

介绍一个对陌生程序快速进行性能瓶颈分析的技巧
前言
工作多年,一直做的是curd系统。前几年做的系统应用场景,大多对数据库依赖比较重。例如报表统计,数据迁移,批量对账等。所以这些系统出现性能瓶颈一般出在数据库操作上面。
如果程序因为数据库操作出现性能瓶颈是比较好办的,因为oracle提供了完善的性能分析工具。往往使用awr报告简单分析一下(top sql和top event)就可以获知有哪些sql有异常。
找出问题sql,根据经验进行优化即可,例如没索引的加索引,有索引没走的加hint,IO太慢的话加并行之类。之前我整理过的一些数据库sql优化经验在博客里面发过。



更多关于数据库应用优化的知识见这里:https://www.cnblogs.com/kingstarer/p/9613626.html
但今年做的系统,有时也会出现数据库资源充足,但由于程序自身写得不好,导致cpu消耗太高,系统反应缓慢的情况。
这种如果是自己写的程序相对比较好处理,因为写的时候大概会知道哪些地方容易出问题。
但有时也会有接手别人的程序出现问题需要优化的情况,这种以前我是都需要花时间重新看一下他们的源码,然后结合日志分析问题出哪里,效率相对比较低。
不过最近我发现一个工具,能直观地统计出程序资源消耗,对于优化帮助特别大。今年我有几次对项目组的程序做优化,都是先用它发现问题关键,然后再进行优化的。
这种方式比以前凭经验分析好,因为有时自己觉得有问题的代码,优化后发现效果甚微。(代码使用频率低,或者瓶颈出现在其它地方。)例如今年我曾经把系统取环境变量的代码,从原来直接使用getenv,改为从缓存里面取数(getenv是顺序查找,缓存取是自己写的二分查找),但发现对于系统整体性能提高不到1%。
下面以一次项目组优化的过程为例,给大家介绍一下这个工具----callgrind的用法:
概述
callgrind是vallgrind工具家族中的一员,它相比其它性能测试工具的好处是不需要修改源码、编译选项(推荐加-g,但不是必要的)、系统参数等。但也存在缺点,如分析过程中程序性能下降较大,无法对已启动的进程进行性能分析,无法分析函数实际耗时(分析的是消耗cpu时间,如果存在sleep、wait之类函数会影响分析结果),对递归调用展示不友好等。不过好在我们项目中,这些缺点不太影响我们使用。
callgrind分析完程序后会使用Ir(指令执行的次数)来统计程序中函数调用消耗,同时还会建立函数调用关系图,需要分析程序流程时可以参考。同时callgrind还能分析程序缓存使用情况,帮助我们优化if和switch顺序。还有分析锁顺序等其它功能。
每次运行结束时,它会把分析数据写入一个文件,之后我们可以通过callgrind_annotate或kcachegrind读取分析结果展示成可读的报告。
接下来我介绍callgrind的使用心得。
背景
rcc查询业务由于业务量增长,现在部署了查询的三台机器平时cpu负荷接近50%,在交易量偏大时cpu会增涨到100%。
项目组临时投入新 机器资源将cpu消耗控制到25~50%,以减少系统性能告警。但后续仍需对应用进行优化,以防故障再次发生。
问题还原与分析
在测试环境上经过一番配置,还原了系统故障现象。仔细观察可以发现:
在并发数比较低时,系统cpu消耗较低,但并发数高一些时,系统cpu消耗急剧上涨,很快就到达100%,但此时tps基本不变。
|
并发数 |
cpu使用率 |
tps |
|
6 |
约60% |
73 |
|
12 |
约100% |
68 |
观察top和vmstat信息,发现两个异常:
1 vmstat显示user消耗超过90%,而sys只占不到10%。对于非计算密集应用,这个比例有点高
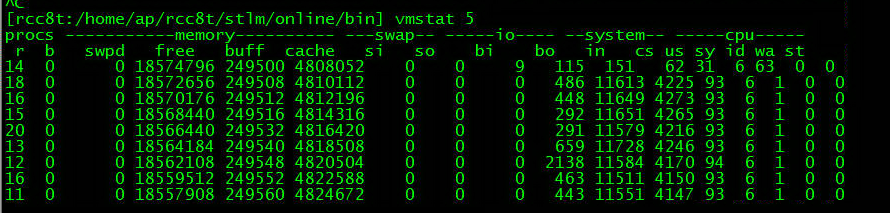
2 top显示系统消耗cpu最多的进程并非业务服务进程,而是加解密相关的服务进程
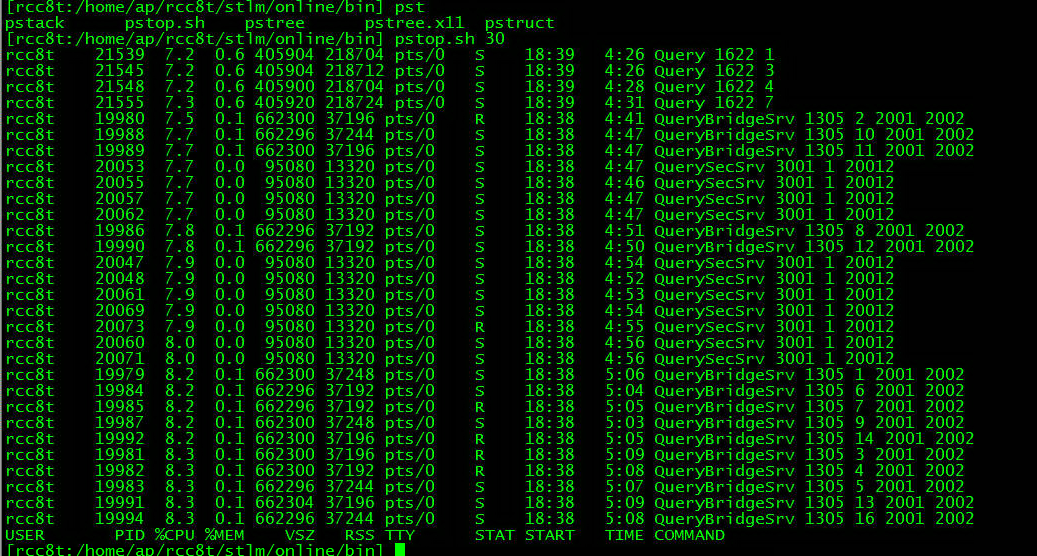
图示:QueryBridgeSrv和QuerySecSrv消耗了比较多的cpu资源。而Query核心业务进程反而消耗得不是很多。(从下到上cpu消耗逐渐下降)
业务服务代码经常修改,项目组开发人员比较熟悉,通过日志即可迅速定位问题出在哪。但是报文较验转换服务由于修改的比较少,比较难定位问题,所以决定使用callgrind辅助分析。
callgrind一般用法
对于一般的程序,我们可以直接启动callgrind分析程序,只需要在命令行前面加上"valgrind --tool=callgrind ",如下:

等程序运行完退出后会在目录生成分析文件,命名为callgrind.out.进程号文件,我们可以使用callgrind_annotate在命令行界面上对其进行分析,但一般是拿到windows环境下使用kcachegrind分析。

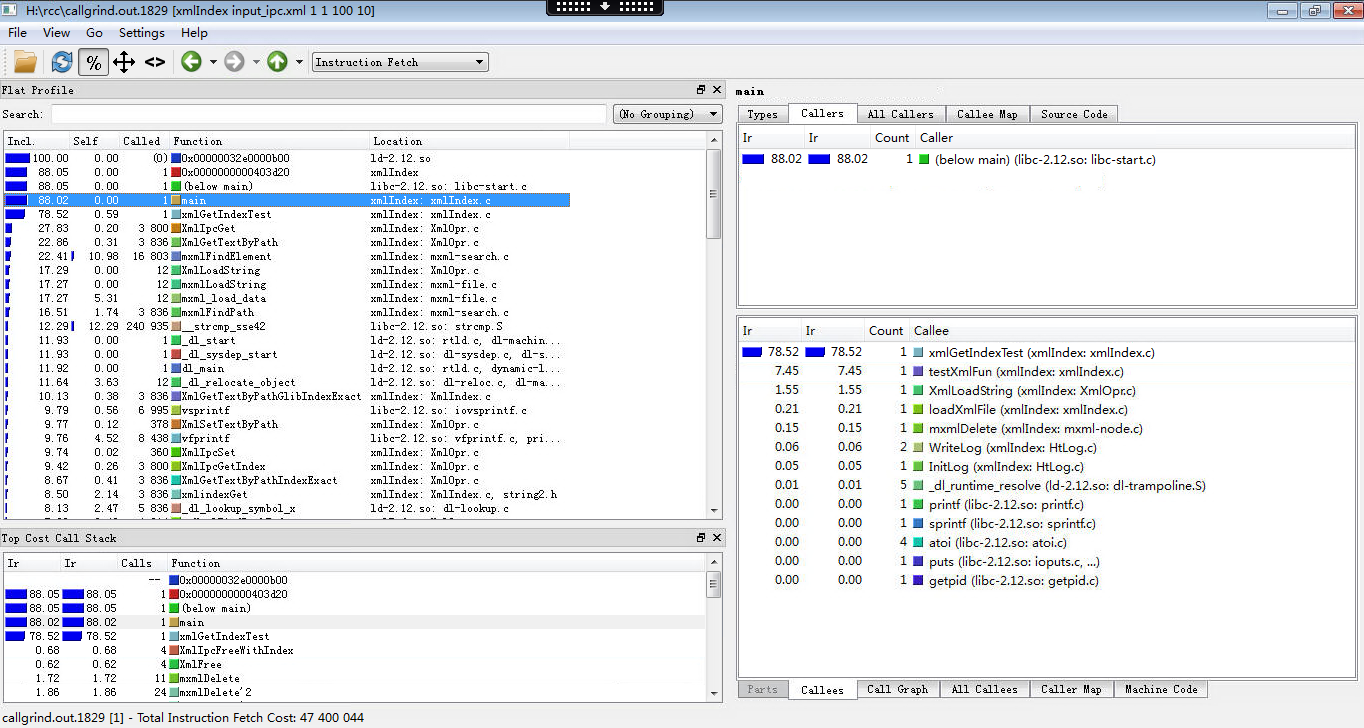
callgrind在项目中的用法
由于项目中的程序是以服务形式启动的,不会自然退出,所以需要使用另外的方法收集分析结果文件。
单进程程序QueryBridgeSrv分析方法:
由于QueryBridgeSrv服务是单进程程序,所以只需要直接启动即可。
不过由于我们项目把很多程序启动参数放在环境变量,不设置的话启动会出异常。所以启动前需要设置环境变量,可以使用以下脚本获取QueryBridgeSrv程序环境变量
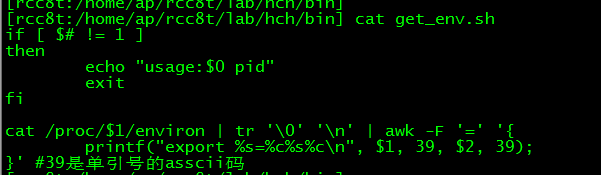
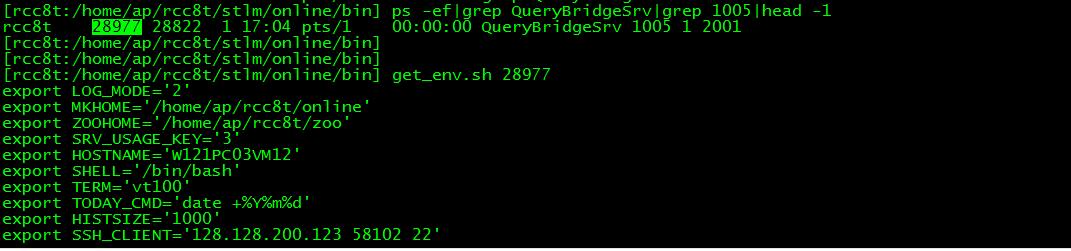
执行脚本后即可获取设置环境变量语句,执行后即可正常启动
time valgrind --tool=callgrind --callgrind-out-file="callgrind.bridge_1305_%p.out" QueryBridgeSrv 1305 17 2001 2002 # callgrind-out-file选项是指定生成的分析文件名字 更多选项可参考man valgrind

进程启动后我们就可以开始执行正常的测试用例,让callgrind分析程序运行情况。等运行得差不多了,我们可以在其它会话窗口执行callgrind_control命令将收集的信息文件输出。
callgrind_control选项也不少,一般我们会使用到以下两个选项:
callgrind_control -d # dump出目前收集的信息
callgrind_control -k # 停止callgrind(不会输出收集文件 所以先要dump)
多进程程序QuerySecSrv分析方法:
对于多进程程序,最好由项目的Daemon进程启动。所以我们可以设计一个启动脚本放到bin目录下面:

然后修改tbl_srv_param参数,将启动程序名字由QuerySecSrv改为QuerySecSrv.sh
这样Daemon就会启动QuerySecSrv.sh,然后由QuerySecSrv.sh启动callgrind对QuerySecSrv进行分析。
进程启动后获取分析结果文件方法与QueryBridgeSrv一致。
kcachegrind介绍
对于生成的文件,我们可以使用kcachegrind进行分析:使用kcachegrind打开之前我们分析QueryBridgeSrv的结果文件(文件一定要以"callgrind."开头),显示如下:

左上角的Flat Profile窗格,第一列是函数消耗的总资源(包括函数本身开销和函数内部调用的子函数开销之和),第二列是函数本身的开销。
可以想象,main函数一般是系统中总开销最大的,因为大部分函数是由main函数调用的。但是main函数自身消耗可能不多,大部分指令是它调用的其它函数消耗的。
右上角的窗格(后面称callers窗格),我们一般用来显示该函数被调用的信息(callers),如图,可以看出GenCtx函数只有一个调用者GenSecHead。
右下角窗口(后面称callees窗格),我们一般用来显示该函数调用其它函数信息(callees),如图,可以看出GenCtx函数调用了好多个函数及分别消耗的指令数。
因为我们一般不关心函数实际开销,而是关心函数相对开销,所以kcachegrind提供了两个按钮,把开销显示成百分比。
 (百分号控制的是Flat Profile窗口显示方式,十字箭头控制的是Callers和Callees窗格)
(百分号控制的是Flat Profile窗口显示方式,十字箭头控制的是Callers和Callees窗格)
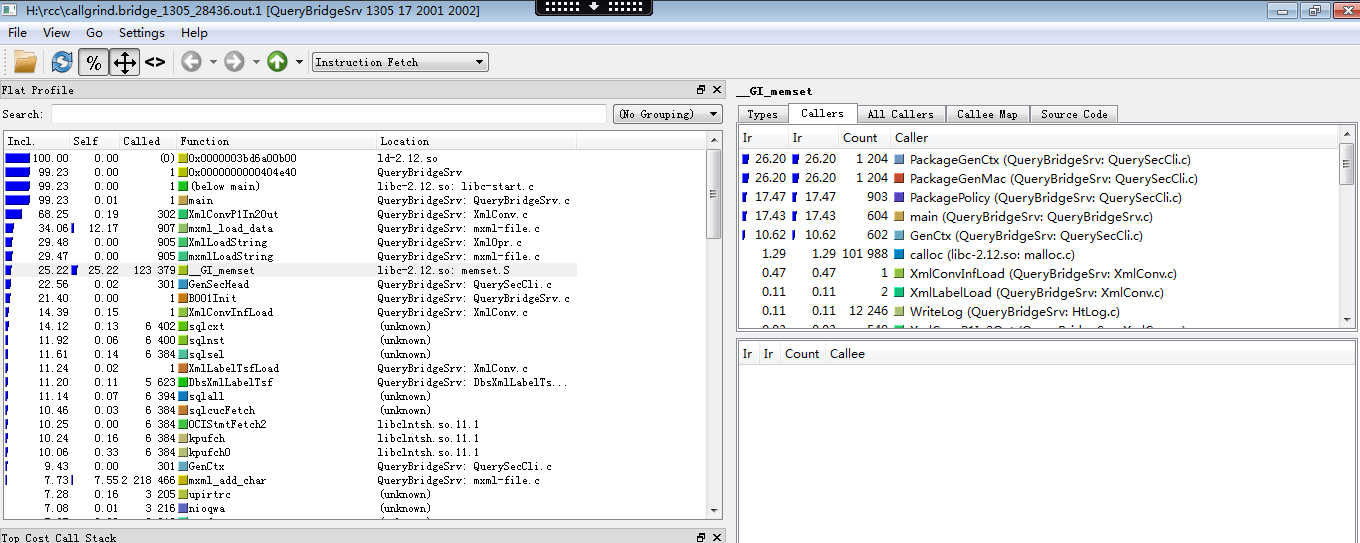
按百分比显示后我们可以清楚地看出memset函数占用了程序开销的73%,而且消耗在其自身。(Self)

对于一般应用,memset函数是没有优化空间的,所以我们要观察是哪些函数调用了memset这么多次。
在Flat Profile窗口单击memset函数,可以看到调用memset函数的信息
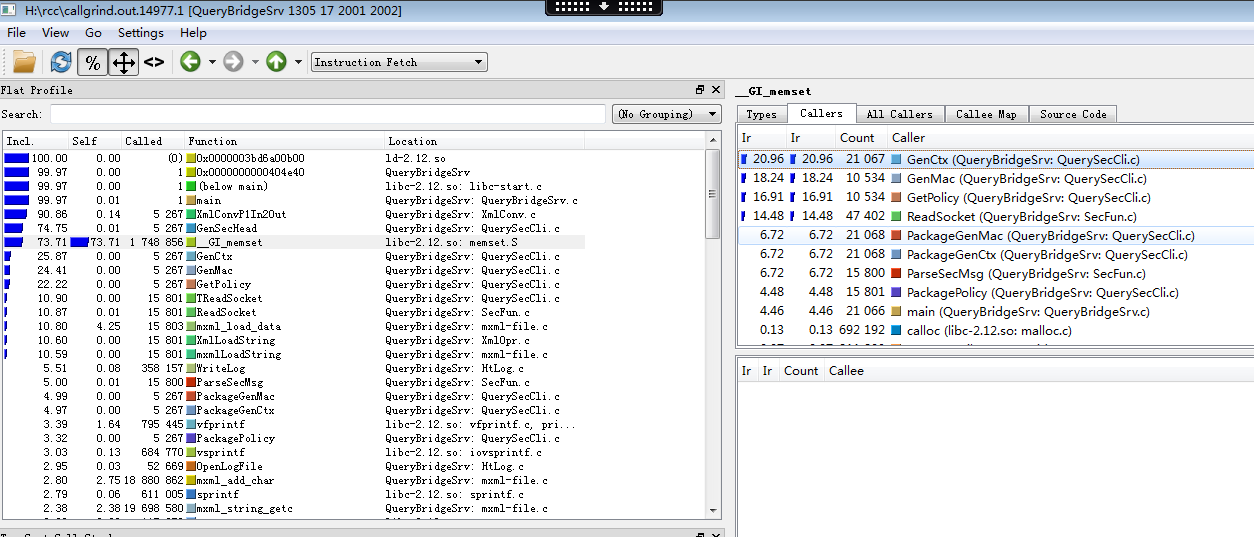
从上图我们可以看出20%的memset调用消耗是由于GenCtx引起的,我们先看看这个函数。在Callers窗格双击,可以进到GenCtx函数的分析(分析过程可以使用工具栏的导航按钮前后跳转)
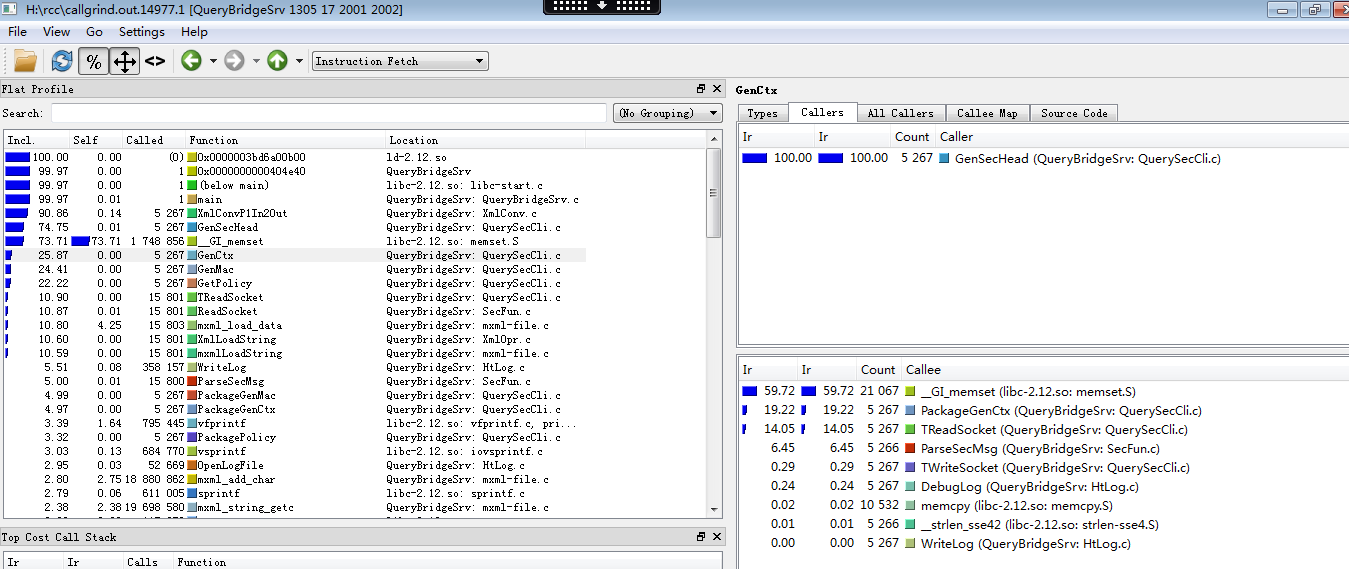
可以看到GenCtx函数50%的消耗在于memset,我们可以到对应函数看有没有调用必要。
在Flat Profile窗格下拉列表选择source file就可以看到函数所在源文件。由于windows环境下代码路径问题,无法在kcachegrind直接查看代码信息,只能另外打开vs查看代码。(根据网上介绍,使用callgrind_annotate可以直接看到每行代码消耗指令数,对于分析长函数帮助很大,暂时未在项目中实践)
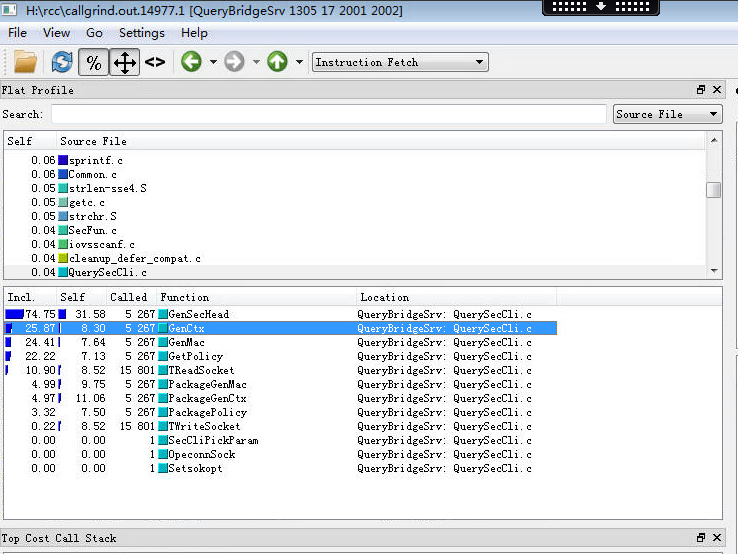
在源码里面我们发现几处memset调用,作用是把某大块内存(395k)初始化为零。经分析,这几处地方并不是特别需要调用memset。应是当时写代码时使用防御性编程技巧,宁杀错,不放过,统一清零。当这个函数只调用一次时,这些操作对系统性能消耗不算多。但当业务量比较大,函数调用次数较多时,这种初始化操作会给系统带来较大性能消耗。
把初始化代码代码注释了(如下),重新编译程序,验证发现功能不受影响。
这里本来应该要贴问题代码,但这里是博客,就不贴了,避免泄密风险。
//注意,这里变量初始化为零,其实也可能导致隐式调用了memset(具体看编译器实现)
继续使用kcachegrind分析其它函数,把不必要的memset都改掉,再重新跑。发现memset消耗降低了很多。
用同样方法对QuerySecSrv进行分析,发现也主要是memset消耗占大头,一样修改。
kcachegrind输出函数调用关系图
使用kcachegrind还可以输出函数调用关系及消耗信息全局视图进行分析:
单击main(或者其它想要分析的函数),在callees窗格切换到Call Graph选项,在出现的程序调用图右键可以设置图例选项。(一般建议修改Min.Node Cost选项,把5%改成1%,默认不显示调用消耗低于5%的函数)
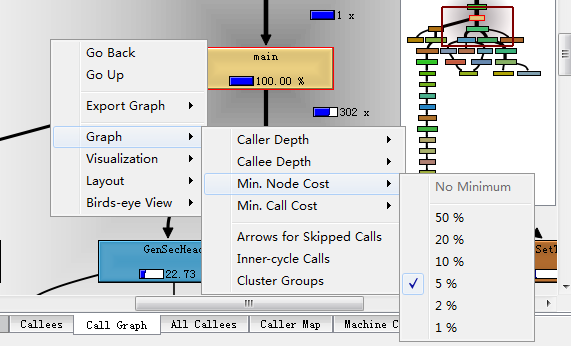
在kcachegrind看大图片不方便,我们可以使用Export Graph功能导出图片,放到看图工具里面查看。

这个功能对于学习程序逻辑也很有帮助。
成果
修改验证通过后后,对系统重新进行非功能测试,结果如下:
|
并发数 |
cpu使用率 |
tps |
|
9 |
约60% |
252 |
|
30 |
约100% |
335 |
图示:cpu使用率100%时us/sy有所下降
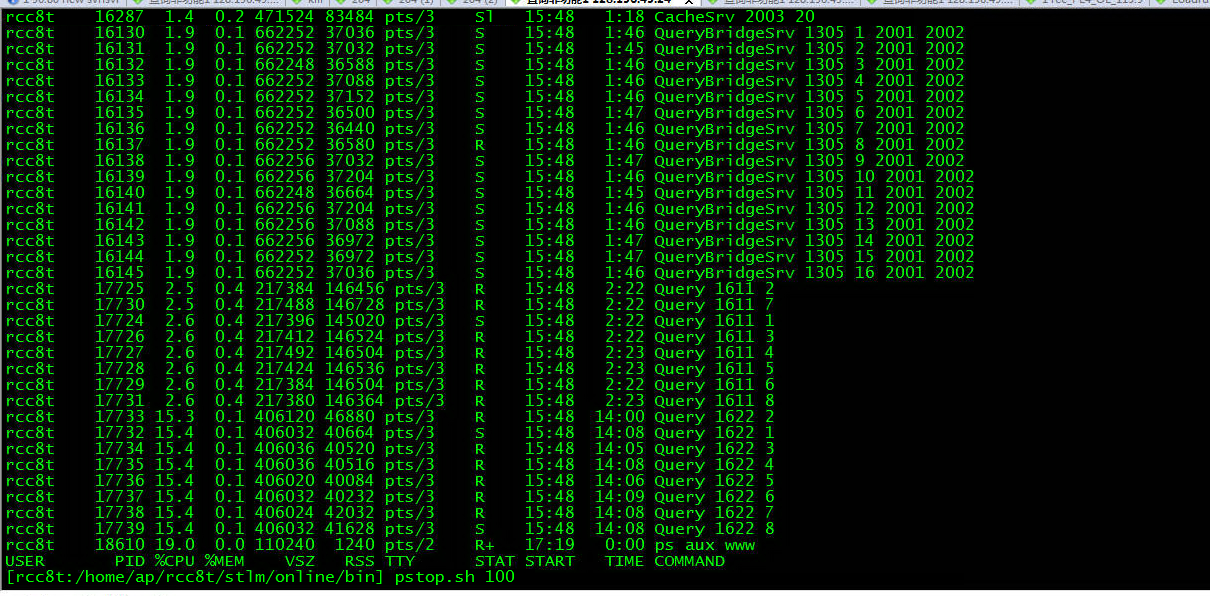
图示:优化后报文较验转换服务已退出cpu占用top10(从下到上cpu消耗逐渐下降)
结语
使用callgrind可以帮助我们快速定位系统性能瓶颈,根据callgrind分析结果针对性对程序进行优化,分析过程也可以输出流程图辅助我们理解程序和单元测试,推荐大家了解一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号