

Cache缓存设计
缓存的适用场景:
缓存的目的是提高访问速度,减少不必要的开销,提高性能。那什么样的场景适用于缓存呢。试想一个多项式的计算是一个CPU bound的操作,如果频繁调用同一个多项式的结果。显然缓存结果是一个提高性能的方法。减少了不必要的CPU开销。另外就是提高访问速度。启动的时候,需要加载DB的数据到内存,如果有cache,那么重复get的时候,会优先从缓存获取。显然内存比走IO的db快。
并不是所有的数据都应用于缓存。经常更新的data就不适用于缓存。因为IO的开销没有减少。还要多出维护缓存的额外开销,另外要求强一致的系统也不能使用缓存,因为除非采用P2C,缓存和DB的之间不一致无法避免。
缓存的分类:
- 本地缓存(LRU,hashmap实现的cachebase类)
- 分布式缓存(Redis等)
两者的区分:
- 最重要的是本地缓存在多线程环境中,需要加锁,防止线程竞争. 缓存类的线程安全不同于STL中容器线程安全,因为缓存类提供的接口有限get,delete,set,可以内部封装缓存容器类。缓存单元无需提供线程安全. leveldb中类
LRUCache是一个缓存管理容器,需要提供线程安全,缓存的单元是LRUHandle,无需线程安全. 注意加锁mutex需要会影响性能,但是多线程加锁影响性能的关键是锁的竞争,所以要减少锁的粒度,由此减少竞争的概率.提高性能.Redis 本身是单线程的,所以天然线程安全. - redis支持水平拓展scale up,如果缓存内存过大,可以增加redis cluster模式。而本地内存仅限于单个应用。由于redis支持高可用,本地缓存不支持. 持久化的可以使down 机之后快速热启动. redis的数据结构丰富,针对不同的场景,应用不同类型的数据结构,本地缓存需要自己实现各个场景的cachebase基类.
- 本地缓存需要自己设计多缓存之间相互通知缓存更新的功能。redis天然支持,因为大家共用一份缓存。
- 都无法保证事务.
常见的缓存设计:
1. 本地缓存和DB 2.Redis和DB 3.多层缓存设计(本地缓存,Redis ,DB)
关键问题点:缓存过期的支持,缓存淘汰的支持,缓存更新通知机制的支持。缓存过期就是设置过期时间。每次get缓存的时候,如果超过过期时间,就把缓存删除,这是缓存的惰性删除。还有定期删除,和定时删除,定时删除最为精确,设置定时器,只要缓存过去就能快速的删除,但是需要检测,开销大。redis采用惰性和定期删除的策略。缓存过期的作用结果就是删除过期缓存,节省内存。还有一个关键的作用是让缓存失效。用于保证最终一致性。试想,如果db和redis的数据总是不一致,那么应该怎么办?根据一致性的需求,我们可以提出两个策略:1.一定时间内,一致性得到解决,通过定期去比较db version和redis version. 2.时间不确定,但是可以保证最终一致性。我们设置缓存过期时间。一旦缓存过期,就会删除内存。然后从db取最新的数据.
缓存淘汰的目的更多是在于保证缓存系统在内存不足的条件下能够继续使用。最后是多个缓存之间的更新通知机制,这个保证多缓存之间的一致性。
缓存更新通知机制:
本地缓存如果detect到其他缓存导致的db更新?这需要引入version版本号的概念。cachebase中维护一个m_version的成员变量,代表此id的cache的版本号,同时本地维护一个所有caches的map<id,counter>结构,id表示cache,counter表示版本。这个map更新时机有两处,1. 如果本地cache更新之后,需要increaseCounter那么这个map更新为最新的db值, 2,如果上次更新已经过了T时间,那么也会更新db最小值。 也就是说如果不是本地cache更新,那么map与DB的数据有T时间的mismatch。
m_version在每次getcacheObject的时候比较m_vesion与map[id]是否相等,如果不想等,就应该refresh缓存,从db加载最新的data到本地缓存。如此就实现了本地缓存监测由其他缓存导致的db更新。
关键点:要维护一个version_num的概念。且要考虑多进程条件下,多个本地缓存同时写的情况。因此increaseCounter函数是增加版本号,一定会取db最新的值加1。同时多进程同时写DB的顺序问题有数据库本身处理,可以实现sequence 访问,无需程序员考虑.如果两个进程同时写同一个db table且写入值相同,那么可以让后来的写入失败。
多级缓存的设计:
加入redis作为二级缓存,就构成二级缓存的系统,本地缓存和redis缓存,DB三者的同步更新更加复杂。因为db和redis之间的无法保证事务,需要分布式事务。副作用比本地和db之间大。缓存更新的策略通常包两种情况:
- 先删除缓存,再更新数据库。
- 先更新数据库,再删除缓存。 这两种情况在业界,大家对其都有自己的看法。具体怎么使用还得看各自的取舍。当然肯定会有人问为什么要删除缓存呢?而不是更新缓存呢?你可以想想当有多个并发的请求更新数据,你并不能保证更新数据库的顺序和更新缓存的顺序一致,那就会出现数据库中和缓存中数据不一致的情况。所以一般来说考虑删除缓存。
- 如果采用redis version和db version的策略,那么就可以用更新db,更新redis的策略,因为可以定期通过版本号保证一致性,毕竟之前的策略只是降低不一致性的可能性,但是不能完全避免。需要兜底,要么定期过期,要么通过version扫表
一种设计:
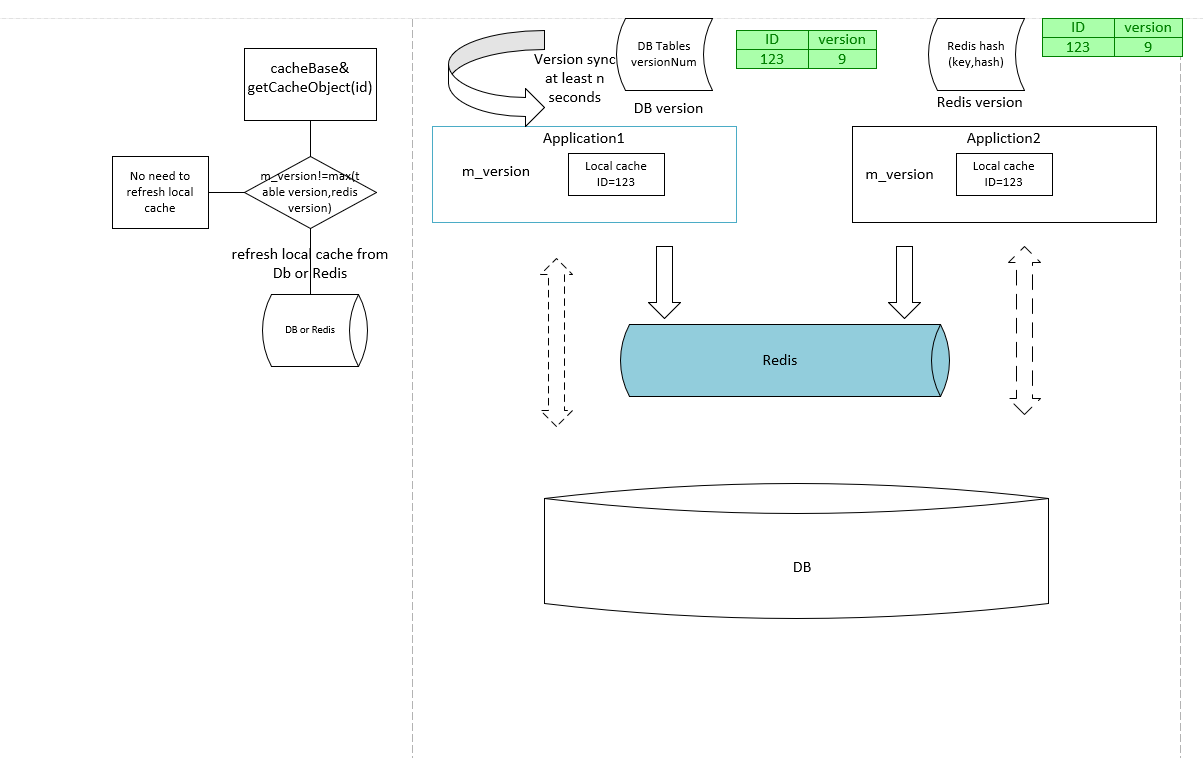
更新的步骤:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号