

请求限流
请求限流
开发高并发系统时,有三把利器用来保护系统:缓存、降级和限流
通过限流,我们可以很好地控制系统的qps,从而达到保护系统的目的。
计数算法(不常用)
// 模拟的伪代码
public static void main(String[] args) throws InterruptedException {
AtomicLong atomicLong = new AtomicLong(0L);
long interval = 1000;
long maxNums = 50;
String request = "/test/app";
long targetTime = System.currentTimeMillis();
int pass = 0;
int fail = 0;
for (int i = 0; i < 1000; i++) {
boolean response = getResponse(targetTime, interval, atomicLong, maxNums, request);
if (response) {
pass++;
} else {
fail++;
}
if (i == 200) {
Thread.sleep(1000);
}
}
System.out.println("Pass: " + pass + " fail: " + fail);
}
/***
* @param targetTime 请求时间
* @param interval 间隔时间
* @param atomicLong 计数器
* @param maxNums 最大请求量
* @param request 请求|模拟接口名
*
* 计数器算法 - 故名思意
* 通过一段时间内对指定接口进行计数,判断是否超过最大限制
*/
private static boolean getResponse (long targetTime, long interval, AtomicLong atomicLong, long maxNums, String request) {
long now = System.currentTimeMillis();
if (targetTime <= now && now <= targetTime + interval) {
long index = atomicLong.getAndAdd(1);
return index <= maxNums;
} else {
atomicLong.set(0L);
}
return true;
}
计数算法的实现和我们想当然的结果一致,比如 15s - 16s 这个区间,我们想当然的以某一次请求为起点,比如15s,则设置间隔为1秒,通过判断请求时间是否在 15 - 16 之间,如果在则累加,判断是否超过最大限制,不在则数据重置
但它存在的致命的问题即:
- 无法归纳出下一次请求对上一次请求的时间变化 这点是不合理的
- 由于原因1的影响,用户很有可能在 15.59999的极限请求100次,在16.00001的极限请求100次
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kgsS8g8P-1570515353938)(限流篇.assets/4f9b2b97db30494a5b2f0a1da9560451)]
因此: 计数算法存在严重的临界值问题,原因是由于计数依据 -> 时间导致的
滑动窗口(不常用)
滑动窗口的本质和计数一致,只不过通过把一个时间分区,即扩大精度,让请求数量的计算更加合理
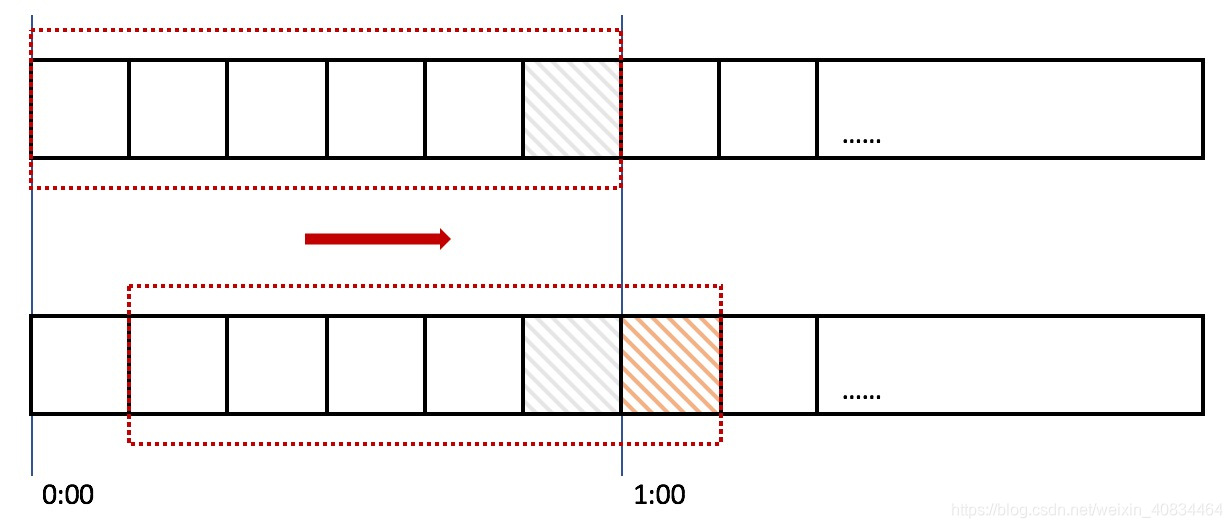
在上图中,整个红色的矩形框表示一个时间窗口,在我们的例子中,一个时间窗口就是一分钟。然后我们将时间窗口进行划分,比如图中,我们就将滑动窗口 划成了6格,所以每格代表的是10秒钟。每过10秒钟,我们的时间窗口就会往右滑动一格。每一个格子都有自己独立的计数器counter,比如当一个请求 在0:35秒的时候到达,那么0:30~0:39对应的counter就会加1。
那么滑动窗口怎么解决刚才的临界问题的呢?我们可以看上图,0:59到达的100个请求会落在灰色的格子中,而1:00到达的请求会落在橘黄色的格 子中。当时间到达1:00时,我们的窗口会往右移动一格,那么此时时间窗口内的总请求数量一共是200个,超过了限定的100个,所以此时能够检测出来触发了限流
漏桶算法
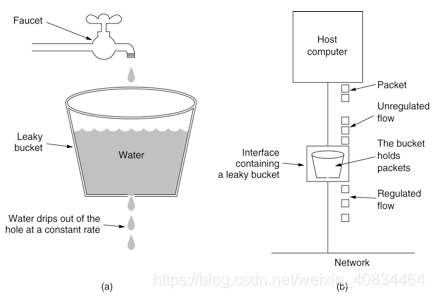
漏桶算法有两种实现:
一,不允许突发流量的情况,即以速率为标准是否进行限流
二, 允许突发流量的情况,即以容量为标准是否进行限流(
这样请求其实在等待,因此处理速率是定值,一般不采用)但无论啥哪种方式,漏水的速率是一定的,因此我们说 —》漏桶算法可以平滑网络上的突发流量(对于突发处理效率一般)
// 模拟的伪代码 -> 允许突发流量
public class LeakyBucket {
public static void main(String[] args) throws InterruptedException {
Integer pass = 0;
Integer fail = 0;
Bucket bucket = new Bucket();
bucket.start();
for (int i = 0; i < 100; i++) {
Integer num = Bucket.current;
if (num++ < Bucket.maxValue) {
Bucket.current++;
pass++;
} else {
fail++;
}
Thread.sleep(50);
}
System.out.println("Pass: " + pass + " fail: " + fail);
}
private static class Bucket extends Thread {
// 容量
private static Integer maxValue = 20;
// 速率 3次/s
private static Integer rate = 3;
// 当前量
private static Integer current = 0;
@Override
public void run() {
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (current > 0) {
current = Math.max(0, current -= rate);
}
}
}
}
}
令牌桶算法
和漏桶算法相反,令牌桶算法的本质是,有一个令牌的桶,以恒定的速率(变种算法也可以根据情况改变速率)往一个桶里面丢令牌,如果可以获取到令牌,则可执行,否则被限流等待
好处:可以很好的解决突发情况

轮子 -> Guava RateLimiter
<!-- guava库 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>27.0.1-jre</version>
</dependency>
// RateLimiter具有预消费的能力 -> 即可以一次性拿走超过当前最大令牌的数量,但是下次等待时间会额外增加
public class GuavaRateLimiter {
public static void main(String[] args){
// 线程池
ExecutorService exec = Executors.newCachedThreadPool();
// 速率是每秒只有3个许可
final RateLimiter rateLimiter = RateLimiter.create(3.0);
for (int i = 0; i < 100; i++) {
final int no = i;
Runnable runnable = () -> {
try {
//获取许可
rateLimiter.acquire();
System.out.println("Accessing: " + no + ",time:" + new SimpleDateFormat("yy-MM-dd HH:mm:ss").format(new Date()));
} catch (Exception e) {
e.printStackTrace();
}
};
//执行线程
exec.execute(runnable);
}
//退出线程池
exec.shutdown();
}
}
根据令牌桶算法,桶中的令牌是持续生成存放的,有请求时需要先从桶中拿到令牌才能开始执行,谁来持续生成令牌存放呢?
一种解法是,开启一个定时任务,由定时任务持续生成令牌。这样的问题在于会极大的消耗系统资源,如,某接口需要分别对每个用户做访问频率限制,假设系统中存在6W用户,则至多需要开启6W个定时任务来维持每个桶中的令牌数,这样的开销是巨大的。
另一种解法则是延迟计算,其实现思路为,若当前时间晚于nextFreeTicketMicros,则计算该段时间内可以生成多少令牌,将生成的令牌加入令牌桶中并更新数据。这样一来,只需要在获取令牌时计算一次即可
分布式限流
分布式环境下限流方案
如nginx 采取 hash ip策略,则用单机方式可以
如轮询策略,则可以借用第三方实现分布式限流,如 redis -> 基本思路即利用 lua 脚本,通过原子性的方式获取请求是否超过限制 lua脚本逻辑也很简单,即利用redis的 过期设置key-value
-- Demo: 下标从 1 开始
local key = KEYS[1]
local now = tonumber(ARGV[1])
local ttl = tonumber(ARGV[2])
local expired = tonumber(ARGV[3])
-- 最大访问量
local max = tonumber(ARGV[4])
-- 清除过期的数据
-- 移除指定分数区间内的所有元素,expired 即已经过期的 score
-- 根据当前时间毫秒数 - 超时毫秒数,得到过期时间 expired
redis.call('zremrangebyscore', key, 0, expired)
-- 获取 zset 中的当前元素个数
local current = tonumber(redis.call('zcard', key))
local next = current + 1
if next > max then
-- 达到限流大小 返回 0
return 0;
else
-- 往 zset 中添加一个值、得分均为当前时间戳的元素,[value,score]
redis.call("zadd", key, now, now)
-- 每次访问均重新设置 zset 的过期时间,单位毫秒
redis.call("pexpire", key, ttl)
return next
end
// 调用方法Demo 仅仅举例而已 对应上述lua脚本
private boolean shouldLimited(String key, long max, long timeout, TimeUnit timeUnit) {
// 最终的 key 格式为:
// limit:自定义key:IP
// limit:类名.方法名:IP
key = REDIS_LIMIT_KEY_PREFIX + key;
// 统一使用单位毫秒
long ttl = timeUnit.toMillis(timeout);
// 当前时间毫秒数
long now = Instant.now().toEpochMilli();
long expired = now - ttl;
// 注意这里必须转为 String,否则会报错 java.lang.Long cannot be cast to java.lang.String
Long executeTimes = stringRedisTemplate.execute(limitRedisScript, Collections.singletonList(key), now + "", ttl + "", expired + "", max + "");
if (executeTimes != null) {
if (executeTimes == 0) {
log.error("【{}】在单位时间 {} 毫秒内已达到访问上限,当前接口上限 {}", key, ttl, max);
return true;
} else {
log.info("【{}】在单位时间 {} 毫秒内访问 {} 次", key, ttl, executeTimes);
return false;
}
}
return false;
}
拓展
在接口请求时候,我们可以用上述的算法控制限流,在代码层,如批量生成excel文件等业务中,为了避免同一时间文件产生过多导致IO,CPU飙增,也可以用限流的思路,通过JUC的信号量控制线程的数量,达到类似限流的目的
参考博文
开源中国:https://segmentfault.com/a/1190000012875897
简书:https://www.jianshu.com/p/5d4fe4b2a726
掘金:https://juejin.im/post/5d8036a3e51d4561ff6668c3
GitHub:限流Demo
- https://github.com/xkcoding/spring-boot-demo?utm_source=gold_browser_extension
- https://github.com/kkzhilu/KerwinBoots/tree/boot_ratelimit_guava

 浙公网安备 33010602011771号
浙公网安备 33010602011771号