容器的隔离(namespace)与资源限制(cgroups)
1. 什么是容器
简单来说,容器其实是一种沙盒技术。顾名思义,沙盒就是能够像一个集装箱一样,把你的应用“装”起来的技术。这样,应用与应用之间,就因为有了边界而不至于相互干扰;而被装进集装箱的应用,也可以被方便地搬来搬去。
想要理解容器,有必要先回顾一下进程相关的基础知识。
对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。
而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。其中,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
2. Namespace 隔离
Linux Namespace是Linux提供的一种内核级别环境隔离的方法。Linux内核中提供了6种namespace隔离的系统调用,如下所示:(官方文档在这里Namespace in Operation)
| namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTS | CLONE_NEWUTS | 主机名与域名 |
| IPC | CLONE_NEWIPC | 信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID | 进程编号 |
| Network | CLONE_NEWNET | 网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS | 挂载点(文件系统) |
| User | CLONE_NEWUSER | 用户和用户组 |
该部分理解起来比较抽象,最好的方法就是写代码感受一下。
推荐耗子叔的这两篇博文,跟着走一遍就会有比较直观的感受。不再赘述。
3. Cgroups 资源限制
通过linux namespace,我们已经能够创建出一个资源隔离的进程了,也就是所谓的“容器”,但这个“容器”尚不完整,还需要对其进行资源限制。为什么呢?这里通过PID namespace为例进行说明。
虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是从宿主机的角度来看,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
Linux Cgroups 就是 Linux内核中用来为进程设置资源限制的一个重要功能,其全称是Linux Control Groups的简称,通过man cgroups命令,可以看到其标准定义:
Control cgroups, usually referred to as cgroups, are a Linux kernel feature which allow processes to be organized into hierarchical(分层的) groups whose usage of various types of resources can then be limited and monitored. The kernel's cgroup interface is provided through a pseudo-filesystem called cgroupfs.
Grouping is implemented in the core cgroup kernel code, while resource tracking and limits are implemented in a set of per-resource-type subsystems (memory, CPU, and so on).
简单来说,其主要作用就是:
限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
此外,Cgroups 还能够对进程进行优先级设置、审计,以及将进程挂起和恢复等操作。本文重点探讨它与容器关系最紧密的“限制”能力,并通过一组实践来认识一下 Cgroups。
在实践之前,再了解两个概念,即控制组(group)和子系统(subsystem),其定义同样可以通过man cgroups进行查看,这里摘录如下:
- group:A cgroup is a collection of processes that are bound to a set of limits or parameters defined via the cgroup filesystem.
- subsystem:A subsystem is a kernel component that modifies the behavior of the processes in a cgroup. Various subsystems have been implemented, making it possible to do things such as limiting the amount of CPU time and memory available to a cgroup, accounting for the CPU time used by a cgroup, and freezing and resuming execution of the processes in a cgroup. Subsystems are sometimes also known as resource controllers (or simply, controllers).
一个“控制组”就是一组绑定在一起的进程的集合,通过cgroup文件系统限定资源或参数;而“子系统”就是所谓的“cgroup文件系统”,用来限定“控制组”内进程的资源。这两者是彼此协作的概念。
在Linux中,Cgroups实际就是以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下,可以通过 mount 命令把它们展示出来,如下:
root@ubuntu:~# mount -t cgroup
...
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/hugetlb type cgroup (rw,nosuid,nodev,noexec,relatime,hugetlb)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
...
它的输出结果,是一系列文件系统目录。可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,这也就是上面提到的子系统(subsystem)。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,就可以看到该类资源具体可以被限制的方法。比如:
root@ubuntu:~# ls /sys/fs/cgroup/cpu
cgroup.clone_children cpuacct.usage_percpu cpu.cfs_quota_us system.slice
cgroup.procs cpuacct.usage_percpu_sys cpu.shares tasks
cgroup.sane_behavior cpuacct.usage_percpu_user cpu.stat user.slice
cpuacct.stat cpuacct.usage_sys docker
cpuacct.usage cpuacct.usage_user notify_on_release
cpuacct.usage_all cpu.cfs_period_us release_agent
比如这两个参数cfs_quota_us和cfs_period_us,它表示的意思是:限制进程在长度为cfs_period_us的一段时间内,只能被分配到总量为cfs_quota_us的CPU时间。
默认情况下,这两个参数的值如下,-1表示没有任何限制,cfs_quota_us和cfs_period_us的单位是us。
root@ubuntu:~# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1 // 没有限制
root@ubuntu:~# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000 // 即100ms
也就是说,默认情况下,任何一个线程在 100ms 的时间周期内,「最多」能被分配到的CPU时间就是 100ms,不会被限制。
那么这些配置文件该如何使用呢?怎样才能真正实现“限制”的效果呢?接下来真正的进入实验。
首先,在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
root@ubuntu:/sys/fs/cgroup/cpu# mkdir fake-container
root@ubuntu:/sys/fs/cgroup/cpu# ls fake-container/
cgroup.clone_children cpuacct.usage_percpu_sys cpu.shares
cgroup.procs cpuacct.usage_percpu_user cpu.stat
cpuacct.stat cpuacct.usage_sys notify_on_release
cpuacct.usage cpuacct.usage_user tasks
cpuacct.usage_all cpu.cfs_period_us
cpuacct.usage_percpu cpu.cfs_quota_us
可以看到,操作系统会在新创建的 fake-container目录下,自动生成该子系统对应的资源限制文件。还是以上面说的那两个参数为例,现在该目录下,该参数的值还是默认的:
root@ubuntu:/sys/fs/cgroup/cpu/fake-container# cat cpu.cfs_quota_us
-1
root@ubuntu:/sys/fs/cgroup/cpu/fake-container# cat cpu.cfs_period_us
100000
现在在后台执行这样一条脚本:
root@ubuntu:~# while : ; do : ; done &
[1] 9195
显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%,根据它的输出,我们可以看到这个脚本在后台运行的进程号(PID)是 9195。通过 top 指令确认:
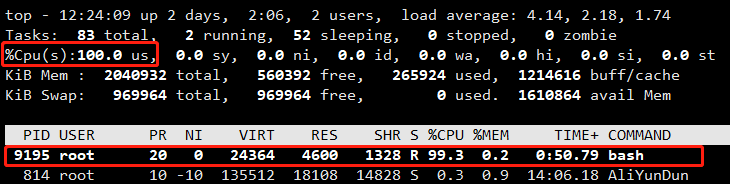
在输出里可以看到,CPU 的使用率已经 100% 了(%Cpu0 :100.0 us),并且主要就是被 PID=9195 这个进程吃掉的。
接下来,我们修改 fake-container 组里的 cfs_quota 文件,操作如下:
root@ubuntu:/sys/fs/cgroup/cpu# echo 20000 > fake-container/cpu.cfs_quota_us
这个操作的意义表示:在每 100 ms 的时间里,被该控制组限制的进程只能使用 20 ms 的 CPU 时间,也就是说这个进程「最多」只能使用到 20% 的 CPU 带宽。
接下来,把被限制的进程 PID 写入 fake-container 这个控制组的tasks文件里,即:
root@ubuntu:/sys/fs/cgroup/cpu# cat fake-container/tasks // 默认该文件是空的
root@ubuntu:/sys/fs/cgroup/cpu# echo 9195 > fake-container/tasks // 把被限制的进程PID写进去
这样一来,对该进程的限制就会生效了,通过 top 命令查看,发现CPU的使用率立刻下降到了 20%,如下图所示:
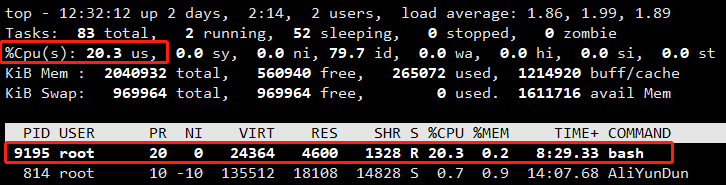
以上就是通过cgroup进行资源限制的简单实践。
当然,除了 CPU 子系统用于限制 CPU 的使用之外,还有许多其他子系统对各种资源进行限制,这些子系统均在 /sys/fs/cgroup 目录下:
root@ubuntu:/sys/fs/cgroup# ls
blkio cpuacct cpuset freezer memory net_cls,net_prio perf_event rdma unified
cpu cpu,cpuacct devices hugetlb net_cls net_prio pids systemd
其中:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,在多核机器上设置cgroup进程可以使用的CPU和内存;
- memory,为进程设定内存使用的限制。
- ...
通过实验我们基本了解了使用 Linux Cgroups 进行资源限制的原理,对于 Docker 项目而言,只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
$ docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash
在启动容器之后,可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_period_us
100000
$ cat /sys/fs/cgroup/cpu/docker/5d5c9f67d/cpu.cfs_quota_us
20000
(全文完)
参考&推荐阅读:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号