


linux 各含义解释(收集)
名词: 中断 上下文切换
中断
中断,会导致正在运行的CPU要停下手头的工作去响应,这需要工作任务的切换,就带来了我们熟知的上下文切换,而频繁上下文切换,是对系统性能的重要影响因素。
那怎么减少中断带来的影响呢?
现在CPU往往是多核,如16、32核,是否可以把中断绑定到其中一个CPU上,再把其他剩余的cpu用于应用的计算。因为之前是单核的原因,传统 的很多做法是会把中断扔给cpu0处理,在linux下,可执行mpstat -P ALL 1,查看各个cpu上的中断情况。

这虚拟机可以看到cpu2上的中断明显偏多,每秒有6k次,这样会对性能产生什么样的影响呢?再看上下文切换的情况
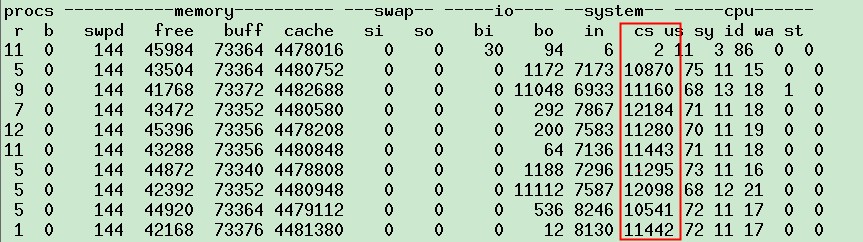
此时上下文切换大于1w次,再看top里面cpu对软中断与硬中断的处理情况

对应的也可发现,CPU2上处里更多的中断,hi与si。如果此时我们的应用跑在CPU2上,结果可想而知就是每秒约6k次的上下文切换。既然如此那我就设置下应用使用的CPU,让java进程不在CPU2上跑,会有什么效果呢?

立马可以看到,cpu2上的us变的很低了,java进程在其他的cpu上运行了,但cpu2上继续响应hi与si,再看上下文切换情况
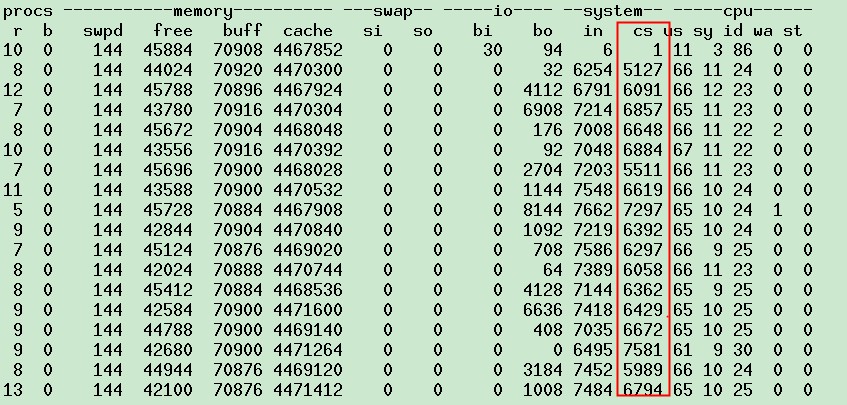
可以看到,现在上下文切换,明显比之前的少了5~6k,基本上就是之前在cpu2上的中断次数,稍做改动,就把上下文切换减少了很多
那整体的cpu利用率情况呢:
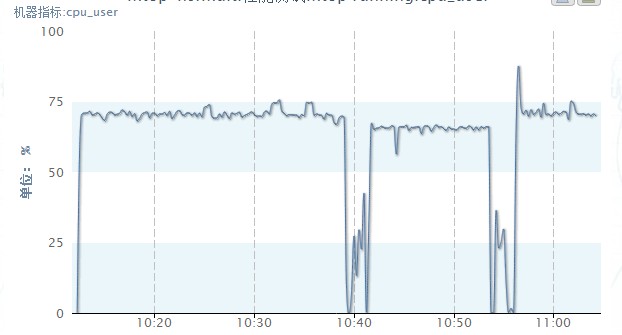
如上图中间这段的数据,是设置了java进程运行在CPU0、1、3、4上的,前后两段是全部CPU跑的,大概us比不设置降低了5%,us降低了点,性能上当然可以提升点了。
当其中一个CPU的hi和si明显比其他的高,而且系统的吞吐能力上不去,很可能是中断处理不均衡的问题,当中断的数量一个CPU够处理的时候,利 用亲缘绑定CPU,减少中断引起的上下文切换,但当一个CPU中断处理不够时候,就用多个CPU处理,或者所有CPU平均分摊,但所有的CPU分摊,上下 文切换的次数不会减少。所以真正如何处理这个中断,还是看系统与应用的实际情况。
网卡的中断
网卡接收数据后会产生中断,让CPU来处理,一个CPU没话说,只有它干活,多核时代怎么搞呢,很多老的设备还是绑定一个CPU上。为了能充分利用 多核,Google的牛人搞了个RPS、RFS的patch,能够将网卡中断分散到多个CPU,主要就是hash到固定的CPU上,具体可google查 看。
但是,这明显是我等屌丝的玩法,现在高富帅的玩法是,高级的网卡是支持多队列的,找新机器cat /proc/interrupts |grep eth0,可以看到eth0-TxRx-0 ~~eth0-TxRx-7,同时每个队列的中断对应一个CPU,这样就把中断响应分摊了。
但现在cpu32核,还是显得不够平均,所以这时候还可以使用RFS,看看效果,当然RFS需要linux 2.6.35以上支持,所以那些2.6.18内核的机器,快点退休吧。
T4的机器目前虚拟机对cpu的分配,是用cgroup跨core绑定的,也就是会跨物理cpu组成一个虚拟机,这会带来cache miss的问题,至于为什么不选择一个虚拟机尽量在一个core上,大师的答复是主要是为充分利用资源,我们的应用,还没有到cache miss影响更大,还是充分利用cpu运算能力先。
那会不会我们应用虚拟机分配到的CPU,刚好全是网卡队列对应绑定的那些呢?那不吃亏死了。。。。。。
参考资料:
1、中断与性能
3、
上下文切换
上下文切换的精确定义可以参考: http://www.linfo.org/context_switch.html。多任务系统往往需要同时执行多道作业。作业数往往大于机器的CPU 数,然而一颗CPU同时只能执行一项任务,为了让用户感觉这些任务正在同时进行,操作系统的设计者巧妙地利用了时间片轮转的方式,CPU给每个任务都服务 一定的时间,然后把当前任务的状态保存下来,在加载下一任务的状态后,继续服务下一任务。任务的状态保存及再加载,这段过程就叫做上下文切换。时间片轮转 的方式使多个任务在同一颗CPU上执行变成了可能,但同时也带来了保存现场和加载现场的直接消耗。(Note. 更精确地说, 上下文切换会带来直接和间接两种因素影响程序性能的消耗. 直接消耗包括: CPU寄存器需要保存和加载, 系统调度器的代码需要执行, TLB实例需要重新加载, CPU 的pipeline需要刷掉; 间接消耗指的是多核的cache之间得共享数据, 间接消耗对于程序的影响要看线程工作区操作数据的大小).
多数人认为使用多线程一定会比单线程执行速度快,但其实未必,因为多线程应用程序会带来额外的开销和竞争问题,他们都可能会拖慢系统的执行速度。这些因素包括:对IO设备的竞争,对锁的竞争,以及CPU对线程执行上下文的频繁切换等。
- 时间片用完,CPU正常调度下一个任务
- 被其他优先级更高的任务抢占
- 执行任务碰到IO阻塞,调度器挂起当前任务,切换执行下一个任务
- 用户代码主动挂起当前任务让出CPU时间
- 多任务抢占资源,由于没有抢到被挂起
- 硬件中断
在上下文切换过程中,CPU会停止处理当前运行的程序,并保存当前程序运行的具体位置以便之后继续运行。从这个角度来看,上下文切换有点像我们同时 阅读几本书,在来回切换书本的同时我们需要记住每本书当前读到的页码。在程序中,上下文切换过程中的“页码”信息是保存在进程控制块(PCB)中的。 PCB还经常被称作“切换桢”(switchframe)。“页码”信息会一直保存到CPU的内存中,直到他们被再次使用。
在三种情况下可能会发生上下文切换:中断处理,多任务处理,用户态切换。在中断处理中,其他程序”打断”了当前正在运行的程序。当CPU接收到中断 请求时,会在正在运行的程序和发起中断请求的程序之间进行一次上下文切换。在多任务处理中,CPU会在不同程序之间来回切换,每个程序都有相应的处理时间 片,CPU在两个时间片的间隔中进行上下文切换。对于一些操作系统,当进行用户态切换时也会进行一次上下文切换,虽然这不是必须的。
参考资料:
3、什么是上下文切换
- 设计更复杂
多线程程序在访问共享数据的时候往往需要我们很小心的处理,否则就会出现难以发现的BUG,一般地,多线程程序往往比单线程程序设计会更加复杂(尽管有些单线程处理程序可能比多线程程序要复杂),而且错误很难重现(因为线程调度的无序性,某些bug的出现依赖于某种特定的线程执行时序)。
- 上下文切换的开销
线程是由CPU进行调度的,CPU的一个时间片内只执行一个线程上下文内的线程,当CPU由执行线程A切换到执行线程B的过程中会发生一些列的操作,这些操作主要有”保存线程A的执行现场“然后”载入线程B的执行现场”,这个过程称之为“上下文切换(context switch)”,这个上下文切换过程并不廉价,如果没有必要,应该尽量减少上下文切换的发生。
- 增加更多的资源消耗
除了CPU执行上下文切换的消耗以外,线程的执行还将有其他一些资源的消耗,比如:内存同步的开销(线程需要一些内存在维持线程本地栈,每个线程都有本地独立的栈用以存储线程专用数据),上下文切换的开销(前面已经讲过),线程创建和消亡的开销,以及调度的开销(占用操作系统的一些资源来管理和协调线程),我们可以创建100个线程让他们什么都不做,看看他们消耗了多少内存。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号