
mr Wordcount 程序
1.创建maven项目
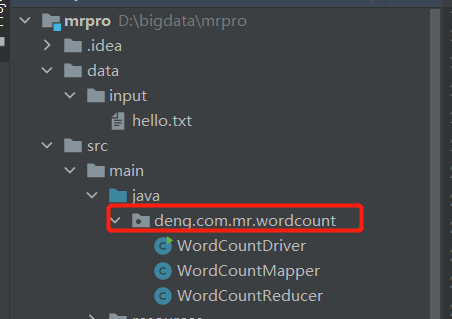
2.编写mr 程序
1.添加maven 依赖和插件
<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.1.3</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.30</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
2. 日志文件,在resources 目下新建log4j.properties 文件
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3. 编写maper 程序
package deng.com.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /* *Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> KEYIN 数据类型: LongWritable 偏移量 * VALUEIN: Text * * */ public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> { private Text kOut = new Text(); private IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // value : hello spark String line = value.toString(); // 按空格切分 String[] words = line.split(" "); for (String word : words) { // 封装 kOut.set(word); // 写出 context.write(kOut,v); } } }
4. 编写reducer
package deng.com.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class WordCountReducer extends Reducer<Text, IntWritable, Text,IntWritable> { private int sum; private IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { // (hello,{1,1,1,1}) sum=0; for (IntWritable value : values) { sum+=value.get(); } v.set(sum); // 写出 context.write(key,v); } }
5. 编写driver
package deng.com.mr.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountDriver { public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException { // 1.创建job Configuration conf = new Configuration(); Job job = Job.getInstance(conf); //2.关联jar包 job.setJarByClass(WordCountDriver.class); //3. 关联map和reduce jar包 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //4. map kv 输出格式 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //5. 最终的KV 输出格式 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //6. 设置输入和输路径 FileInputFormat.setInputPaths(job,new Path(args[0])); FileOutputFormat.setOutputPath(job,new Path(args[1])); //7. 提交job boolean result = job.waitForCompletion(true); System.exit(result?0:1); } }
6. 打包
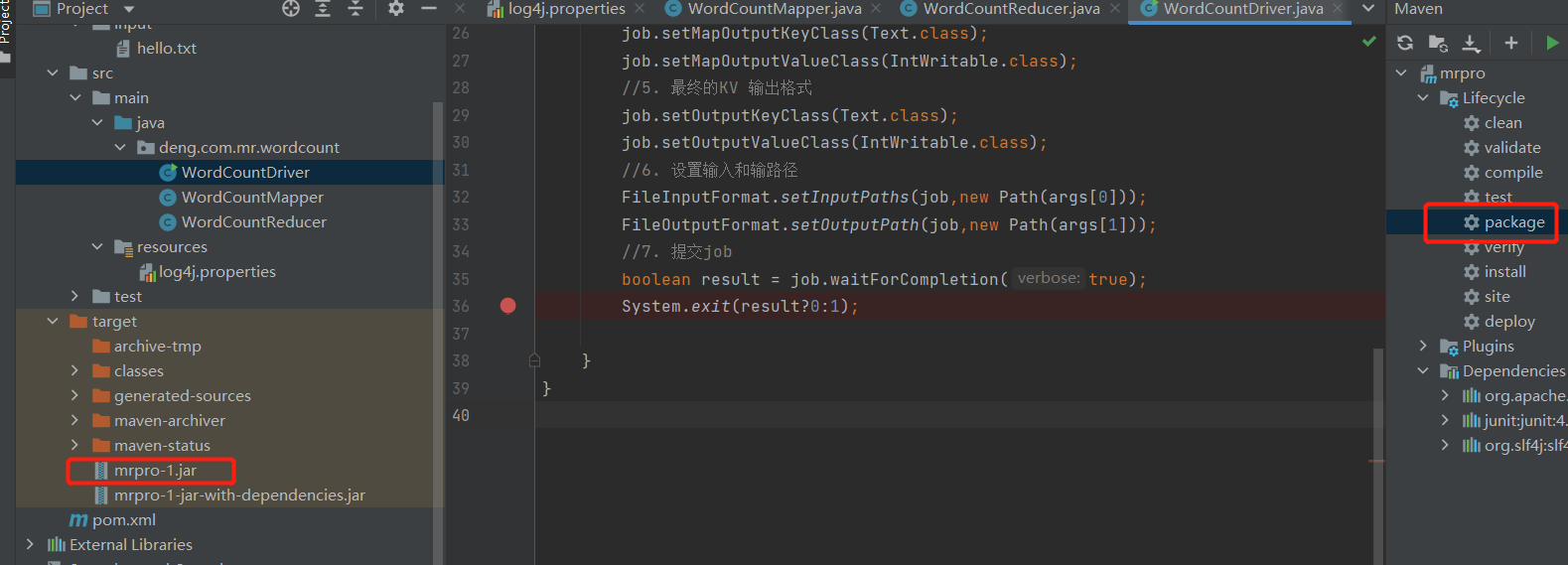
7. 将不带依赖得jar包,重名为wc.jar,上传linux 集群环境
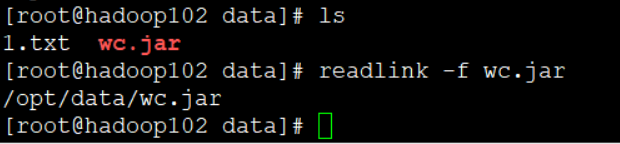
8. 运行

有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号