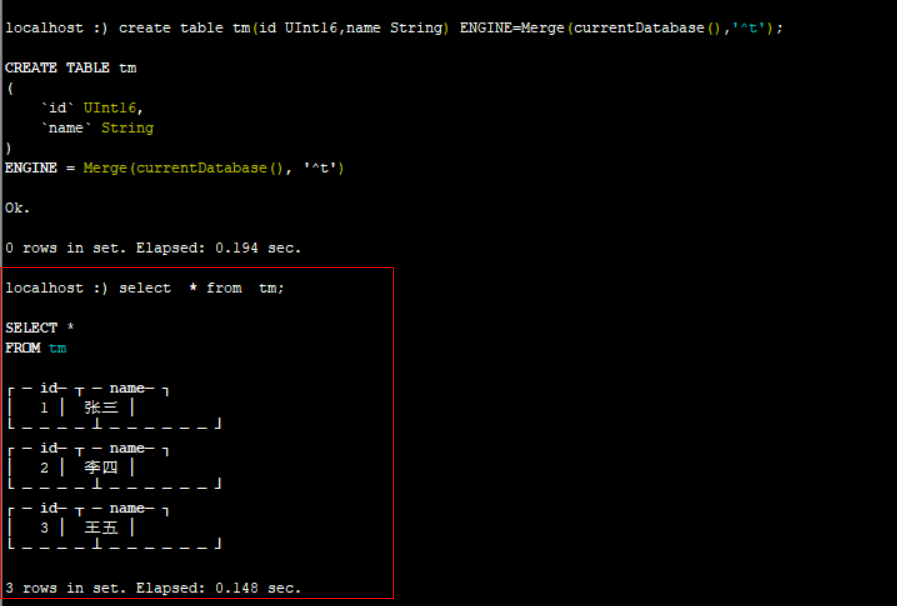
create table tm(id UInt16,name String) ENGINE=Merge(currentDatabase(),'^t');
select * from tm; //会查询出t1,t2,t3 三张表的数据
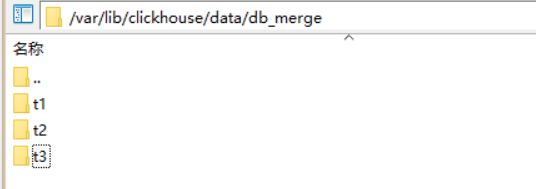
可以看到/var/lib/clickhose/data/db_merge下面只有t1,t2,t3三个表,tm是不在这里的。
⑤MergeTree<重点>
ClickHouse中最强大的表引擎当属MergeTree(合并数)引擎以及该系列(*MergeTree)中的其他引擎MergeTree引擎系列的基本理念如下,当你有巨量数据要插入表中,你要高效的一批一批写入数据片段,并希望这些数据片段在后台按照一定规则合并,相比在插入时不断修改(重写)数据进存储,这种策略会高效很多。
他的特点如下:
①数据按主键排序
②可以使用分区(如果指定了主键),一般按照月进行分区
③支持数据副本
④支持数据采样
格式:ENGINE=MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value,....]
PARTITION BY :分区键,要按照月分区,可以使用toYYYYMM(data_colum),要求表中有日期字段
ORDER BY :表的排序键,可以是一组列的元组或者任意表达式,例如 ORDER BY (id,name)
PRIMARY KEY:主键,需要与排序键字段不同,默认情况下主键跟排序键相同
SAMPLE BY:用于抽样的表达式,如果要用于抽样表达式,主键中必须包含这个表达式
SETTINGS:影响MergeTree性能的额外参数
(1)、index_granularity:索引粒度。即索引中相邻【标记】间的数据行数。默认值是8192
(2)、use minimalistic_part_header_in_zookeeper:数据片段在zookeeper中的存储方式。
(3)、min_merge_bytes_to_use_direct_io:使用直接I/O来操作磁盘的合并操作是要求的最小数据量
未完,待续....

 浙公网安备 33010602011771号
浙公网安备 33010602011771号