MySQL性能优化之 - 单表查询+代码层拼接 VS 表连接查询
单表查询+代码端拼接的优势
记得当初单位派我去阿里交流学习时,人家就说,在阿里,95%以上的查询都是单表查询,虽然我们都知道单表查询更加符合MySql底层的算法逻辑,但是单表查询+代码端拼接的优势究竟是什么,它为什么互联网企业都会使用单表查询呢?归纳而言大体分以下几点:
1. 激活代码端和数据库缓存
首先是代码端缓存,各位小伙伴应该都知道,在 .NET 框架中有很多ORM框架,比如我们最熟悉的EFCore就是其中的佼佼者。我们在使用它对数据库进行查询时,如果单条数据没有发生变化,那么此时就会使用EFCore的缓存来返回查询结果。MySQL也有自己的缓存机制。但是一旦数据发生了变化,则不能再使用之前的缓存。而由于表连接查询可能会一次性关联多张表,只要其中一张表发生变化,那么整个缓存就将失效。如果是分步的单表查询,显然更容易触发缓存。
2. 避免“一锁具锁”的情况
在数据库中会有一种叫做锁竞争的东西存在,如果我们做了表连接查询,那么只要其中任意一个表被锁,那么整个查询都将出现问题。反之单表查询可以最大限度的避免出现“一锁具锁”的情况。
3. 减少MySql的哈希关联
在MySql大致有两种索引方式,一种叫做BTree(其实是B+树的进化版,统称BTree),这种形式的索引非常利于范围查询的优化,这里有机会我们课上细聊。
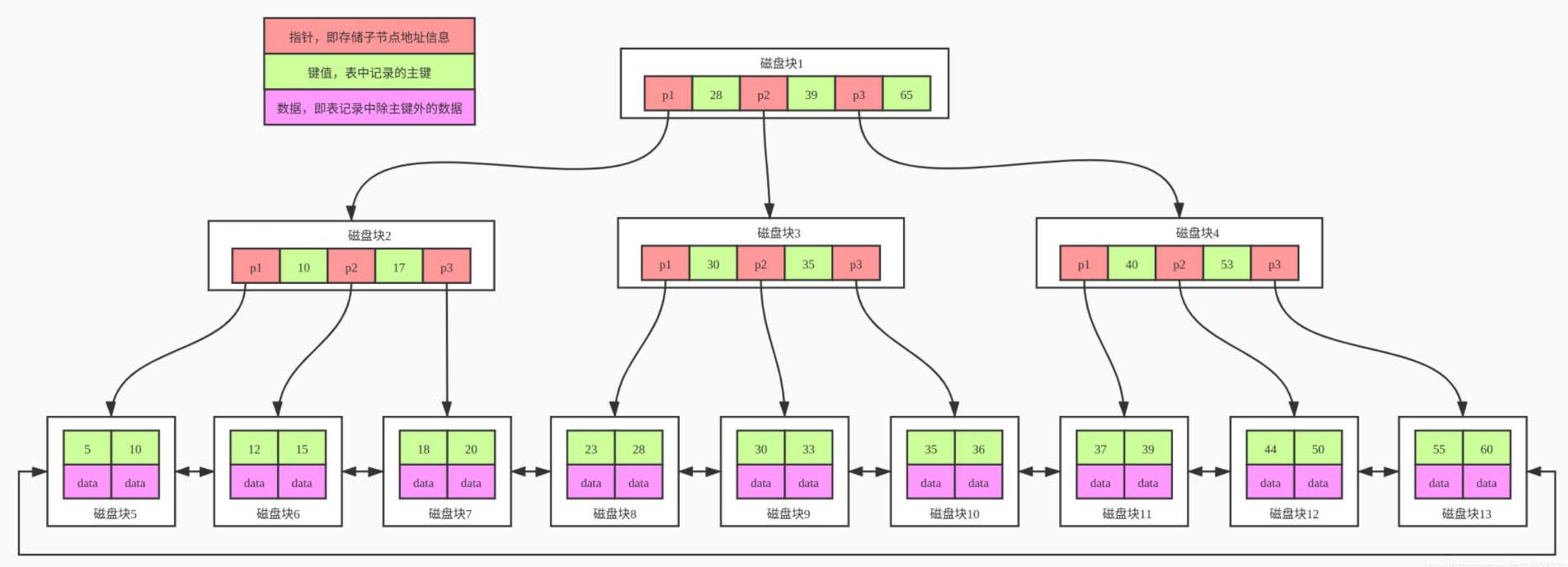
那么还有一种方式叫做Hash,这种方式适合单个数据查询,而不适合连续查询,对于查询效率会产生一定的影响
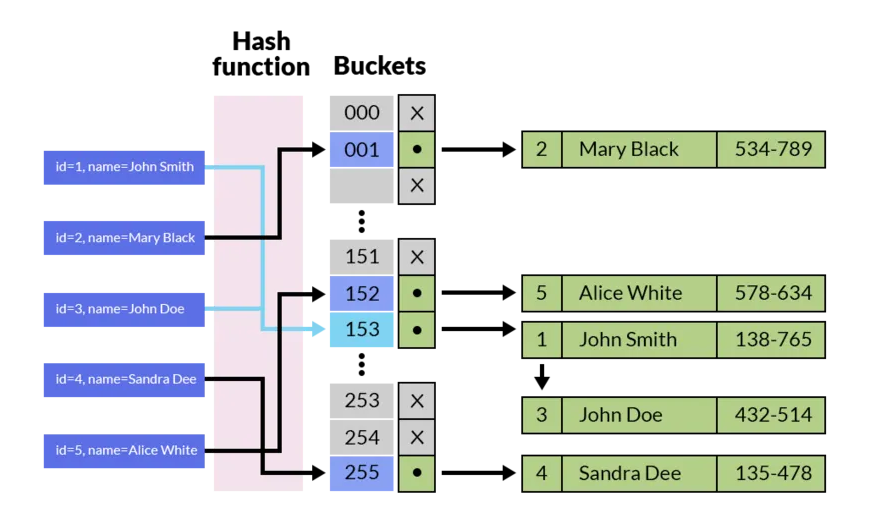
我们知道,就算要使用表连接查询,阿里也有硬性要求,就是必须要走索引,那么这样做相当于在应用中实现了哈希关联,而不是在MySQL中进行的嵌套循环连接,效率会更高。
4. 提高代码复用
除了以上数据库本身的原因,在开发过程中,单表的查询可以被多次重复使用。
5. 更加符合DDD思想开发
现阶段由于微服务架构大行其道,与之相应的DDD领域驱动思想也颇为热门。在DDD领域驱动思想中就有一个聚合根的概念,此时我们可以利用领域服务获取关联数据,再以领域事件聚合数据。
这里还缺少一个连表查询时,会产生笛卡尔积的消耗,这个中间结果集对大数据集很不友好,分分钟干爆你的内存;
不使用join的条件之一,就是大数据集千万不要用,还有存在分库分表的时候,如果你有这种想法,看大佬怎么收拾你;
不使用join的原因和好处:
1、降低MySQL优化器的负担,可以让优化过程快速收敛;
2、SQL简单,便于优化,更好的命中索引;
3、查询数据集小,便于缓存(包括数据库、ORM)
4、由于有缓存,可以减少磁盘IO
5、一个东西修改的概率可能不是很高,一堆东西修改的概率相对来讲会高一些,数据一旦修改,缓存就没有意义了;
6、复杂SQL容易满足死锁条件,造成不同的SQL锁定资源的循序不一致,且执行时间长,死锁的概率相对较高,尽量要做到轻量、无锁并发;
7、由于简单、标准,很多地方可以重复使用,避免重复造轮子,这种精华部分可以交给大佬处理;
8、所有的一切都是可控,且性能输出稳定;
9、数据库是所有系统的瓶颈,需要保证数据库高频低延时的对外稳定输出,就像Redis我们通常不希望有大key,不希望使用模糊匹配一样;
10、方便数据异构、迁移、拆分,不会因为这些操作而导致系统不正常;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号