
3. Spark SQL
DataFrame
类似于传统数据库中的二维表格。DataFrame 也是懒执行的,但性能上比 RDD 要高,主要原因:优化的执行计划,即查询计划通过 Spark catalyst optimiser 进行优化。
DataSet
DataSet 是分布式数据集合。DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象。
DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]。
DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序。
SparkSQL 提供两种 SQL 查询起始点:
一个叫 SQLContext,用于 Spark自己提供的 SQL 查询;
一个叫 HiveContext,用于连接 Hive 的查询。
创建 DataFrame有三种方式
1)从 Spark 数据源进行创建
pom.xml


<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>spark-project</artifactId> <groupId>deng.xiake</groupId> <version>1.0</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>spark-sql</artifactId> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-yarn_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.27</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> </project>
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
读取,存储文件代码
import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession object SparkSqlDemo { def main(args:Array[String]):Unit={ // 创建环境 val conf = new SparkConf().setMaster("local").setAppName("deng") // val spark = SparkSession.builder().config(conf).getOrCreate() import spark.implicits._ //读取json 文件转化成DataFrame // val df = spark.read.json("datas/user.json") val df = spark.read.format("json").load("datas/user.json") df.show() val df2 = spark.read.format("csv").option("sep", ",").option("inferSchema", "true").option("header", "true").load("datas/1.csv") df2.show() //保存df数据 // df.write.mode("append").json("/opt/module/data/output") // df.write.format("json").save("datas/out") df.write.mode("append").format("csv").option("seq",",").save("datas/out") spark.stop() } }
RDD ,DataFrame,DataSet 相互转化
import org.apache.spark.sql.{Dataset, SparkSession} import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext} object SparkSQL { def main(args: Array[String]): Unit = { //1. 创建sparkSQL的运行环境 val conf = new SparkConf().setMaster("local").setAppName("sql") val spark = SparkSession.builder().config(conf).getOrCreate() // 在使用DataFrame时,如果涉及到转换操作,需要引入转换规则 import spark.implicits._ val df = spark.read.json("datas/user.json") df.show() // DataFrame => sql df.createOrReplaceTempView("user") spark.sql("select avg(age) from user").show() // df 操作 df.select("age").show() df.select($"age"+1).show // TODO DataSet 构建DataSet // 其实dataFrame是特定泛型的DataSet val seq = Seq(1,2,3,4) val ds:Dataset[Int] = seq.toDS() ds.show() // RDD <=> DataFrame val rdd = spark.sparkContext.makeRDD(List((1,"zhangshan",30),(2,"lisi",34))) val df2 = rdd.toDF("id","name","age") df2.show() // DataFrame=> RDD val rowRDD=df2.rdd // DataFrame => DataSet val ds2:Dataset[User]=df.as[User] // DataSet => DataFrame val df3 = ds2.toDF() // RDD=> DataSet 有数据有类型 // val ds3=rdd.map( // case(id,name,age)=>{ // User(id,name,age) // } // ).toDS() // // DataSet =>RDD 把数据和类型去掉 // val userRDD:RDD[User]=ds3.rdd spark.close() } // 准备样例类 case class User(id:Int,name:String,age:Int) }
DataFrame操作
df.printSchema
df.select("username").show()
df.select($"username",$"age" + 1).show()
df.select('username, 'age + 1).show()
df.select('username, 'age + 1 as "newage").show()
df.filter($"age">30).show
df.groupBy("age").count.show
1. RDD 转换为 DataFrame
实际开发中,一般通过样例类将 RDD 转换为 DataFrame
import org.apache.spark.sql.{Dataset, SparkSession} import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext} object SparkSQL { case class User(name: String, age: Int); def main(args: Array[String]): Unit = { //1. 创建sparkSQL的运行环境 val conf = new SparkConf().setMaster("local").setAppName("sql") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() import spark.implicits._ val rdd1 = sc.textFile("datas/id.txt") /*RDD 转化成DataFrame注意: * 样例类需要在main前面 * 需要引入隐式转换 * */ rdd1.toDF("name").show sc.makeRDD(List(("zhangsan", 30), ("lisi", 40))).map(t => User(t._1, t._2)).toDF.show } }
Spark 连接mysql
在 Idea 中通过 JDBC 对 Mysql 进行操作:
1.导入依赖
<dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.27</version> </dependency>
2. 读取数据
方式一: 通用的 load 方法读取
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object SparkSQL_Mysql { def main(args: Array[String]): Unit = { //1. 创建sparkSQL的运行环境 val conf = new SparkConf().setMaster("local").setAppName("sql") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() import spark.implicits._ spark.read.format("jdbc").option("url","jdbc:mysql://hadoop103:3306/deng") .option("driver", "com.mysql.jdbc.Driver").option("user", "root") .option("password", "156") .option("dbtable", "user") .load().show } }
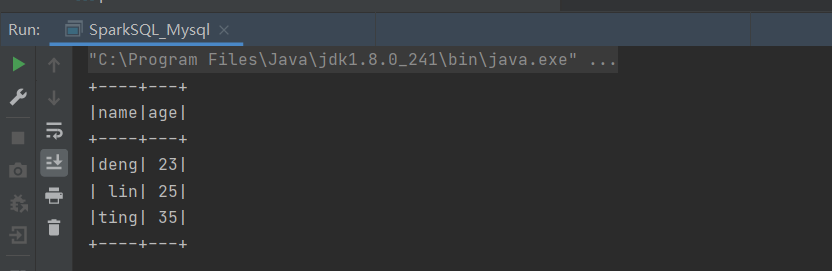
方式二: 通用的 load 方法读取 参数另一种形式
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object SparkSQL_Mysql2 { def main(args: Array[String]): Unit = { //1. 创建sparkSQL的运行环境 val conf = new SparkConf().setMaster("local").setAppName("sql") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() spark.read.format("jdbc").options( Map( "url"->"jdbc:mysql://hadoop103:3306/deng?user=root&password=123456", "dbtable"->"user", "driver"->"com.mysql.jdbc.Driver" ) ).load().show } }
方式3:使用jdbc 方式
import java.util.Properties import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object SparkSQL_Mysql2 { def main(args: Array[String]): Unit = { //1. 创建sparkSQL的运行环境 val conf = new SparkConf().setMaster("local").setAppName("sql") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() // 使用jdbc 的方式 val props= new Properties() props.setProperty("user", "root") props.setProperty("password", "123456") val df = spark.read.jdbc("jdbc:mysql://hadoop103:3306/deng","user",props) df.show() } }
Spark 连接外部Hive
需要通过以下几个步骤:
1.Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 conf/目录下
2.把 Mysql 的驱动 copy 到 jars/目录下
3. 如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下
4.重启 spark-shell
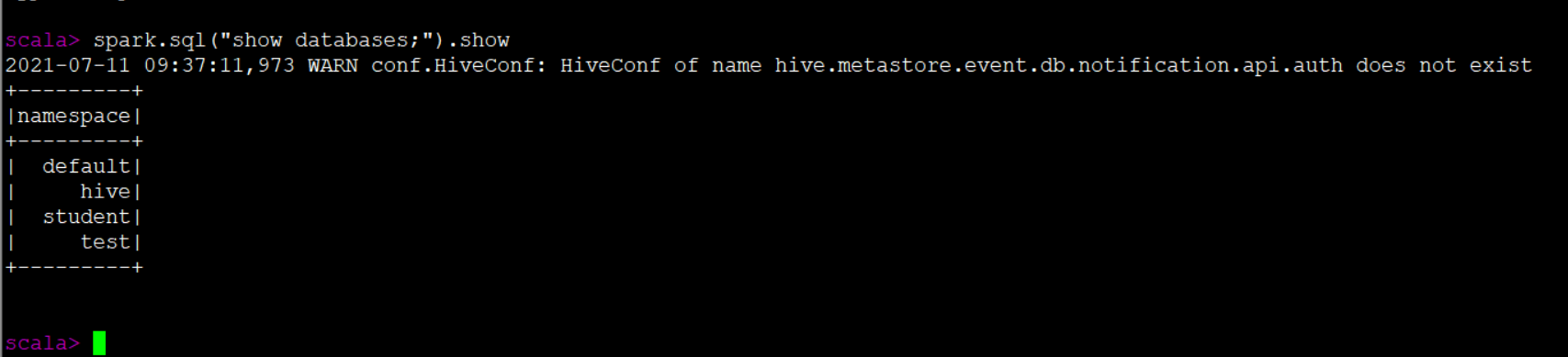
idea 中连接外部hive
1.将 hive-site.xml 文件拷贝到项目的 resources 目录中
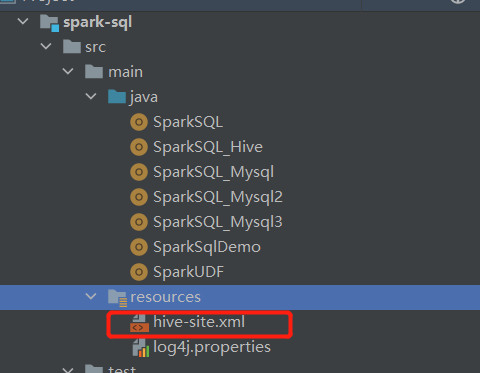
2.导入依赖:
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.27</version> </dependency>
3. 代码实现:
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object SparkSQL_Hive { def main(args: Array[String]): Unit = { // 遇到权限问题时: System.setProperty("HADOOP_USER_NAME", "root") //1. 创建sparkSQL的运行环境 val conf = new SparkConf().setMaster("local").setAppName("sql") val sc = new SparkContext(conf) val spark = SparkSession.builder().enableHiveSupport().config(conf).getOrCreate() import spark.implicits spark.sql("show databases").show() } }
注意:在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址:
config("spark.sql.warehouse.dir", "hdfs://linux1:8020/user/hive/warehouse")
如果在执行操作时,出现如下错误:
注意:在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址:
config("spark.sql.warehouse.dir", "hdfs://linux1:8020/user/hive/warehouse")
如果在执行操作时,出现如下错误:

此处的 root 改为自己的 hadoop 用户名称
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号