计算机系统结构学习笔记 一 指令并行级技术
指令级并行概念
-
相关术语:
基本块--仅包含顺序型指令、中途无转入点的代码
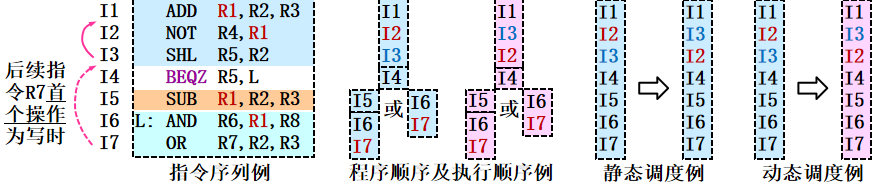
程序顺序--源程序约定的指令执行顺序(串行执行方式)
执行顺序--源程序实际的指令执行顺序
静态调度--编译器在编译时重排列指令序列(结果同源程序顺序
动态调度--硬件在执行时重排列指令序列(结果同目标程序顺序
-
指令级并行(ILP,Instruction Level Parallelism):指令之间的并行性。计算机可以并行执行多条指令。
-
开发途径:时间重叠(指令流水线)、资源重复(多部件/多指令同时)、软件技术(指令重排序)
指令相关性与ILP开发:
- 数据冒险处理(1、2可选)
1)保持相关,避免冒险(流水阻塞/转发/动态调度(基本块内调度))
2)进行代码变换(静态调度),消除冒险(软件) - 控制冒险处理策略(1、2必须)
1)保持数据流:可跨基本块调度(静态(如编译时可多次扫描【软件】/动态(流水预测法)),须不影响执行结果
2)保持异常行为:可改变执行顺序(如预测法),须不产生新的异常。
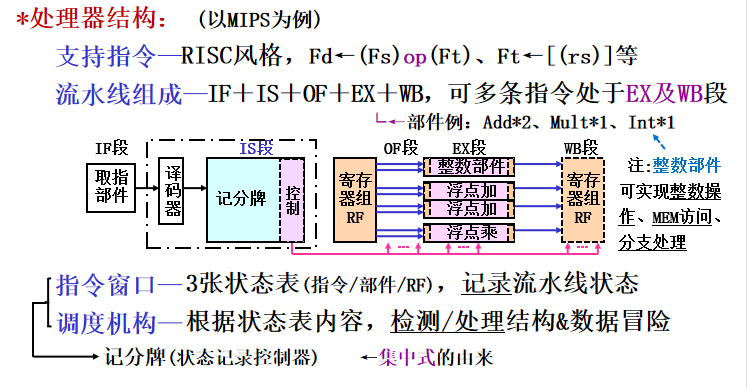
动态调度技术
基本思想(仅处理数据冒险)
回顾:静态调度思想--用译码段处理数据&结果冒险(EX空闲&OPD就绪)(把相关的指令拉开“距离”来减少相关和冲突)
- 在程序执行过程中,依靠专门的硬件对代码进行调度。可以在保持数据流和异常行为的情况下,通过硬件对指令执行顺序进行重安排,减少相关导致的停顿(用硬件的复杂性换指令高效执行)
- 基本思想:(执行时进行指令重排序)
1)用发射段(IS Issue)处理结构冒险,用读操作数段(OF,Operand Fetch)处理数据冒险(等待结束后再读)
2)操作数就绪的指令优先进入执行段

- 我的注释:相当于把指令流出的工作拆分成了两部分:1)检测结构冲突 2)等待数据冲突消失。 没有结构冲突,指令就可以流出。流出后的指令一旦操作数就绪就可以执行,这样是乱序的。
- 实现要求:
1)设置指令窗口保存指令

2)异常可推迟产生(动态调度的处理机这样处理异常行为:对于一条会产生异常的指令来说,只有当处理机确切地将被执行时,才允许它产生异常) - 流水线优化:
1)EX段时延可变时(常多个部件),可以不阻塞后序指令
2)支持多条指令处于EX段 - 不精确异常: 当执行指令i导致发生异常时,处理机现场状态跟严格按程序顺序执行时i的现场不同。
原因:
1)流水线可能已经执行完按程序顺序是位于i后的指令
2)流水线还没执行完i之前的指令
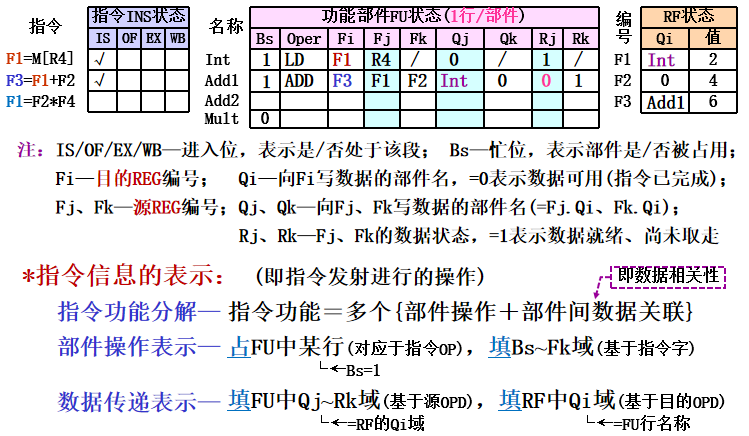
记分牌动态调度算法
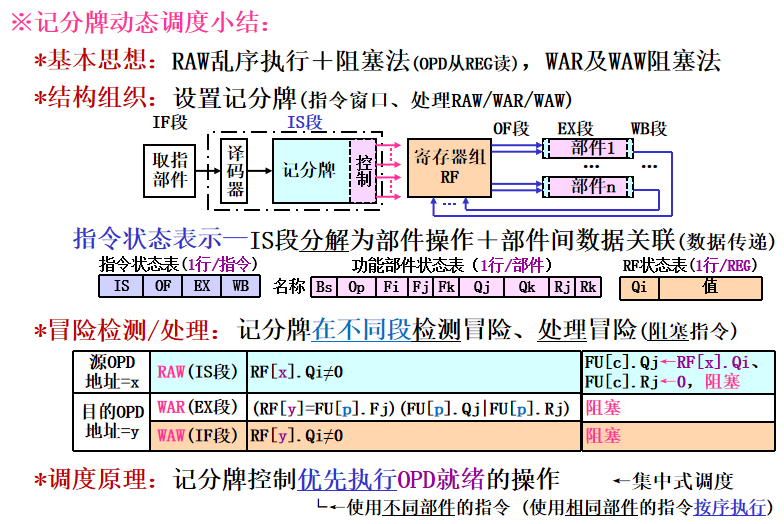
- 基本思想:优先执行OPD就绪的指令,WAR/WAW用阻塞法处理 (在没有结构冲突时,尽可能早地执行完没有数据冲突的指令
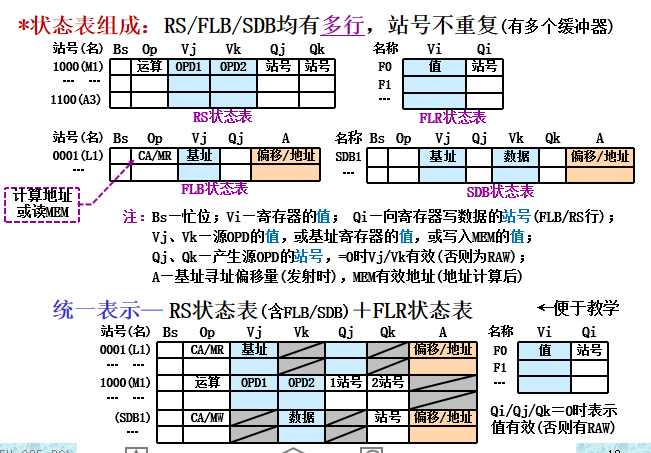
- 状态表组成:指令状态表(流水状态、部件状态表(OP/源OPD部件状态)、RF状态表(目的OPD部件状态)
- 指令流水的组织:
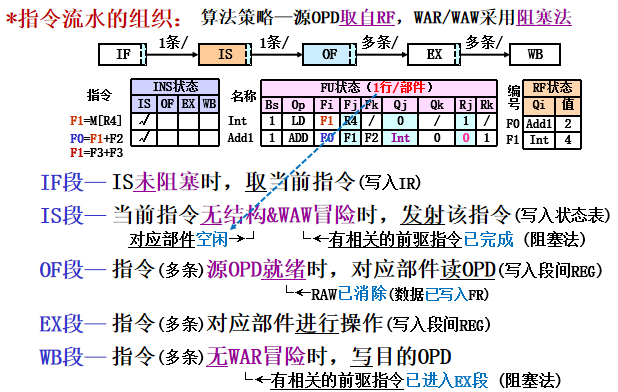
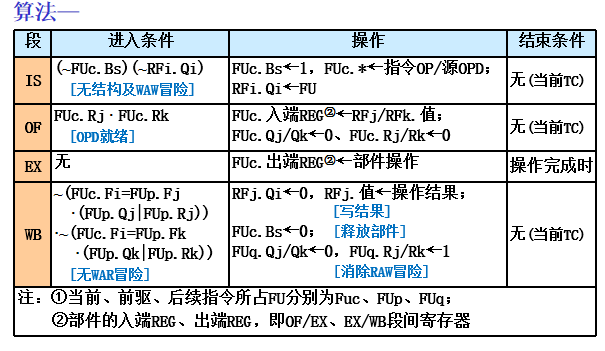
IF:IS段未阻塞,取当前指令写入IR
IS:当前流出指令所需功能部件空闲(结构冒险),并且所有其他正在执行的指令的目的寄存器与该指令不同(WAW冒险),记分牌向该功能部件流出该指令,并修改记分牌内部的记录表
OF:记分牌检测操作数可用性,如数据可用,就通知功能部件从寄存器中读出源操作数并开始执行。这一步动态地解决了RAW冲突!(乱序执行) 如何判断数据可用? 对于给定寄存器,如果前面所有已经流出并且还在执行的指令都不对该寄存器进行写操作,那么该寄存器数据就是可用的。 否则,就要等待写操作完成
EX: 取到操作数后,功能部件执行。产生结果后,就通知记分牌它已经完成执行。 浮点流水线中,这一段可能要占用多个时钟周期
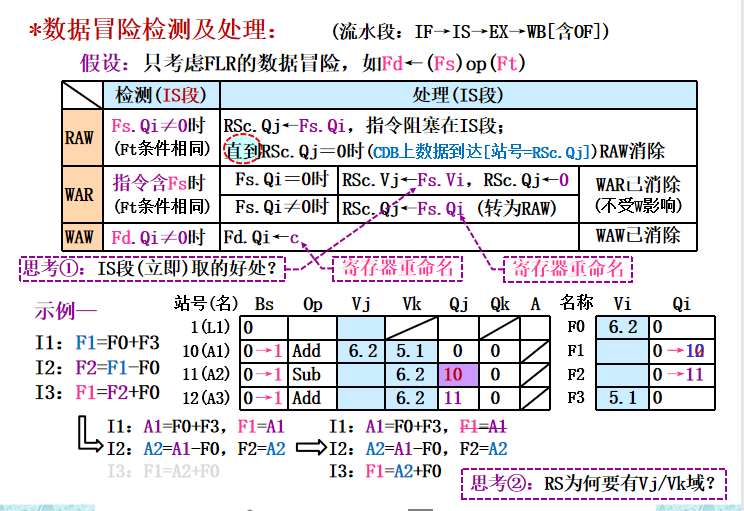
WB: 记分牌一旦知道执行部件完成了执行,就检测是否存在WAR冲突。如不存在,或者原有的WAR冲突(前面某条指令(按顺序流出)还没有读取操作数,而且其某个源操作数寄存器与本指令的目的寄存器相同)已消失,就通知功能部件把结果写到目的寄存器 - 数据冒险检测及处理
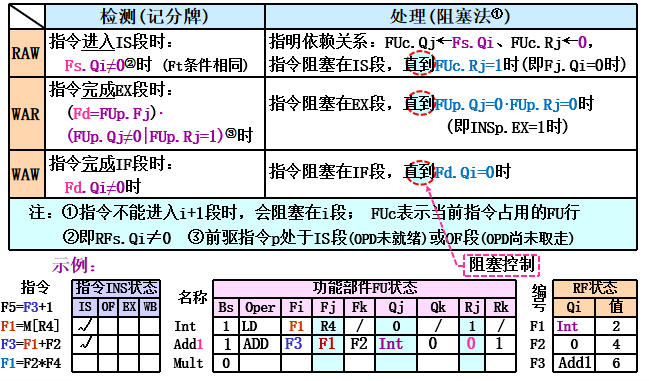
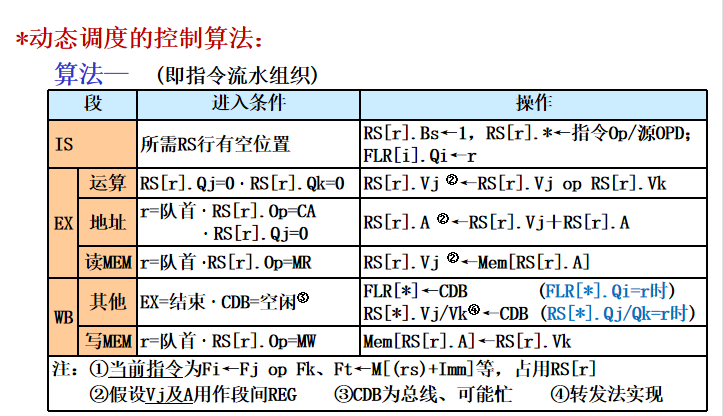
- 动态调度的控制算法
总结:
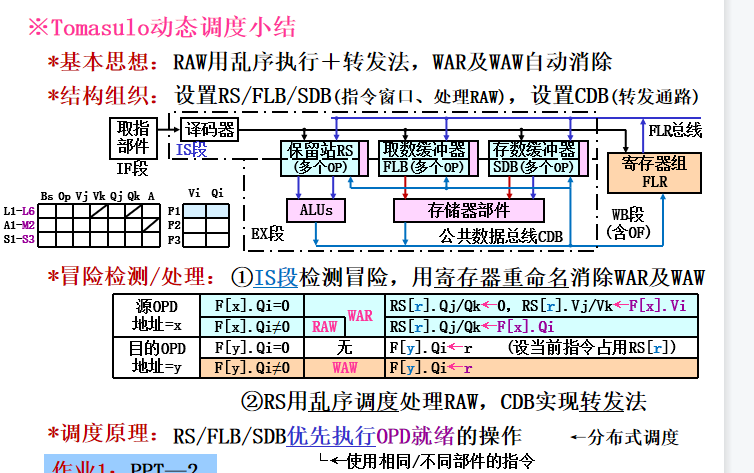
Tomasulo动态调度算法
-
基本思想:(对记分牌的改进)
1)OPD一旦就绪立即执行(通过转发法获取) --对比:记分牌为读寄存器获取(阻塞法)
2)通过寄存器重命名消除WAR及WAW --对比:记分牌阻塞消除
3)采用分布式指令窗口(基于部件->存多条指令/部件)及调度机构 --对比记分牌为集中式,1条指令/部件
分布式:每个功能部件的保留站中的信息决定了什么时候指令可以在该功能部件执行
计算结果通过CDB直接从产生它的保留站传送到所需要它的功能部件而不经过寄存器 -
流水线结构
支持RISC风格
流水线组成: IF+IS+EX+WB(含OF),可多条指令位于EX段
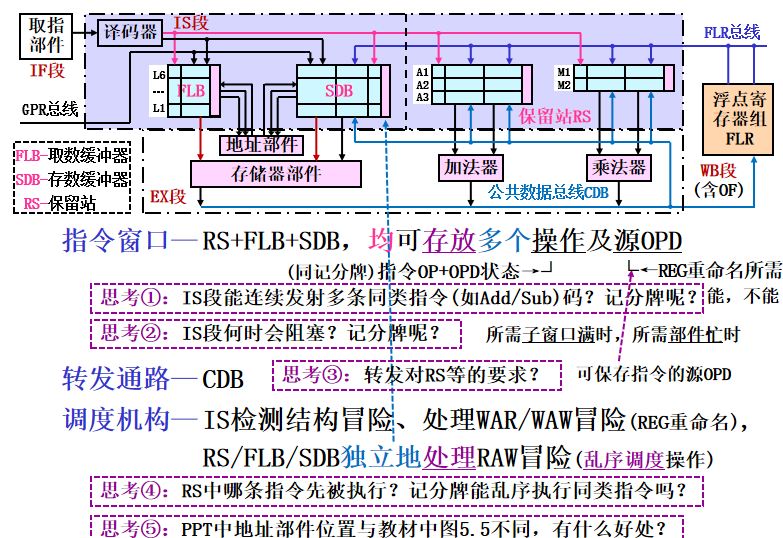
思考4:OPD就绪的指令先被执行 不能
思考5:地址计算有RAW时(如基址寄存器冒险),IS不会被阻塞 -
状态表组成:
-
指令信息表示:
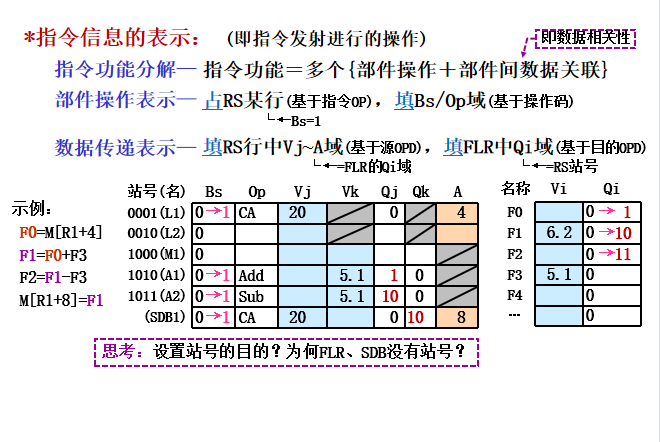
思考: 设置站号表示RAW相关,FLR的RAW通过追溯可描述,SDB的数据不会用作源OPD。 -
指令流水线组织

IS:从指令队列头部取出一条指令,若该指令的操作所要求的操作数在寄存器已经就绪,就把这些操作数送入保留站r。如果还没就绪,就把将要产生该操作数的标识送入保留站r。这样,一旦被记录的保留站完成了计算,它就把数据直接送给保留站r。这一步实际上就进行了寄存器换名的操作(换成保留站的标识)和对操作数进行了缓冲,消除了WAR冲突。
另外要完成对目的寄存器的预约工作,将之设置为接受保留站r的结果。实际上相当于提前完成了写操作(预约)。由于指令按程序顺序流出,当出现多条指令写同一个结果寄存器是,最后留下的预约结果肯定是最后一条指令的,相当于消除了WAW冲突、
若没有空闲的保留站,指令就不能流出,这是发生了结构冲突。
EX:如果某个操作数还没计算出来,本保留站将监视CDB,等待所需的计算结果。一旦那个结果产生,它就被放到CDB上,本保留站将立即获得数据。当两个操作数都就绪本保留站就用相应的功能部件开始执行规定的操作,这里是等到所有操作数都就绪才开始执行指令,用推迟执行的方法解决了RAW。由于结果数据是从其产生的部件(保留站)直接送到需要它的地方,所以这已是最大限度地减少了RAW冲突的影响。
如果出现多个指令同时就绪的情况,需要逐条处理。
WB:功能部件计算完毕后,就将计算结果放到CDB上,所有等待该计算结果的寄存器和保留站(包括store缓冲器)都同时从CDB上获得所需数据。store指令这一步完成存储器写入:当写入的地址和数据都备齐时,将它们送给存储部件,store指令完成。 -
数据冒险及处理
-
算法具体实现
-
总结
动态分支预测技术
- 采用分支预测流水机制: 预测转移方向,并执行该方向指令; 猜对时继续执行后续指令(分支指令不写PC),猜错时回头执行另一方向的指令
- 分支预测任务: 预测转移是否发生,获得分支目标地址
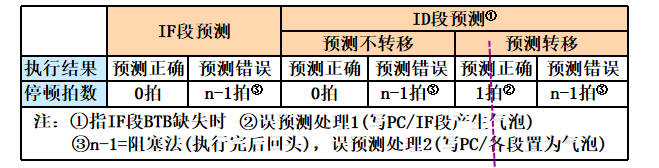
- 分支预测时机:IF段(不停顿)、ID段(停一拍)
- 动态分支预测涉及内容: 分支预测算法、转移历史管理、预测处理流程
分支预测算法
-
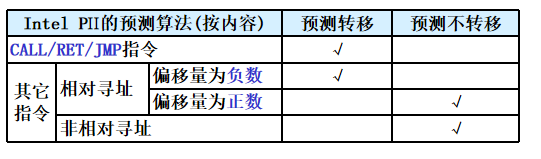
静态预测算法: 定向预测(用于IF段)、按指令内容预测(用于ID段)
-
动态预测算法: 饱和计数预测、相关预测、自适应预测(均IF段)
饱和计数预测器(又称基本预测器)
-
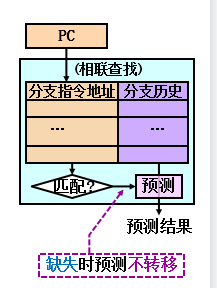
组成—分支历史表
分支历史一般占两位
查找/预测/更新机构(类似Cache)
-
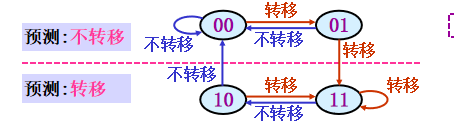
算法—根据分支历史高位预测(0不转移,1转移)
根据执行结果更新(饱和计数)分支历史
-
特点—
只根据当前分支指令的分支历史预测;<-未参考其他分支指令
连续两次预测错误才改变预测方向
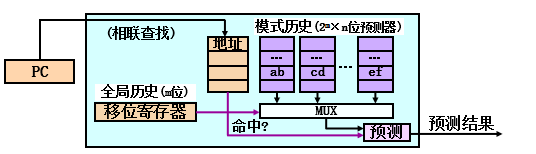
相关预测器(又称2级预测器)
-
思想—使用其他分支的行为来预测当前分支
-
组成—全局历史(m位)+模式历史表(\(2^m\)*n位)
-
算法—
根据全局历史(前m个分支的行为,选择当前所用模式历史;
根据所选模式历史(n位)。预测转移方向;
根据执行结果,更新全局历史、所选模式历史
Tournament预测器*全局/局部自适应预测器
- 组成—(以Alpha 21264预测器为例)
全局+局部历史,全局+局部预测器,自适应选择器 - 算法—预测器同基本预测器,选择器算法如图
- 特点—适于多分支预测,性能目前最好
转移历史管理
预测的结果—获得是否转移,分支目标地址
前面所讲的分支历史表(BHT)方法在ID段对BHT进行访问,所以在ID段末尾,可以获得分支目标地址(ID段计算出)、顺序下一条指令地址及预测结果
我们希望在IF段就可以获得这些信息(提前一拍),这样分支开销就可以减少为0
- 分支目标缓冲器(BTB)结构:(类似Cache)
表项组织--
相关参数--几K行,组相联映射,LRU替换算法,不写主存 - 转移历史管理:(基于BTB)
目标查找---用(PC)查BTB,标记=(PC)是BTB命中
历史建立---BTB缺失,标记结果为转移时,在新行(k)置:

历史更新---BTB命中、执行结束时,根据执行结果置:
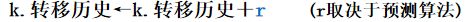
预测处理流程
-
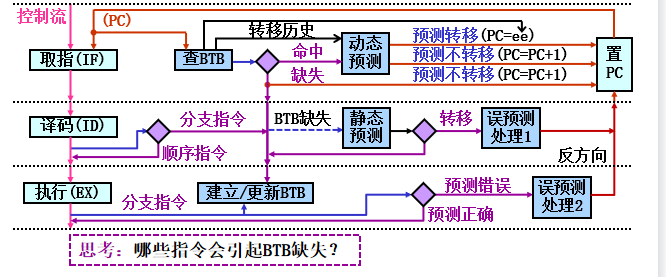
处理流程:
预测处理--IF段用(PC)查BTB,命中时预测PC,缺失时为PC+1
更新处理--CEX段根据执行结果,建立/更新转移历史,处理误预测
误预测处理--重置PC(预测的反方向),清空流水线(置为气泡)
-
流程优化(?)ID段对BTB缺失的分支指令进行静态预测(减少停顿、
-
性能分析
基于硬件的推测执行(speculation)
多流出的处理机,只准确地预测分支已经不能满足要求,因为有可能每个时钟周期都要执行一条分支指令。控制相关已经成了开发更多ILP的一个主要障碍。
推测执行能很好地解决控制相关问题,它对分支指令的结果进行猜测,并假设这猜测总是对的,然后按这个猜测结果继续取、流出和执行后续指令。执行的结果不是写回到寄存器或储存器,而是写入一个再定序缓冲器。等到相应的指令得到“确认”(确实是应该执行的),才将结果写入寄存器或储存器。
-
目标:支持动态分支预测+动态调度 <—需保持数据流+异常行为
误预测处理要求—分支指令结束前,预测指令不改变REG/MEM
调度范围选择—基本块内调度(性能差)、跨基本块调度(性能好) -
基本思想:
1)用动态分支预测技术选择后续指令
2)控制冒险消除前可执行后续指令(可处理误预测)
3)用动态预测技术处理数据冒险
图-0——-
核心- 按分支预测结果取指令,按动态调度结果执行指令,根据按序确认结果写结果 -
流水线结构
对Tomasulo算法加以扩充,就可以支持预测执行,硬件也做相应拓展
1) 增设分支目标缓冲器(BTB),实现动态分支预测
2)增杰再定序缓冲器(ROB),实现指令排队(按序确认)及暂存结果(用作临时FLR和SDB,原SDB缺省)
3)增设确认段(IC),实现按序确认后写结果
图图———— -
ROB组成(用于指令排队,用作临时FLR、SDB)
每一项由四个字段组成:指令类型,目的地址,数据值字段,就绪字段。 指令按序存放(无需保留源OPD,因为有RS)
图图——
-
寄存器重命名实现:用ROB项号实现(Tomasulo是RS/FLB站号)
图图—— -
推测执行结构示例
图图===
*指令流水组织
IS:从浮点指令队列头部取一条指令,如有空闲的保留站(r)且有空闲的ROB项(b),就流出该指令,把相应信息放入保留站r和ROB项b。即如果该指令需要的操作数已经在寄存器或ROB就绪,就把它们送入保留站r中,修改r和b的控制字段,表示它们已被占用。ROB项b的编号也要放入保留站r,以便当该保留站的执行结果被放到CDB上时可以用它作为标识。
EX:如果有操作数未就绪,就等待,并不断地检测CDB,这一步检测RAW冲突。当两个操作数都已在保留站中就绪后,就可以执行该指令的操作。load指令分两步完成(有效地址计算和读取数据)。store指令在这一步只进行有效地址计算
WB:当结果产生后,将该结果连同本指令在流出段所分配到的ROB项的编号放到CDB上,经CDB写到ROB以及所有等待该结果的保留站。然后释放产生该结构的保留站。store指令在本阶段完成,其操作有些特殊(不同于tomasulo——:如果要写入存储器的数据已经就绪,就把该数据写入分配给该store指令的ROB项。否则,就检测COB,直到那个数据在CDB上播送出来,才将之写入分配给该store指令的ROB项
IC:
1)对于除分支指令和stire指令以外的指令,当该指令到达ROB队列的头部而且结果已经就绪,就把该结果写入该指令的目的寄存器,并从ROB中删除该指令。
2)对于store指令的处理与1)类似,只是它把结果写入存储器
3)对于预测错误的分支指令到达ROB头部时,表示错误的预测执行,要清空ROB(流水线),从分支指令的另一个分支开始重新执行(重置PC)
4)当预测正确的分支指令到达ROB队列头部,该指令执行完毕,释放ROB行(不写PC)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号