数据采集第三次作业
作业1:单线程/多线程爬取网站图片
单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.parse
import urllib.request
def imageSpider(start_url):
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.parse.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err1:
print(err1)
except Exception as err2:
print(err2)
def download(url):
global count
try:
count += 1
if url[len(url) - 4] == ".":
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/data/file2/"+str(count)+ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(count)+ext)
except Exception as err3:
print(err3)
start_url = "http://www.weather.com.cn"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"
}
count = 0
imageSpider(start_url)
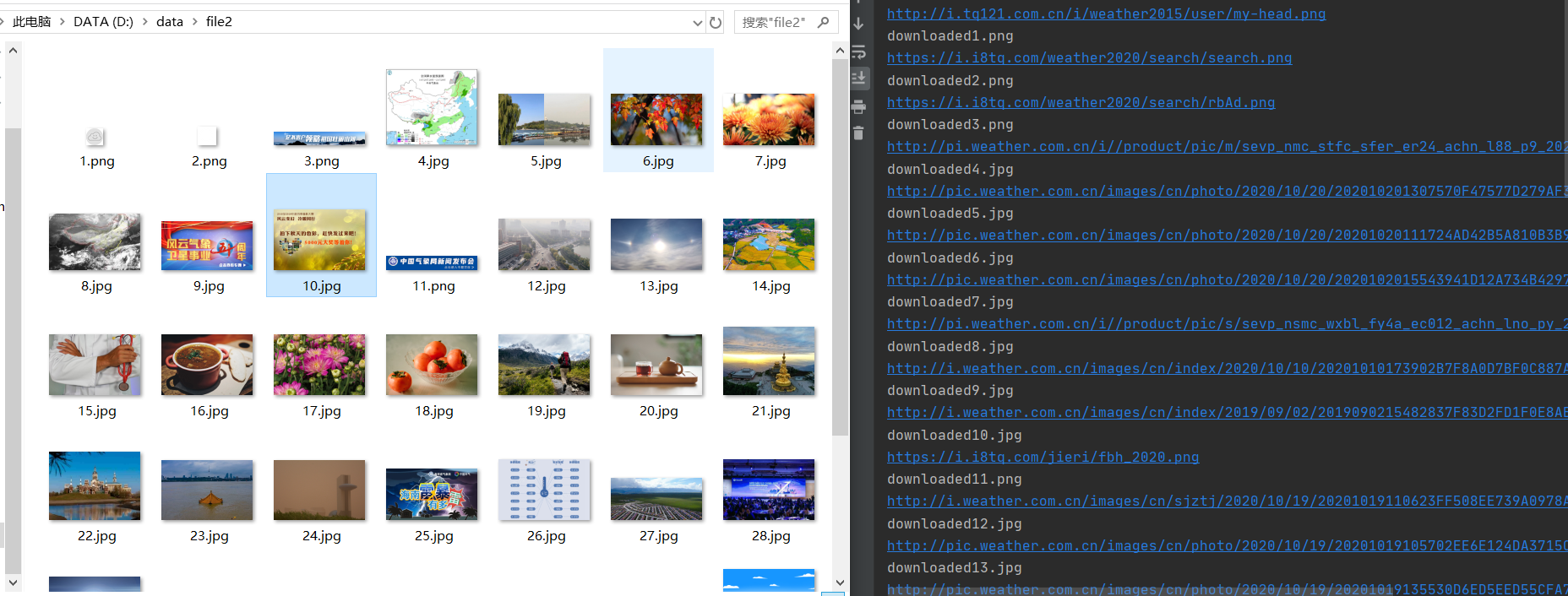
多线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import urllib.parse
import threading
def imageSpider(start_url):
global threads
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.parse.urljoin(start_url, src)
if url not in urls:
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url, count):
try:
if url[len(url)-4] == ".":
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/data/file2/"+str(count)+ext, "wb")
fobj.write(data)
fobj.close()
print("doenloaded"+str(count)+ext)
except Exception as err:
print(err)
start_url = "http://www.weather.com.cn"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"
}
count = 0
threads = []
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
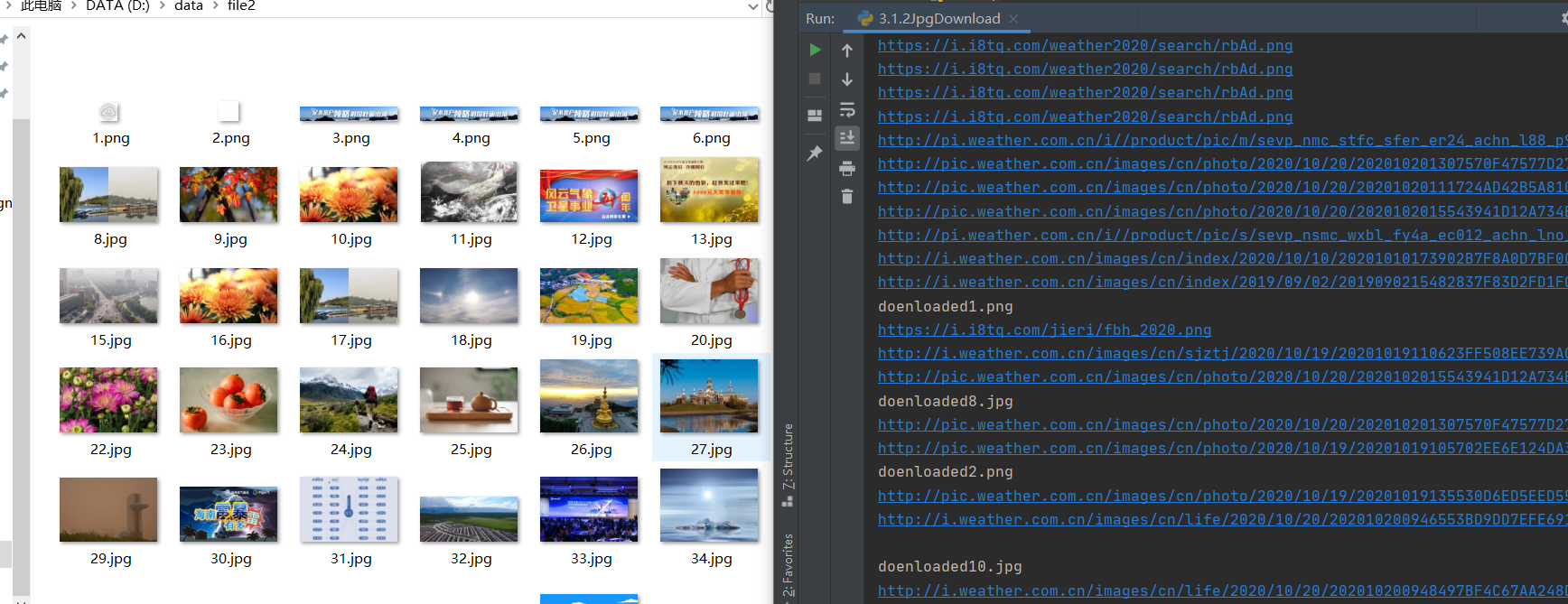
心得体会:
首次进行单线程与多线程的操作,因为图片的数量不是很多,所以两个代码运行速度都差不多,但是可以从控制台结果很直观的看出来,多线程运行下,下载完成的图片是乱序,说明图片是同时进行下载的。
作业2:scrapy框架对作业1的复现
代码:
jpgDownload
import scrapy
from ..items import Pro2Item
class JpgdownloadSpider(scrapy.Spider):
name = 'jpgDownload'
# allowed_domains = ['www.baidu.com.io']
start_urls = ['http://www.weather.com.cn']
def parse(self, response):
try:
src_list = response.xpath("//img/@src").extract()
for src in src_list:
item = Pro2Item()
item['url'] = src
print(src)
yield item
except Exception as err:
print(err)
items
import scrapy
class Pro2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
pass
pipelines
import urllib
class Pro2Pipeline:
count = 0
def process_item(self, item, spider):
try:
url = item["url"]
Pro2Pipeline.count += 1
if url[len(url) - 4] == ".":
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:/data/file1/" + str(Pro2Pipeline.count) + ext, "wb")
fobj.write(data)
fobj.close()
except Exception as err:
print(err)
return item
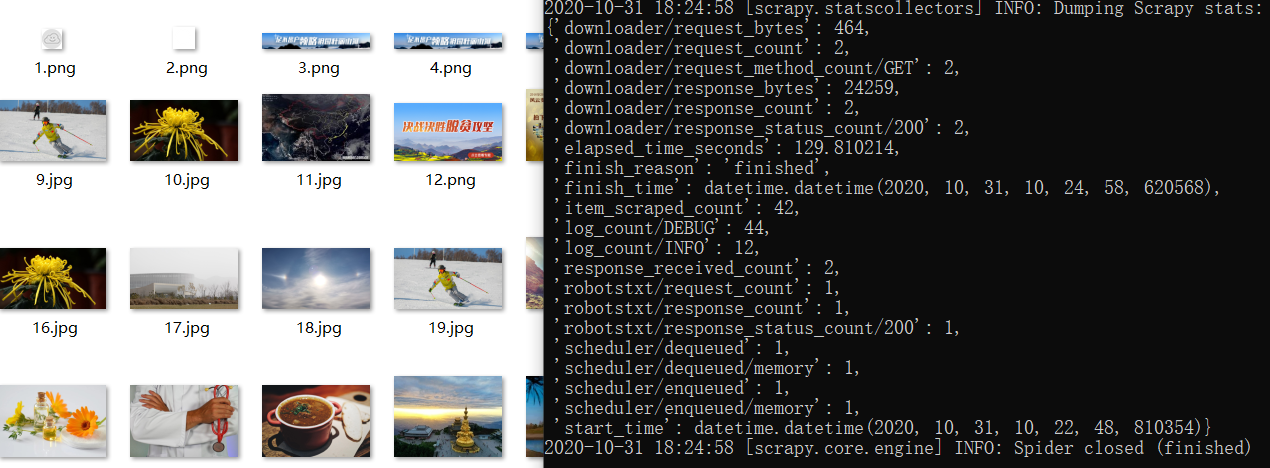
心得体会
对这次作业感受最深的就是框架的使用了,和以往的作业不同,不能直接调用库,要在命令行进行爬虫的创建及运行。
作业3:scrapy框架爬取股票相关信息
代码:
stock
import scrapy
import re
from ..items import Pro1Item
from ..pipelines import Pro1Pipeline
class StockSpider(scrapy.Spider):
name = "stock"
def start_requests(self):
url = 'http://77.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124041523442512990894_1603196582234&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1603196582235'
# 在url中pn参数是第i页,pz参数是返回i条股票信息,f2:"最新报价"f3:"涨跌幅"f4:"涨跌额"f5:"成交量"f6:"成交额"f7:"振幅"f12:"股票代码"f14:"股票名称"f15:"最高"f16:"最低"f17:"今开"f18:"昨收"
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
data = response.text
data = re.findall(r'"diff":\[(.*?)]', data)
# 将data中的不同股票的信息划分开来
datas = data[0].strip('{').strip('}').split('},{')
for i in datas:
item = Pro1Item()
# f12:代码,f14:名称,f2:最新价,f3:涨跌幅,f4:跌涨额,f5:成交量,f6:成交额,f7:涨幅,f15:最高,f16:最低,f17:今开,f18:昨收
array = i.split(",")
item["id"] = array[6].split(":")[1]
item["name"] = array[7].split(":")[1]
item["new_price"] = array[0].split(":")[1]
item["extent"] = array[1].split(":")[1]
item["change_price"] = array[2].split(":")[1]
item["number"] = array[3].split(":")[1]
item["money"] = array[4].split(":")[1]
item["promote"] = array[5].split(":")[1]
item["highest"] = array[8].split(":")[1]
item["lowest"] = array[9].split(":")[1]
item["today_begin"] = array[10].split(":")[1]
item["yesterday_over"] = array[11].split(":")[1]
yield item
print(Pro1Pipeline.tb)
pipelines
import prettytable as pt
class Pro1Pipeline:
count = 0
tb = pt.PrettyTable(["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"])
def process_item(self, item, spider):
Pro1Pipeline.count += 1
Pro1Pipeline.tb.add_row(
[Pro1Pipeline.count, item["id"], item["name"], item["new_price"], item["extent"], item["change_price"],
item["number"], item["money"], item["promote"], item["highest"], item["lowest"], item["today_begin"],
item["yesterday_over"]])
return item
items
import scrapy
class Pro1Item(scrapy.Item):
id = scrapy.Field()
name = scrapy.Field()
new_price = scrapy.Field()
extent = scrapy.Field()
change_price = scrapy.Field()
number = scrapy.Field()
money = scrapy.Field()
promote = scrapy.Field()
highest = scrapy.Field()
lowest = scrapy.Field()
today_begin = scrapy.Field()
yesterday_over = scrapy.Field()
pass

心得体会
Scrapy 框架就像是一个已经写好的方法,只需要我们输入参数(url,需要输出的内容这些)就能很方便的运行出结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号