
spark算子
日志处理配置


log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
spark 依赖:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>spark_test</artifactId> <version>1.0-SNAPSHOT</version> <properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> </project>
转化算子
map 和mapPartions ,mapPartitionsWithIndex,flatMap
1. map
一行一行处理,相对不耗内存
2. mapPartions
以分区为单位进行数据转化操作
但会将整个分区中的数据加载到内存中进行引用
在内存较小,数据量较大的时候容易发生内存溢出。
将待处理的数据以分区为单位发送到计算节点进行处理,这里的处理是指可以进行任意的处
理,哪怕是过滤数据。
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkMapPartions { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val rdd1 =sc.makeRDD(List(2,1,3,2,3,4)) val rdd2= rdd1.mapPartitions( data => data.filter(_==2) ) rdd2.collect().foreach(println) sc.stop() } }
获取每个分区中的最大值
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkMapPartions { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val rdd1 =sc.makeRDD(List(2,1,3,2,3,4),2) val rdd2= rdd1.mapPartitions( iter=> { // 输入一个迭代器,要返回一个迭代器 List(iter.max).iterator } ) rdd2.collect().foreach(println) sc.stop() } }
3.mapPartitionsWithIndex
可以知道数据来自哪个分区
案例1: 区分数据来源哪个分区
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkMapPartitionsWithIndex2 { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val dataRDD =sc.makeRDD(List(1,2,3,4),2) val dataRDD1 = dataRDD.mapPartitionsWithIndex( (index, iter) => { iter.map( num=>{ (index,num) } ) }) dataRDD1.collect().foreach(println) sc.stop() } }
案例2:保留某分区中的数据
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkMapPartitionsWithIndex { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val dataRDD =sc.makeRDD(List(1,2,3,4),2) val dataRDD1 = dataRDD.mapPartitionsWithIndex( (index, iter) => { if (index==1){ // 保留一号分区的数据 iter }else{ Nil.iterator } }) dataRDD1.collect().foreach(println) sc.stop() } }
4.flatMap
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkFlatMap { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setAppName("flatMapTest") val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(List(1, 2, 3), List(45, 56), 23)) var flatRdd = rdd1.flatMap( data=>{
// 模式匹配 data match { case list: List[_]=>list case dat=>List(dat) } }) flatRdd.collect().foreach(println) } }
glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
package deng.xiakeyun.bigdata.operator import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkGlom { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) // Array--- > Int val dataRDD: RDD[Int]=sc.makeRDD(List(1,2,3,4),2) // Int ---> Array val glomRDD:RDD[Array[Int]]= dataRDD.glom() glomRDD.collect().foreach(data=>println(data.mkString(","))) sc.stop() } }
计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
package deng.xiakeyun.bigdata.operator import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkGlom2 { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) // Array--- > Int val dataRDD: RDD[Int]=sc.makeRDD(List(1,2,3,4),2) // Int ---> Array val glomRDD:RDD[Array[Int]]= dataRDD.glom() val maxRDD = glomRDD.map( // 获取每个分区的最大值 data=>data.max ) println(maxRDD.collect().sum) sc.stop() } }
groupBy
例1. 按奇偶分组
package deng.xiakeyun.bigdata.operator import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkGroupBy { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val dataRDD =sc.makeRDD(List(1,2,3,4),2) // groupBy 会将数据源中的每一个数据进行分组判断,根据返回的分组 // key进行分组,相同key值的数据会放在一个组中 def groupFunction(num:Int):Int={ // 奇数和偶数分开 num%2 } val groupRDD:RDD[(Int,Iterable[Int])]=dataRDD.groupBy(groupFunction) groupRDD.collect().foreach(println) sc.stop() } }
例2. 按首字母分组
package deng.xiakeyun.bigdata.operator import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkGroupBy { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val dataRDD =sc.makeRDD(List("spark","deng","wang","den","spk"),2) // groupBy 会将数据源中的每一个数据进行分组判断,根据返回的分组 // key进行分组,相同key值的数据会放在一个组中 // 分区和分组没有必然关系 // 数据会打乱,重新组合(shuffer) val groupRDD=dataRDD.groupBy(_.charAt(0)) groupRDD.collect().foreach(println) sc.stop() } }
例3:统计日志中不同时间段的访问量
a.log日志格式:
83.149.9.216 - - 17/05/2015:10:05:03 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-search.png
83.149.9.216 - - 17/05/2015:10:05:43 +0000 GET /presentations/logstash-monitorama-2013/images/kibana-dashboard3.png
83.149.9.216 - - 17/05/2015:10:05:47 +0000 GET /presentations/logstash-monitorama-2013/plugin/highlight/highlight.js
83.149.9.216 - - 17/05/2015:10:05:12 +0000 GET /presentations/logstash-monitorama-2013/plugin/zoom-js/zoom.js
83.149.9.216 - - 17/05/2015:10:05:07 +0000 GET /presentations/logstash-monitorama-2013/plugin/notes/notes.js
代码:
package deng.xiakeyun.bigdata.operator import java.text.SimpleDateFormat import org.apache.spark.{SparkConf, SparkContext} object SparkGroup { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val dataRDD =sc.textFile("datas/a.log") val timeRdd = dataRDD.map( line=>{ val datas = line.split(" ") // 获取时间那短字符串 7/05/2015:10:05:34 val time = datas(3) val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss") val date = sdf.parse(time) val sdf1= new SimpleDateFormat("HH") val hour:String = sdf1.format(date) (hour,1) } ).groupBy(_._1) val resultRDD = timeRdd.map{ case (hour,iter) =>{ (hour,iter.size) } } resultRDD.collect().foreach(println) sc.stop() } }
package deng.xiakeyun.bigdata.operator import java.text.SimpleDateFormat import org.apache.spark.{SparkConf, SparkContext} object SparkGroup { def main(args:Array[String]) :Unit ={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val dataRDD =sc.textFile("datas/a.log") def groupFunction(t:Tuple2[String,Int]):String={ // 奇数和偶数分开 t._1 } val timeRdd = dataRDD.map( line=>{ val datas = line.split(" ") // 获取时间那短字符串 7/05/2015:10:05:34 val time = datas(3) val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss") val date = sdf.parse(time) val sdf1= new SimpleDateFormat("HH") val hour:String = sdf1.format(date) (hour,1) } // ).groupBy(_._1) ).groupBy(groupFunction) val resultRDD = timeRdd.map{ case (hour,iter) =>{ (hour,iter.size) } } resultRDD.collect().foreach(println) sc.stop() } }
filter 和distinct
package deng.xiakeyun.bigdata.operator import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkFilterAndDistinct { def main(args:Array[String]):Unit={ val conf = new SparkConf().setMaster("local[*]").setAppName("deng") val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(1,2,34,2,2,3)) // distinct 去重底层: (1,null),(2,null) 通过reduceByKey() ,map 实现 val rdd2 = rdd1.distinct() rdd2.collect().foreach(println) // filter 过滤 println("==========spark filter ===========") // 过滤掉值为2 后的结果 rdd1.filter(x=>x!=2).collect().foreach(println) } }
coalesce 和repartiton
package deng.xiakeyun.bigdata.operator import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object SparkCoalesces { def main(args:Array[String]):Unit={ // val conf = new SparkConf().setMaster("local").setAppName("spark coalesce") val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(1,2,3,4),2) // 1. coalesce 缩减分区 // 2. coalesce 第二个参数,是否需要打乱重整 shuffle=flase 时,不打乱重整,可能会出现数据分布不均,此情况扩大分区无效 // 3. coalesce 扩大分区:shuffle=true 时,可以用来扩大分区,以及数据重分区 // 4. repartition: 扩大分区 ,底层就是coalesce 设置了shuffle =true 来实现的 // val rdd2 = rdd1.coalesce(4,false) val rdd2 = rdd1.repartition(4) rdd2.saveAsTextFile("outpath") sc.stop() } }
sortBy
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkSortBy { def main(args: Array[String]): Unit = { val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(1, 34, 2, 4)) // 根据本身进行排序 val rdd2 = rdd1.sortBy(x => x) rdd2.collect().foreach(println) var rdd3 = sc.makeRDD(List(("21", "deng"), ("34", "wang"), ("110", "lin"))) val rdd4 = rdd3.sortBy(x => x._1) rdd4.collect().foreach(println) /* * (110,lin) (21,deng) (34,wang) * * */ val rdd5 = rdd3.sortBy(x => x._1.toInt) rdd5.collect().foreach(println) /* * (21,deng) (34,wang) (110,lin) * * */ // sortBy 默认不会改变分区操作,但存在shuffle操作 // ascending =false降序 排列 val rdd6 = rdd3.sortBy(x => x._1.toInt, false) rdd6.collect().foreach(println) } }
交集,并集,差集,拉链
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object Spark2Vaule { def main(args:Array[String]):Unit={ /** * 交集,并集,差集 两个数据源的数据类型需要一致 * 拉链zip 数据类型可以不一致,但两个数据源的分区数需要一致,两个数据源分区数据量要保持一致 * */ / val conf = new SparkConf().setMaster("local").setAppName("spark coalesce") val sc = new SparkContext(conf) // 双vaule算子 val rdd1 = sc.makeRDD(List(1,2,3,4),2) val rdd2 = sc.makeRDD(List(3,4,5,6),2) // 1.交集 3,4 val rdd3 = rdd1.intersection(rdd2) println(rdd3.collect().mkString(",")) // 2.并集 1,2,3,4,3,4,5,6 val rdd4 = rdd1.union(rdd2) println(rdd4.collect().mkString(",")) // 3. 差集1,2 val rdd5= rdd1.subtract(rdd2) println(rdd5.collect().mkString(",")) // 4. 拉链 (1,3),(2,4),(3,5),(4,6) val rdd6 = rdd1.zip(rdd2) println(rdd6.collect().mkString(",")) sc.stop() } }
partitionBy
自定义分区器:
package deng.part import org.apache.spark.{HashPartitioner, Partitioner, SparkConf, SparkContext} object SparkPartitionBy { def main(args:Array[String]):Unit={ /* * 自定义分区器 * 重写方法 * */ val conf = new SparkConf().setAppName("partitioner").setMaster("local") val sc = new SparkContext(conf) val rdd1 = sc.makeRDD(List(("nba",1),("nba",2),("wba",4),("dj",6))) val p_rdd = rdd1.partitionBy(new MyPartitioner) p_rdd.saveAsTextFile("outpath") sc.stop() } // 自定义分区器 class MyPartitioner extends Partitioner{ //多少个分区 override def numPartitions: Int = 3 // 将不同的数据分配到不同的分区中 override def getPartition(key: Any): Int = { // if (key=="nba"){ // 0 // }else if(key=="wba"){ // 1 // }else{ // 2 // } key match { case "nba"=>0 case "wba"=>1 case _=>2 } } } }
import org.apache.spark.{Partitioner, SparkConf, SparkContext} import scala.util.Random object SparkMyParitition { def main(args: Array[String]): Unit = { // val conf = new SparkConf().setMaster("local[*]").setAppName("partition") val sc = new SparkContext(conf) val rdd1 = sc.textFile("datas/word.txt") val rdd2 = rdd1.flatMap(_.split(" ")).map((_, 1)).reduceByKey(new MyPartitioner(),_+_) rdd2.saveAsTextFile("data/out") sc.stop() } // 自定义分区器 class MyPartitioner extends Partitioner{ override def numPartitions: Int =3 override def getPartition(key: Any): Int = { if(key.equals("spark")){ Random.nextInt(2) }else{ 2 } } } }
groupBy, groupByKey, reduceByKey,aggrateByKey, foldByKey,combineByKey
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkKvVaule { def main(args:Array[String]):Unit={ val conf = new SparkConf().setMaster("local").setAppName("wordcount") val sc = new SparkContext(conf) /* * groupBy : [("a",[("a",1),("a",2),("a",3)]),("b",[("b",1)])] * groupByKey: [("a",[1,2,3]),("b",4)],会导致数据打乱重组,存在shuffle 操作,再用map聚合 * reduceByKey: 支持分区内预聚合功能combine,分区内先聚合,之后再分区间聚合,可以减少shuffle时落盘的数据量,所以性能优于groupByKey() * reduceByKey 分区内和分区间的聚合规则是一样的 * aggregateByKey: 分区内和分区间的规则可以不一样,例: 分区内求最大值,分区间求和 * spark 中,shuffle 操作必须落盘处理,不能在内存中数据等待,会导致内存溢出。 * */ val rdd1 = sc.makeRDD(List(("a",1),("a",2),("a",3),("b",4)),2) val rdd2 = rdd1.groupBy(x=>x._1) println(rdd2.collect().mkString(",")) //(a,CompactBuffer((a,1), (a,2), (a,3))),(b,CompactBuffer((b,4))) val rdd3 = rdd1.groupByKey() println(rdd3.collect().mkString(",")) // (a,CompactBuffer(1, 2, 3)),(b,CompactBuffer(4)) /* * aggregateByKey * 函数柯里化 * 第一个参数:初始值zeroVaule 一般为0 * 第二个参数:分区内规则和分区间规则(可以不同) * aggregateByKey 最终的返回值类型应该和初始值保持一致 * * flodByKey: * 如何聚合时,分区内和分区间的聚合规则一样 * */ // // aggregateByKey 分区内和分区间的规则可以不一样 也可以一样 //1. aggregateByKey 分区内和分区间的规则可以不一样时: val rdd4= rdd1.aggregateByKey(0)( (x,y)=>math.max(x,y),// 分区内取最大值 (x,y)=>x+y // 分区间最大值求和 ) println(rdd4.collect().mkString(",")) //(b,4),(a,5) //2. aggregateByKey 分区内和分区间的规则一样时: val rdd5 = rdd1.aggregateByKey(0)(_+_,_+_) println(rdd5.collect().mkString(",")) //(b,4),(a,6) // 3. foldBykey: 分区内和分区间的规则一样时: val rdd6= rdd1.foldByKey(0)(_+_) println(rdd6.collect().mkString(",")) //(b,4),(a,6) } }
reduceByKey 和 groupByKey 的区别?
从 shuffle 的角度:reduceByKey 和 groupByKey 都存在 shuffle 的操作,但是 reduceByKey
可以在 shuffle 前对分区内相同 key 的数据进行预聚合(combine)功能,这样会减少落盘的
数据量,而 groupByKey 只是进行分组,不存在数据量减少的问题,reduceByKey 性能比较
高。
从功能的角度:reduceByKey 其实包含分组和聚合的功能。GroupByKey 只能分组,不能聚
合,所以在分组聚合的场合下,推荐使用 reduceByKey,如果仅仅是分组而不需要聚合。那
么还是只能使用 groupByKey
reduceByKey、foldByKey、aggregateByKey、combineByKey 的区别?
reduceByKey: 相同 key 的第一个数据不进行任何计算,分区内和分区间计算规则相同
FoldByKey: 相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规则相同
AggregateByKey:相同 key 的第一个数据和初始值进行分区内计算,分区内和分区间计算规
则可以不相同
CombineByKey:当计算时,发现数据结构不满足要求时,可以让第一个数据转换结构。分区
内和分区间计算规则不相同。
源码分析:
/* reduceByKey: combineByKeyWithClassTag[V]( (v: V) => v, // 第一个值不会参与计算,第一个值是啥返回啥 func, // 分区内计算规则 func, // 分区间计算规则 ) aggregateByKey : combineByKeyWithClassTag[U]( (v: V) => cleanedSeqOp(createZero(), v), // 初始值和第一个key的value值进行的分区内数据操作 cleanedSeqOp, // 分区内计算规则 combOp, // 分区间计算规则 ) foldByKey: combineByKeyWithClassTag[V]( (v: V) => cleanedFunc(createZero(), v), // 初始值和第一个key的value值进行的分区内数据操作 cleanedFunc, // 分区内计算规则 cleanedFunc, // 分区间计算规则 ) combineByKey : combineByKeyWithClassTag( createCombiner, // 相同key的第一条数据进行的处理函数 mergeValue, // 表示分区内数据的处理函数 mergeCombiners, // 表示分区间数据的处理函数 ) */ rdd.reduceByKey(_+_) // wordcount rdd.aggregateByKey(0)(_+_, _+_) // wordcount rdd.foldByKey(0)(_+_) // wordcount rdd.combineByKey(v=>v,(x:Int,y)=>x+y,(x:Int,y:Int)=>x+y) // wordcount
例子:每个相同key的平均值
(1)用 aggregateByKey实现
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkAggreateByKey { def main(args:Array[String]):Unit={ //配置信息 var conf = new SparkConf().setMaster("local").setAppName("deng") // val sc = new SparkContext(conf) // 1.分区内求最大值,分区间求和 aggregateByKey 函数柯里化 val rdd1 = sc.makeRDD(List(("a",1),("a",2),("b",4),("a",3),("a",4),("b",6)),2) val rdd2 = rdd1.aggregateByKey(0)( (x,y)=>math.max(x,y), (x,y)=>x+y ) println(rdd2.collect().mkString(",")) //2. 求每个 key 的平均值 (a,5),(b,5) //下面第一个位置的(0,0)第一个0 代表初始值的value,第2个0 代表初始值表示某key出现次数 val rdd3= rdd1.aggregateByKey((0,0))( // v 表示key代表的值,t 表示前一个结果 和(0,0)类似 // ((0,0),1)=>(0+1,0+1), (t,v)=>(t._1+v,t._2+1), (t1,t2)=>(t1._1+t2._1,t1._2+t2._2) ) rdd3.collect().foreach(println) /* 结果: * (b,(10,2)) (a,(10,4)) * */ val rdd4= rdd3.mapValues( x=>x._1/x._2 ) rdd4.collect().foreach(println) /* 结果 * (b,5) (a,2) * */ } }
(2)使用combineByKey() 实现, 其有3个参数,第一个参数不是对初始值的转化规则
package deng.xiakeyun.bigdata.operator import org.apache.spark.{SparkConf, SparkContext} object SparkAggreateByKey { def main(args:Array[String]):Unit={ //配置信息 var conf = new SparkConf().setMaster("local").setAppName("deng") // val sc = new SparkContext(conf) // 分区内求最大值,分区间求和 aggregateByKey 函数柯里化 val rdd1 = sc.makeRDD(List(("a",1),("a",2),("b",4),("a",3),("a",4),("b",6)),2) val rdd2 = rdd1.aggregateByKey(0)( (x,y)=>math.max(x,y), (x,y)=>x+y ) println(rdd2.collect().mkString(",")) // 求每个 key 的平均值 (a,5),(b,5) //下面第一个位置的(0,0)第一个0 代表初始值的value,第2个0 代表初始值表示某key出现次数 val rdd3= rdd1.aggregateByKey((0,0))( // v 表示key代表的值,t 表示前一个结果 和(0,0)类似 // ((0,0),1)=>(0+1,0+1), (t,v)=>(t._1+v,t._2+1), (t1,t2)=>(t1._1+t2._1,t1._2+t2._2) ) rdd3.collect().foreach(println) /* 结果: * (b,(10,2)) (a,(10,4)) * */ val rdd4= rdd3.mapValues( x=>x._1/x._2 ) rdd4.collect().foreach(println) /* 结果 * (b,5) (a,2) * */ //使用combineByKey() val rdd5 = rdd1.combineByKey( x=>(x,1),// 将分区内的相同key的第一个数转化成初始值 v=>(v,1) (t:(Int,Int),v)=>(t._1+v,t._2+1), (t1:(Int,Int),t2:(Int,Int))=>(t1._1+t2._1,t1._2+t2._2) ) println("=============combineByKey==================") rdd5.collect().foreach(println) /* * 结果: * (b,(10,2)) (a,(10,4)) * */ println(rdd5.mapValues(x=>x._1/x._2).collect().mkString(",")) // (b,5),(a,2) } }
行动算子
行动算子会触发作业的执行
1. rdd.collect()
会将不同分区的数据按分区顺序采集到Driver端内存,形成数组。
2.rdd.reduce()
......
package deng.xiakeyun.bigdata.operator.action import org.apache.spark.{SparkConf, SparkContext} object SparkAction { def main(args:Array[String]):Unit={ //1. 配置信息 val conf = new SparkConf().setMaster("local").setAppName("action") //2. 构建上下文对象 val sc = new SparkContext(conf) // 3 val rdd = sc.makeRDD(List(2,7,3,4,5)) // reduce 聚合 val sum = rdd.reduce(_+_) println(sum)// 15 // rdd.count 统计数据 println(rdd.count()) // 获取数据源中的第一个数 println(rdd.first()) //rdd.take(3)// 获取数据源中的前3个数据 println(rdd.take(3)) //rdd.takeOrdered(num) 数据排序后取前num数据 println(rdd.takeOrdered(3)) // aggregate println(rdd.aggregate(0)(_+_,_+_)) //21 println(rdd.aggregate(10)(_+_,_+_))//41 //fold 折叠操作,aggregate 的简化版操作 println(rdd.fold(0)(_+_))//21 println(rdd.fold(10)(_+_))//41 //countByKey 统计每个key 出现的次数 val rdd2 = sc.makeRDD(List(("a",2),("a",1),("b",2),("a",2),("a",3),("b",2))) println(rdd2.countByKey()) //Map(a -> 4, b -> 2) } }
RDD 序列化
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor
端执行
案例1:
object serializable02_function { def main(args: Array[String]): Unit = { //1.创建 SparkConf 并设置 App 名称 val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") //2.创建 SparkContext,该对象是提交 Spark App 的入口 val sc: SparkContext = new SparkContext(conf) //3.创建一个 RDD val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "hive", "atguigu")) //3.1 创建一个 Search 对象 val search = new Search("hello") //3.2 函数传递,打印:ERROR Task not serializable search.getMatch1(rdd).collect().foreach(println) //3.3 属性传递,打印:ERROR Task not serializable search.getMatch2(rdd).collect().foreach(println) //4.关闭连接 sc.stop() } } class Search(query:String) extends Serializable { def isMatch(s: String): Boolean = { s.contains(query) } // 函数序列化案例 def getMatch1 (rdd: RDD[String]): RDD[String] = { //rdd.filter(this.isMatch) rdd.filter(isMatch) }
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
rdd.filter(x => x.contains(query))
//val q = query
//rdd.filter(x => x.contains(q))
}
}
Kryo 序列化框架
使用 Kryo 序列化,也要继承 Serializable 接口
object serializable_Kryo { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf() .setAppName("SerDemo") .setMaster("local[*]") // 替换默认的序列化机制 .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // 注册需要使用 kryo 序列化的自定义类 .registerKryoClasses(Array(classOf[Searcher])) val sc = new SparkContext(conf) val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2) val searcher = new Searcher("hello") val result: RDD[String] = searcher.getMatchedRDD1(rdd) result.collect.foreach(println) } } case class Searcher(val query: String) { def isMatch(s: String) = { s.contains(query) } def getMatchedRDD1(rdd: RDD[String]) = { rdd.filter(isMatch) } def getMatchedRDD2(rdd: RDD[String]) = { val q = query rdd.filter(_.contains(q)) } }
RDD 持久化
1.RDD Cache 缓存
// cache 操作会增加血缘关系,不改变原有的血缘关系 println(wordToOneRdd.toDebugString) // 数据缓存。 wordToOneRdd.cache() // 可以更改存储级别 //mapRdd.persist(StorageLevel.MEMORY_AND_DISK_2)
存储级别
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
Spark 会自动对一些 Shuffle 操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点 Shuffle 失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用 persist 或 cache。
2.RDD CheckPoint 检查点
所谓的检查点其实就是通过将 RDD 中间结果写入磁盘由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。对 RDD 进行 checkpoint 操作并不会马上被执行,必须执行 Action 操作才能触发。
// 设置检查点路径 sc.setCheckpointDir("./checkpoint1") // 创建一个 RDD,读取指定位置文件:hello spark hello scala val lineRdd: RDD[String] = sc.textFile("input/1.txt") // 业务逻辑 val wordRdd: RDD[String] = lineRdd.flatMap(line => line.split(" ")) val wordToOneRdd: RDD[(String, Long)] = wordRdd.map { word => { (word, System.currentTimeMillis()) } } // 增加缓存,避免再重新跑一个 job 做 checkpoint wordToOneRdd.cache() // 数据检查点:针对 wordToOneRdd 做检查点计算 wordToOneRdd.checkpoint() // 触发执行逻辑 wordToOneRdd.collect().foreach(println)
3.缓存和检查点区别
1)Cache 缓存只是将数据保存起来,不切断血缘依赖。Checkpoint 检查点切断血缘依赖。
2)Cache 缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint 的数据通常存
储在 HDFS 等容错、高可用的文件系统,可靠性高。
3)建议对 checkpoint()的 RDD 使用 Cache 缓存,这样 checkpoint 的 job 只需从 Cache 缓存
中读取数据即可,否则需要再从头计算一次 RDD。
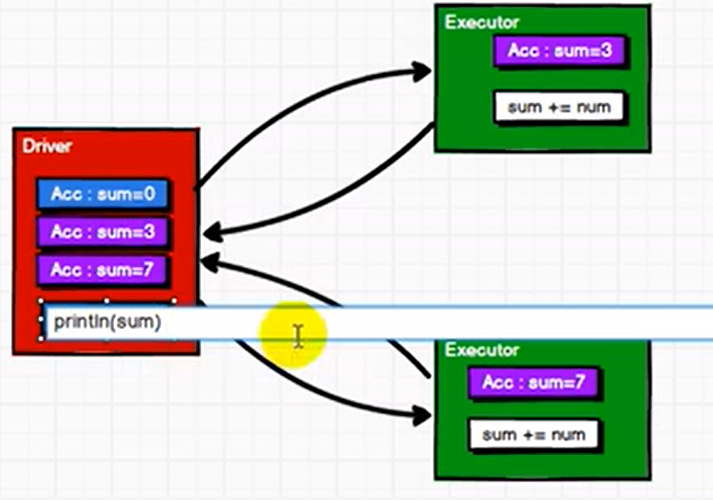
累加器:分布式共享只写变量
1.用来把excutor端的数据聚合到driver端。
2. 传回driver 进行merge
3. 转化算子中如果调用累加器没有触发行动算子时,是不会执行的(少加现象)。
4. 多少次调用包含累加器逻辑的rdd 触发行动算子时,会出现多加现象。
5. 一般情况下累加器放在行动算子中。
未使用累加器时:

使用累加器时:
例1:系统自带的累加器
import org.apache.spark.{SparkConf, SparkContext} object SparkAcc { def main(args:Array[String]):Unit={ //conf val conf = new SparkConf().setMaster("local").setAppName("deng") val sc = new SparkContext(conf) // 系统累加器 // 累加器的作用是将excutor端的数据聚合到driver端 val rdd = sc.makeRDD(List(1,2,3,4,5)) //定义累加器 val acc = sc.longAccumulator("sum") rdd.foreach( num=>{ // 使用累加器 acc.add(num) } ) // 获取累加器的值 println(s"acc的值为${acc.value}") } }
例2: 自定义累加器(wordcount)
import org.apache.spark.util.AccumulatorV2 import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable object MyAcc { def main(args: Array[String]): Unit = { //conf val conf = new SparkConf().setMaster("local").setAppName("deng") val sc = new SparkContext(conf) val rdd = sc.makeRDD(List("spark", "scala", "spark", "python")) /* * 自定义累加器 WordCount * 继承 AccumulatorV2[IN,OUT] 定义泛型 * IN: 累加器输入的数据类型,String * OUT: 累加器返回的数据类型 mutable.Map[String,Long] //1. 创建累加器 * 2. 注册累加器 * 3. 使用累加器 * 4. 获取累加器的结果 * */ // 1.创建累加器 val wcAcc = new MyAccumulator() // 2. 注册累加器 sc.register(wcAcc, name = "wordCountAcc") rdd.foreach( word => { // 3. 使用累加器 wcAcc.add(word) } ) // 获取累加器的值 val result = wcAcc.value println(result) sc.stop() } //自定义累加器,extends AccumulatorV2 class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]] { // 准备一个空的map private var wcMap = mutable.Map[String, Long]() // 判断是否为初始状态 override def isZero: Boolean = { wcMap.isEmpty } override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = { new MyAccumulator() } override def reset(): Unit = { wcMap.clear() } // 获取累加器需要计算的值 override def add(word:String): Unit = { val newCnt = wcMap.getOrElse(word,0L)+1 wcMap.update(word,newCnt) } // driver 合并多个累加器的结果 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { val map1 = this.wcMap val map2 = other.value map2.foreach{ case (word,count)=>{ val newCount = map1.getOrElse(word,0L)+count map1.update(word,newCount) } } } // 累加器结果 override def value: mutable.Map[String, Long] = { wcMap } } }
广播变量:分布式共享只读变量
1.可以解决join 性能太差问题。(字典的k-v )
import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable object SparkBC { def main(args:Array[String]):Unit={ //conf val conf = new SparkConf().setMaster("local").setAppName("deng") val sc = new SparkContext(conf) // join 会进行shuffle 性能差,可以考虑用map的方式 val rdd1= sc.makeRDD(List(("a",1),("b",3),("c",4))) val map = mutable.Map(("a",5),("b",1),("c",4)) rdd1.map { case(w,c)=>{ val nc = map.getOrElse(w,0) (w,(c,nc)) } }.collect().foreach(println) sc.stop() } }
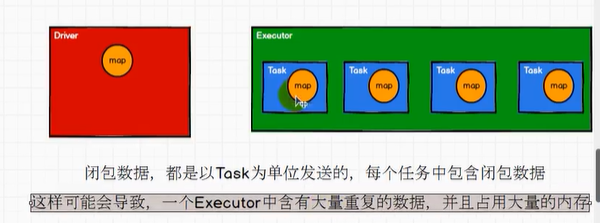
但闭包数据都是以task 为单位发送的,每个task 中都包含了一份闭包数据。闭包数据偏大或task 比较多时容易占用大量内存。
广播变量方式:
import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable object SparkBC { def main(args:Array[String]):Unit={ //conf val conf = new SparkConf().setMaster("local").setAppName("deng") val sc = new SparkContext(conf) // join 会进行shuffle 性能差,可以考虑用map的方式 val rdd1= sc.makeRDD(List(("a",1),("b",3),("c",4))) val map = mutable.Map(("a",5),("b",1),("c",4)) // 定义广播变量 val bc = sc.broadcast(map) rdd1.map { case(w,c)=>{ val nc = bc.value.getOrElse(w,0) (w,(c,nc)) } }.collect().foreach(println) sc.stop() } }
有疑问可以加wx:18179641802,进行探讨

 浙公网安备 33010602011771号
浙公网安备 33010602011771号