


数据挖掘学习笔记
数据挖掘常用分析方法:
最近团队需要招数据挖掘工程师,但公司之前没有相关的岗位。领导让我临时充当面试官对应聘者进行技术考核,为了做好这事情,我花了点时间了解了一下数据挖掘的知识,并整理了这份资料。
数据挖掘的分析方法可以划分为关联分析、序列模式分析、分类分析和聚类分析四种。
关联分析:
关联分析是一种简单、实用的分析技术,就是发现存在于大量数据集中的关联性或相关性,从而描述了一个事物中某些属性同时出现的规律和模式。
关联分析是从大量数据中发现项集之间有趣的关联和相关联系。
关联分析的一个典型例子是购物篮分析。该过程通过发现顾客放入其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
可从数据库中关联分析出形如“由于某些事件的发生而引起另外一些事件的发生”之类的规则。如“67%的顾客在购买啤酒的同时也会购买尿布”,因此通过合理的啤酒和尿布的货架摆放或捆绑销售可提高超市的服务质量和效益。又如“‘C语言’课程优秀的同学,在学习‘数据结构’时为优秀的可能性达88%”,那么就可以通过强化“C语言”的学习来提高教学效果。
关联分析->相关性分析->回归分析
关联分析常用算法有:
简单介绍Apriori算法
Apriori算法常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合。
通过找出的数据集合,可以对人类商业决策进行指导。典型应用例子:超市购物的啤酒与尿布销售关系。
Apriori算法基本思想是对各种数值进行组合,计算其共同出现概率。但其中增加了迭代,截枝思想,大大减少组合计算次数,在海量数据的情况下依然可以保证足够高的计算效率。

序列模式:
所谓序列模式,我的定义是:在一组有序的数据列组成的数据集中,经常出现的那些序列组合构成的模式。跟我们所熟知的关联规则挖掘不一样,序列模式挖掘的对象以及结果都是有序的,即数据集中的每个序列的条目在时间或空间上是有序排列的,输出的结果也是有序的。
举个简单的例子来说明,关联规则一个经典的应用是计算超市购物中被共同购买的商品,它把每个顾客的一次交易视作一个transaction,计算在不同transaction中不同item组合的规律性。而如果我们考虑一个用户多次在超市购物的情况,那么这些不同时间点的交易记录就构成了一个购买序列,N个用户的购买序列就组成一个规模为N的序列数据集。考虑这些时间上的因素之后,我们就能得到一些比关联规则更有价值的规律,比如关联挖掘经常能挖掘出如啤酒和尿布的搭配规律,而序列模式挖掘则能挖掘出诸如《育儿指南》->婴儿车这样带有一定因果性质的规律。所以,序列模式挖掘比关联挖掘能得到更深刻的知识。
序列模式挖掘常用算法有:
GSP算法,SPADE算法,PrefixSpan算法,Clospan算法等
分类分析:
分类是基于包含其类别成员资格已知的观察(或实例)的训练数据集来识别新观察所属的一组类别(子群体)中的哪一个的问题。例如,将给定的电子邮件分配给“垃圾邮件”或“非垃圾邮件”类,并根据观察到的患者特征(性别,血压,某些症状的存在或不存在等)为给定患者分配诊断。分类分析,简单地说就是把数据分成不同类别。
分类分析常用算法:
决策树,神经网络,贝叶斯分类,k最近邻分类(即KNN,见后面异常数据挖掘)
聚类分析:
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
聚类分析跟分类分析区别是分类分析需要有已有标签的数据,而聚类分析则不需要。
聚类分析常用算法:
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用随机林林,k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。
简单介绍k-means(k均值):

异常数据:
异常数据挖掘是数据挖掘中一种常用的场景,异常数据一般是指在总体样本中占比较小的数据。
根据应用场景不同也称错误数据,特殊数据,重要数据,高价值数据等。
异常数据挖掘常用方法有:
基于规则
规则有特定场景的业务规则:
例如某个字段取值必须为0
冬天气温肯定不能高于40度
也有通用的自然规则:
例如本福德定律(自然生成的数字首位为1的概率为30.10%,2的概率为17.61%,依次递减,首位为9的概率仅为4.58%。)。
基于统计方法
简单统计规则:观察其方差、标准差、均值等是否和常规值有所差异
正态分布规则:找出数据集里面不符合正态分布的数据
离群点检测算法
1 KNN
人们常说“想知道自己是什么人,看看与自己关系最亲密的十个人是什么人就知道”,意思是人总是会跟相似的人交朋友。
那反过来,要将某个人归类,则看他跟什么人接触比较多,则将全归到那一类里面。
knn算法是基于这个原理的分类算法,预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
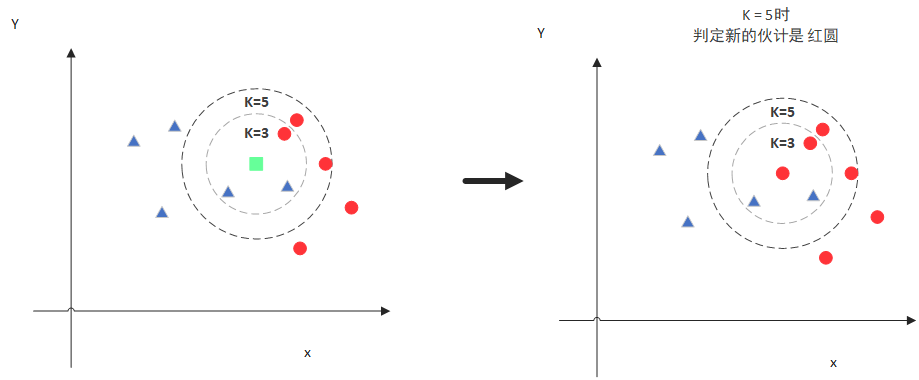
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点,看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
假设K=5。那么KNN算法就会找到与它距离最近的五个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是红色多一些,新来的绿色点就归类到红色球了。
此类算法需要有现成的异常数据样本,属于有监督机器学习。算法主要难点在于怎么定义数据距离还有k值取值(太小和太大的k值都会造成比较大的误差)
2 孤立森林
森林里面的树木一般是连成一片的,如果某一棵树跟其它树木不在一块,那这棵树一般有问题。
如何找出这样树呢?数据量少时可以通过可视化展示, 由人工判断。但数据量多时就比较麻烦。
孤立森林算法原理,就是逐次添加随机线段将森林划分片,直到每一片里面只有一棵树。孤立的树总是会在比较早的时候就分到独立的区域。

例如x0这个点,只需要四次划分就被分到独立区域,xi这个点需要11次划分才能分到独立区域。(这张图只演示了一次划分过程。如果重复多次划分,每次划分的方法都是随机的,但x0都是比较早被分出来,则可以认为x0肯定是差异点)
孤立森林是比较实用的异常数据挖掘算法,不需要现成的异常数据样本。
3 LOF
暂时没看懂原理
可视化分析
将数据进行建模形成不同维度数据,并对不同维度数值做标准化,降维到一维或者二维数据以方便通过散点图,折线图,箱线图,热力图等把数据可视化展示,供分析人员直观识别。
例如将人群年龄段,体重,性别,体育成绩等做加权累计,得出一个单一维度的数据,使用箱线图进行展示。
人工智能分析
这种相对来说比较适合没有专家参与的异常数据分析。利用深度学习算法,只需要前期导入足够多的有标记数据,经过多轮训练,得出一个合适的模型。
但缺点是结果无法预期(目前人类很难搞清楚人工智能的思维),而且需要比较长时间的训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号