


多线程下写全局变量时,可借助sleep(0)让出cpu&&比较自旋锁与mutex
近期在重读APUE,对unix下多线程有了新的理解
用一个小demo来说明多线程下写全局变量时,让出cpu(使线程挂起)的重要性
一个demo(对全局变量++)-->反汇编阅读cpu指令
下面这个demo对g_cnt这个全局变量进行++操作
int g_cnt = 1;
int main()
{
g_cnt++;
return 0;
}
执行gcc -S main.c可以查看其反汇编,挑几行关键的看看:
movl g_cnt(%rip), %eax
addl $1, %eax
movl %eax, g_cnt(%rip)
分析一下,上面有3个步骤:
[1]load,将g_cnt的值写入寄存器eax
[2]对寄存器eax进行+1操作
[3]写回,将eax寄存器的值写回g_cnt
多个线程都去对全局变量++
线程不挂起
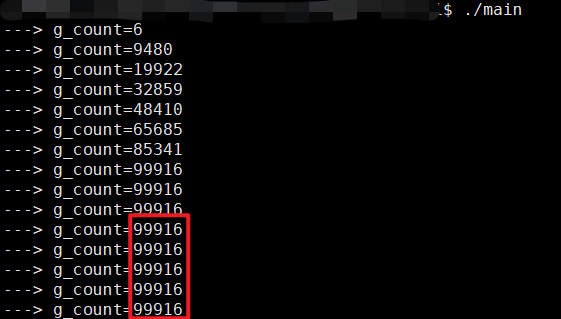
先看这个demo,共创建了10个线程,每个线程对g_count进行++,共10W次,期望g_count最终值为10W,
注意下面的sleep(0)在每个线程的回调函数中被注释掉了
#define THREAD_NUM 10
int g_count = 0;
void *func(void *arg)
{
int *cnt = (int *)arg;
// 每个线程加 1W 次
for (int i = 0; i < 10000; i++) {
(*cnt)++;
// sleep(0); // 使线程挂起(导致切换),让出cpu
}
}
int main()
{
int i;
pthread_t threadId[THREAD_NUM];
for (i = 0; i < THREAD_NUM; i++) {
pthread_create(&threadId[i], NULL, func, (void *)&g_count);
}
for (i = 0; i < 15; i++) {
printf("---> g_count=%d\n", g_count);
sleep(1);
}
return 0;
}
看看效果,g_count最终只被加到6W多(每次执行结果都不一样,但是都距离10w差距很远),往下再看一节再分析原因

sleep(0)使线程挂起,让出cpu
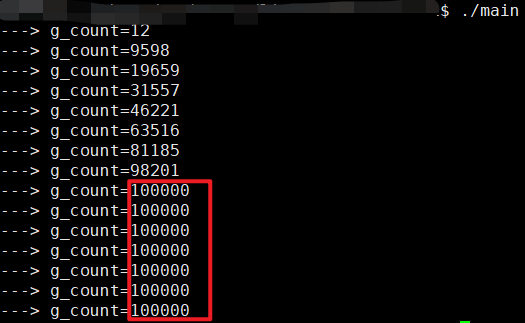
还是这个demo,但是把sleep(0)放开注释
#define THREAD_NUM 10
int g_count = 0;
void *func(void *arg)
{
int *cnt = (int *)arg;
// 每个线程加 1W 次
for (int i = 0; i < 10000; i++) {
(*cnt)++;
sleep(0); // 使线程挂起(导致切换),让出cpu
}
}
int main()
{
int i;
pthread_t threadId[THREAD_NUM];
for (i = 0; i < THREAD_NUM; i++) {
pthread_create(&threadId[i], NULL, func, (void *)&g_count);
}
for (i = 0; i < 15; i++) {
printf("---> g_count=%d\n", g_count);
sleep(1);
}
return 0;
}
看看效果,有了sleep(0)已经很接近10w了
总结一下
在线程不挂起小节中,10个线程可能只有部分线程抢到了cpu,导致其他线程根本没机会被调度
后续增加了sleep(0)强行让线程挂起,让出cpu,每个线程都得到了机会被调度,进而对全局变量++
为啥不到10W?
回忆以下前面的反汇编看到的指令:
movl g_cnt(%rip), %eax
addl $1, %eax
movl %eax, g_cnt(%rip)
共3条指令,但是他们不具备原子性,不能保证每个线程都是乖乖的执行完这3条,再让其他线程再去执行,看看下图:
- 理想情况
![image]()
- 其他情况
这里的eax寄存器我的理解是多核(多线程)不是共享的,假设g_cnt初始化为0;线程1loadg_cnt到线程1的eax寄存器中,此时线程2loadg_cnt到线程2的eax寄存器中,执行++后,进行写回,g_cnt值加到1,;此时线程1又对线程1的eax寄存器的值进行++,再写回到g_cnt还是1;两个线程都做了++操作,但是值只增加了1。
这样g_cnt可能被++的次数就变少了,因此没有达到10W,解决的方法很容易想到:加锁
![image]()


加锁版本
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#define THREAD_NUM 10
int g_count = 0;
pthread_mutex_t mutex;
void *func(void *arg)
{
int *cnt = (int *)arg;
// 每个线程加 1W 次
for (int i = 0; i < 10000; i++) {
pthread_mutex_lock(&mutex);
(*cnt)++;
pthread_mutex_unlock(&mutex);
sleep(0);// 使线程挂起(导致切换),让出cpu
}
}
int main()
{
int i;
pthread_t threadId[THREAD_NUM];
pthread_mutex_init(&mutex, NULL);
for (i = 0; i < THREAD_NUM; i++) {
pthread_create(&threadId[i], NULL, func, (void *)&g_count);
}
for (i = 0; i < 15; i++) {
printf("---> g_count=%d\n", g_count);
sleep(1);
}
return 0;
}
这样就可以加到10w了~
自旋锁替换互斥量
自旋锁和互斥量的接口类似,很好替换,直接看代码:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
#define THREAD_NUM 10
int g_count = 0;
pthread_mutex_t mutex; // 互斥锁
pthread_spinlock_t spinlock; // 自旋锁
void *func(void *arg)
{
int *cnt = (int *)arg;
// 每个线程加 1W 次
for (int i = 0; i < 10000; i++) {
// pthread_mutex_lock(&mutex);
pthread_spin_lock(&spinlock);
(*cnt)++;
// pthread_mutex_unlock(&mutex);
pthread_spin_unlock(&spinlock);
sleep(0);// 使线程挂起(导致切换),让出cpu
}
}
int main()
{
int i;
pthread_t threadId[THREAD_NUM];
pthread_mutex_init(&mutex, NULL);
// PTHREAD_PROCESS_PRIVATE : 只能被初始化该锁的进程内部的线程所访问
// PTHREAD_PROCESS_SHARED : 自旋锁能被可以访问锁底层内存的线程所获取
pthread_spin_init(&spinlock, PTHREAD_PROCESS_SHARED);
for (i = 0; i < THREAD_NUM; i++) {
pthread_create(&threadId[i], NULL, func, (void *)&g_count);
}
// for (i = 0; i < THREAD_NUM; i++) {
// pthread_join(threadId[i], NULL);
// }
for (i = 0; i < 10; i++) {
printf("---> g_count=%d\n", g_count);
sleep(1);
}
return 0;
}
自旋锁与互斥量的区别
spinlock不会使线程状态发生切换,mutex在获取不到锁的时候会选择sleep
mutex获取锁分为两阶段,第一阶段在用户态采用spinlock锁总线的方式获取一次锁,如果成功立即返回;否则进入第二阶段,调用系统的futex锁去sleep,当锁可用后被唤醒,继续竞争锁。
Spinlock优点:没有昂贵的系统调用,一直处于用户态,执行速度快
Spinlock缺点:一直占用cpu,而且在执行过程中还会锁bus总线,锁总线时其他处理器不能使用总线
Mutex优点:不会忙等,得不到锁会sleep
Mutex缺点:sleep时会陷入到内核态,需要昂贵的系统调用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号