Kettle 的错误处理机制:百万条数据转换下的“一行都不能少”
Kettle 的错误处理机制:百万条数据转换下的“一行都不能少”
在处理海量数据(例如从 SQL Server 到达梦数据库的迁移)任务中,我们面临一个经典而棘手的问题:如果过程中有一条数据失败,整个任务会怎样?是全部失败还是部分失败?本文将从理解Kettle的事务机制开始,一步步构建健壮的、能够自动捕获并处理错误的 ETL 流程,确保数据转换任务“不会失败”。
一、背景
在日常的数据工作中,有的时候会遇到大规模的数据同步或迁移需求。最近生态的项目在使用 ETL 的过程中,一位同事问了我一个具体的场景任务:将一张包含 50 万条记录的表从源数据库表完整地迁移到目标数据库,若中间数据传输过程中出现错误,数据是全失败还是部分失败?
这个问题确实很重要,关乎数据的完整性和一致性。如果在传输过程中,第 25 万条数据因为某种原因失败了,是已经成功传输的 249,999 条数据会回滚,还是整个转换中断,留下一部分已入库的数据?
带着这个疑问开启对 Kettle 错误处理机制的探索学习。
二、事务的“黑盒”,Kettle默认如何处理失败?
Kettle 中“表输出”(Table Output)步骤的事务处理逻辑的行为主要由提交记录数量配置决定。
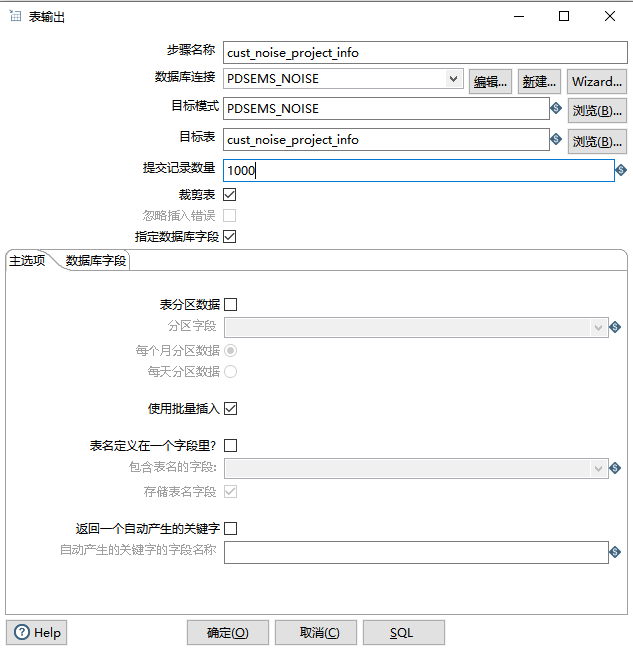
1. 核心控制器:“提交记录数量”(Commit size)
这是“表输出”步骤中最核心的性能与事务控制选项。它定义了 Kettle 每处理多少条数据就向目标数据库执行一次COMMIT(提交)。
-
分批提交(默认行为)
如果将此值设为 5000,Kettle 会每处理 5000 行就提交一次。若在第7001行出错,那么前5000行数据已经安全入库,包含错误行的第 5001-10000 行这个批次将失败回滚,整个转换停止。最终,数据库中会多出5000行“不完整”的数据。
-
“All-or-Nothing”模式
如果将此值设为 0,Kettle 会将所有百万条记录视为一个巨大的事务,仅在全部成功后才执行唯一的一次
COMMIT。这种模式下,任何一行数据失败都会导致整个事务回滚,实现了“要么全部成功,要么全部失败”。⚠注意: 对于海量数据,此设置会给数据库带来巨大的事务日志压力和长时间的表锁定,性能极差且风险高,生产环境强烈不推荐。
三、从被动接受到主动捕获:配置步骤级错误处理
无论是留下部分数据还是全部回滚,其实都不是理想的方案。我们更希望的是:让正确的数据继续传输,同时将出错的数据和错误原因精确地捕获下来,以供后续分析。
这时候就需要使用 Kettle 的错误处理机制了。
1. 如何配置?
在需要捕获错误的步骤上(如我们的“表输出”),右键点击并选择 “定义错误处理”。
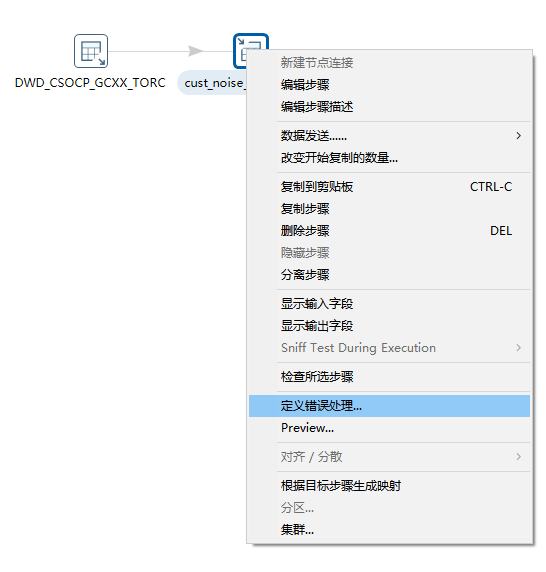
在弹出的“步骤错误处理设置”窗口中,我们可以进行详细配置:
- 目标步骤 (Target step): 最核心的选项。指定错误数据流要发送到哪个目标步骤(如一个“文本文件输出”或另一个日志表)。
- 启用错误处理? (Enable error handling?): 必须勾选的总开关。
- 错误数列名 (Number of errors field name): 自动增加一个新字段,用来存放这条数据上发现的错误数量(通常是1)。您需要为这个新字段命名。
- 错误描述列名 (Error description field name): 自动增加一个新字段,用来存放具体的错误文字描述。这是最有用的字段之一。
- 错误列的列名 (Error fields field name): 自动增加一个新字段,用来存放导致错误的字段(列)的名称。
- 错误编码列名 (Error codes field name): 自动增加一个新字段,用来存放 Kettle 内部或数据库返回的错误代码。
- 阈值控制:
- 允许的最大错误数/百分比: 设置一个上限,当错误超过此限制时,停止整个转换,防止意外的大量数据问题。错误数是设置具体的字段,错误百分比设置的是百分比,即当错误行数占总处理行数的百分比超过这个值时,转换失败。可不填。
- 在计算百分比前最少要读入的行数:这个是配合“最大错误百分比”使用的,防止在处理初期因为基数太小而导致转换过早失败。假设设置了最大错误百分比为10%,如果不在乎这个值,处理头两行就错了一行,错误率50%,转换就停了。如果这里设置为
1000,那么Kettle会至少处理1000行之后,才开始计算错误率是否超过了10%。

四、实战疑难排解:当“目标步骤”下拉框为空时
实践中立刻遇到了第一个问题:根据步骤,在画布上放置了一个用于接收错误的“文本文件输出”节点后,再次打开“定义错误处理”对话框,“目标步骤”的下拉框依然是空的。
1. 问题诊断1:违反了“先建目标,再设规则”的原则
“目标步骤”下拉框只会扫描并显示已经存在于画布上、且可以作为数据流输入的步骤。如果在打开对话框之前,没有在画布上放置好一个可用的目标(如“文本文件输出”),下拉框自然为空。
2. 问题诊断2:UI界面未刷新
有时即使目标已在画布上,Kettle 的 UI 也没有及时识别。
解决方案:按下 Ctrl + S 保存整个转换。这个动作会强制 Kettle 重新解析画布上的所有元素和关系,通常能解决 UI 刷新问题。
3. 正确且稳妥的方式:手动创建错误处理流
然而在我查询了很多资料并进行实践的时候,实际上即使在重启 Kettle 并确保所有操作无误后,下拉框依然空空如也。
我尝试直接拉一条线出来,手动创建错误处理连接。
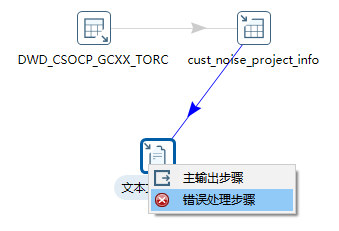
步骤
- 确保接收错误的“文本文件输出”节点孤立地放在画布上。
- 在键盘上按住
Shift键不放。 - 在按住
Shift的同时,从需要错误处理的“表输出”节点上点击并拖拽鼠标至“文本文件输出”节点。 - 松开鼠标,一个神奇的上下文菜单会弹出。
- 在这个菜单中,选择 “错误处理步骤” (Error handling of step)。
错误处理流建立成功。
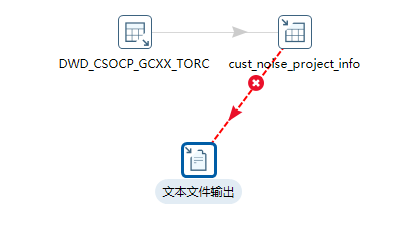
建立连接后,再次打开“定义错误处理”对话框,所有选项都已正常显示,可以顺利地填写错误信息字段名,并最终配置“文本文件输出”来接收和保存这些宝贵的错误日志。
五、错误数据处理最佳实践
- 不要将“提交记录数量”设为0或极大的数字:可能导致数据库事务过大,性能不佳且风险高。
- 设置一个合理的“提交记录数量”:根据服务器性能和网络状况,一个介于
1000到10000之间的值通常是比较理想的。这在性能和错误恢复之间取得了很好的平衡。 - 一定要配置错误处理!:这是专业 ETL 设计的关键。与其让整个任务失败,不如把出错的数据“抓”出来,让正确的数据继续入库。
- 在“表输出”节点上右键点击 -> 错误处理。
- 可以将出错的行(以及错误描述、错误字段等信息)重定向到另一个地方,比如一个文本文件或者数据库里的一个错误日志表。
- 这样,百万条数据跑完后,即使有几条失败了,主流程依然成功,并且得到了一个清晰的“错误报告”,可以针对性地去分析和修复这些坏数据。
从简单的“数据迁移失败了怎么办”问题出发,不仅深入理解了 Kettle 的事务模型,更重要的是掌握了构建健壮、可容错的 ETL 流程的核心:错误处理机制。
六、总结
默认情况下,Kettle 是分批提交的,失败前的批次会成功入库,需要合理设置Commit size是在性能和原子性之间取得平衡的关键。
对于任何生产级的 ETL 任务,配置错误处理都应该是标准操作,而非可选项。它能将“失败”转化为“可分析的数据”。
本文来自博客园,作者:knqiufan,转载请注明原文链接:https://www.cnblogs.com/knqiufan/p/18966114

 浙公网安备 33010602011771号
浙公网安备 33010602011771号