深入解析 Kettle "插入/更新"组件,实现高效数据同步
深入解析 Kettle "插入/更新"组件,实现高效数据同步
前言
在数据仓库和 ETL(抽取、转换、加载)领域,Pentaho Data Integration (PDI,又名 Kettle) 是一款功能强大且广受欢迎的开源工具。在日常的数据处理任务中,我们经常面临一个经典场景:如何将源数据同步到目标表,既要能插入新数据,也要能更新已有数据。Kettle 中的"插入/更新 (Insert / Update)"步骤正是为解决这一核心需求而设计的。
一、 "插入/更新"的核心逻辑
"插入/更新"步骤的工作流程可以概括为以下两步:
- 查询 (Lookup): 对于每一条从上游步骤流入的数据记录,该步骤会根据你设定的查询关键字 (Lookup Keys),去目标数据库表中进行一次查询。
- 决策与执行 (Decide & Execute):
- 如果查询找到匹配的记录: Kettle 会执行 更新 (Update) 操作,根据你的配置,更新目标表中指定字段的值。
- 如果查询未找到任何匹配记录: Kettle 会执行 插入 (Insert) 操作,将这条新记录插入到目标表中。
这个逻辑与 SQL 语言中的 MERGE 语句(或在某些数据库中需要通过 INSERT ... ON DUPLICATE KEY UPDATE 实现)的功能高度相似,但在 Kettle 中,它通过图形化界面被清晰地呈现出来,更易于理解和维护。
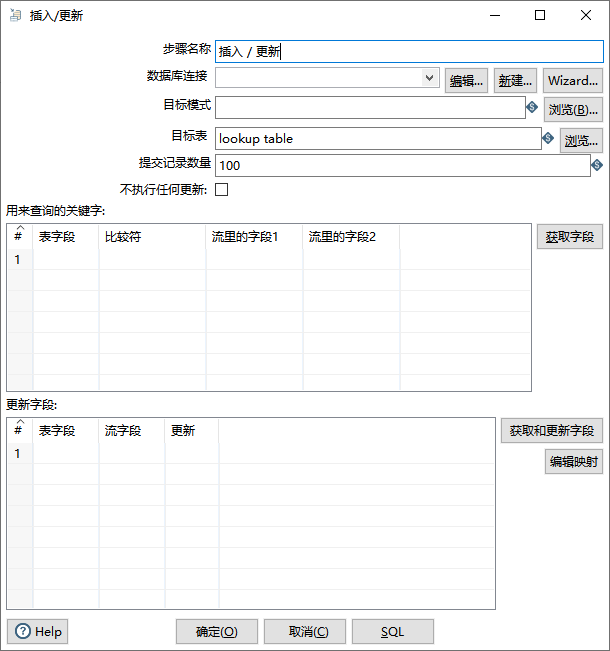
二、 配置选项详解
逐一拆解配置界面中的每一个选项。
1. 连接与目标 (Connection & Target)
这个区域定义了数据将要流向何处。

-
步骤名称 (Step name): 当前步骤的自定义唯一标识。建议使用能清晰反映其业务目的的名称。
-
数据库连接 (Database connection): 指定目标数据库的连接信息。这是所有操作执行的基础。
-
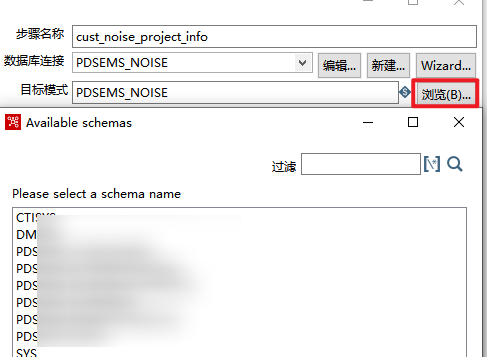
目标模式 (Target schema): 数据库的模式(Schema)。对于 Oracle, PostgreSQL, DB2,达梦等需要显式指定 Schema 的数据库,此项必填。在填写了数据库链接之后,点击浏览可以可视化选择
-
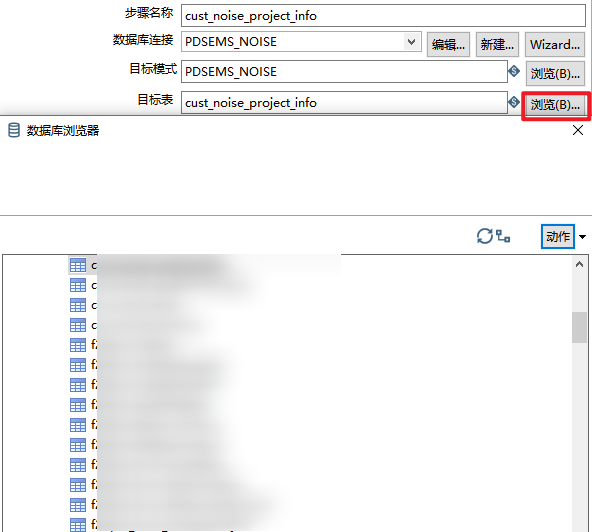
目标表 (Target table): 数据要写入的具体表名。在填写了目标模式之后,点击浏览可以可视化选择
-
提交记录数量 (Commit size): 事务提交的批次大小。这是一个至关重要的性能调优参数。设为
1000表示每处理 1000 条记录就向数据库提交一次事务。- 优点: 批量提交可以大幅提升写入性能。
- 缺点: 如果在两次提交之间发生错误,已处理但未提交的数据将会回滚。值越大,占用的内存和数据库日志也越多。
0表示在步骤执行完毕后才提交一次,适用于数据量小或需要保证整个步骤事务完整性的场景。
-
不执行任何更新? (Don't perform any update?): 一个重要的性能优化开关。
- 勾选后: 步骤将变为"若不存在则插入 (Insert if not exists)"。它依然会执行查询操作,但如果找到匹配项,它会直接跳过,什么也不做。这避免了更新操作的开销,在增量追加场景下非常高效。
- 不勾选 (默认): 执行完整的"查询 -> 更新或插入"逻辑。
2. 用来查询的关键字 (Keys to look up the values)
这是定义 UPDATE 和 SELECT 语句 WHERE 子句的地方,是整个步骤逻辑的核心。
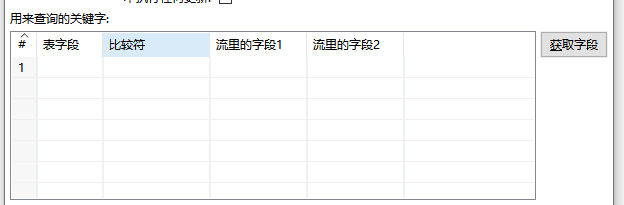
- 表字段 (Table field): 目标数据库表中的字段名。
- 比较符 (Comparator): 通常为
=。 - 流里的字段1 (Stream field 1): 来自上游数据流的字段名。
你可以定义一个或多个关键字,形成复合主键查询。例如,同时使用 UserID 和 OrderID 来唯一确定一条记录。
性能提示: 所有在"表字段"中用作查询关键字的列,必须在数据库中建立索引。这是决定此步骤性能的最关键因素,没有之一。如果关键字没有索引,Kettle 对每一条流记录的查询都将导致数据库进行全表扫描,当数据量稍大时,性能会急剧下降。
3. 更新字段 (Update fields)
这个区域定义了当记录匹配时,哪些字段需要被更新,以及当记录不匹配时,插入新行时包含哪些字段。

- 表字段 (Table field): 目标表中需要更新或插入的字段。
- 流字段 (Stream Field): 提供新值的上游数据流字段。
- 更新 (Update Y/N): 这是一个非常精妙的标志,但其作用也容易被误解。
- 对于更新 (Update) 操作: 只有当此标志为
Y(Yes) 时,如果查询到匹配记录,该字段才会被更新。如果为N(No),即使流中有新值,目标表的旧值也会保持不变。 - 对于插入 (Insert) 操作: 所有在此列表中定义的字段(无论其更新标志是Y还是N)都会作为新记录的一部分被插入。更新标志
N在插入场景下不起作用。
- 对于更新 (Update) 操作: 只有当此标志为
三、 神秘的【SQL】按钮

这个节点中,有个令人困惑的点是,点击【SQL】按钮时,弹出的窗口里往往不是我们预期的 SELECT、UPDATE 或 INSERT 语句,而是一堆 ALTER TABLE ... ADD ... 或 DROP ... 语句,让人误以为 Kettle 在执行插入或更新时,要修改表的结构内容。
实际上,【SQL】按钮是一个 DDL(数据定义语言)生成器,而不是 DML(数据操作语言)预览器。
它的工作逻辑是:
- 对比 Schema: Kettle 会严格比较数据流的结构(字段名、类型、长度等)和目标数据库物理表的结构。
- 生成差异化DDL: 它会生成必要的 SQL 语句,用于修改物理表,使其结构与数据流的结构完全匹配。
- 出现
ALTER TABLE ... ADD ...: 意味着数据流中的某些字段在目标表中不存在。 - 出现
ALTER TABLE ... MODIFY ...: 意味着数据流中和目标表中都存在的同名字段,但它们的类型或长度不一致。 - 出现
CREATE TABLE ...: 意味着目标表根本不存在。
- 出现
最重要的一点: 这些 SQL 语句不会在转换任务运行时自动执行。
Kettle 赋予你控制权,但不会越俎代庖地修改你的数据库表结构。
它的正确用途是:当你需要将数据写入一个新表,或者需要为一个旧表增加字段时,可以利用此功能快速生成 DDL 语句。然后,你可以复制这些语句到数据库客户端手动执行,完成对表结构的准备工作。
四、 性能调优与最佳实践
- 索引,索引,还是索引: 再次强调,为查询关键字在数据库中建立索引是性能的基石。
- 合理设置提交数量: 根据你的数据量、网络状况和数据库性能,找到一个合适的
Commit size。通常从1000或5000开始测试。 - 使用"不执行任何更新": 如果你的业务场景只是追加新数据(例如,每天的日志文件),请务必勾选此项以获得最佳性能。
- 数据预处理: 在数据到达"插入/更新"步骤之前,尽量进行过滤和清洗,减少需要处理的数据量。
- 关注数据库性能: 有时瓶颈在数据库端。监控数据库的锁、CPU 和 I/O,确保它能跟上 Kettle 的写入速度。
总结
"插入/更新"是 Kettle 中一个设计精良、功能强大的核心步骤。彻底理解它的配置选项——尤其是查询关键字、更新标志以及【SQL】按钮的真正用途——将使你能够灵活、高效地构建可靠的数据同步流程。避开常见的误区,遵循性能最佳实践,你就能将这个强大的工具运用自如,轻松应对各种复杂的数据集成挑战。
本文来自博客园,作者:knqiufan,转载请注明原文链接:https://www.cnblogs.com/knqiufan/p/18944708

 浙公网安备 33010602011771号
浙公网安备 33010602011771号