Es分词过程
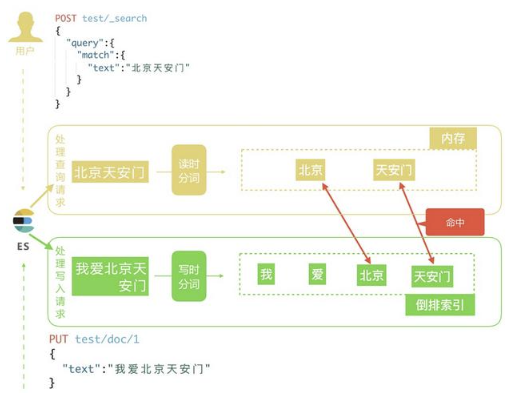
ES 的分词不仅仅发生在文档创建的时候,也发生在搜索的时候
查询:
- 读时分词发生在用户查询时,ES 会即时地对用户输入的关键词进行分词,分词结果只存在内存中,当查询结束时,分词结果也会随即消失。
添加:
- 而写时分词发生在文档写入时,ES 会对文档进行分词后,将结果存入倒排索引,该部分最终会以文件的形式存储于磁盘上,不会因查询结束或者 ES 重启而丢失。
ES中存储上表中的数据,ES会创建以下的索引
| Term | Posting List |
|---|---|
| hjx | 1 |
| Bob | 2 |
| Alan | 3 |
| 24 | [1,2] |
| 26 | 3 |
| 男 | 1 |
| 女 | [2,3] |
Term是字段值,Posting List是其所属的id数组
(21条消息) ES 索引_es索引_萝卜7的博客-CSDN博客
ES在构建时,会为每个字段构建倒排索引 ---- 其中只有text类型字段 会为其分词
现有索引和映射如下:
{
"products" : {
"mappings" : {
"properties" : {
"description" : {
"type" : "text"
},
"price" : {
"type" : "float"
},
"title" : {
"type" : "keyword"
}
}
}
}
}
先录入如下数据,有三个字段title、price、description等
| _id | title | price | description |
|---|---|---|---|
| 1 | 蓝月亮洗衣液 | 19.9 |
蓝月亮洗衣液很高效 |
| 2 | iphone13 | 19.9 |
很不错的手机 |
| 3 | 小浣熊干脆面 | 1.5 | 小浣熊很好吃 |
在ES中除了text类型分词,其他类型不分词,因此根据不同字段创建索引如下:
title字段:
| term | _id(文档id) |
|---|---|
| 蓝月亮洗衣液 | 1 |
| iphone13 | 2 |
| 小浣熊干脆面 | 3 |
price字段
| term | _id(文档id) |
|---|---|
| 19.9 | [1,2] |
| 1.5 | 3 |
description字段
| term | _id | term | _id | term | _id |
|---|---|---|---|---|---|
| 蓝 | 1 | 不 | 2 | 小 | 3 |
| 月 | 1 | 错 | 2 | 浣 | 3 |
| 亮 | 1 | 的 | 2 | 熊 | 3 |
| 洗 | 1 | 手 | 2 | 好 | 3 |
| 衣 | 1 | 机 | 2 | 吃 | 3 |
| 液 | 1 | ||||
| 很 | [1:1:9,2:1:6,3:1:6] | ||||
| 高 | 1 | ||||
| 效 | 1 |
注意: Elasticsearch分别为每个字段都建立了一个倒排索引。因此查询时查询字段的term,就能知道文档ID,就能快速找到文档。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号