
GreenPlum 大数据平台--基础使用(一)
一,操作语法
01,创建数据库
[gpadmin@greenplum01 ~]$ createdb testDB -E utf-8 --创建用户-- [gpadmin@greenplum01 ~]$ export PGDATABASE=testDB --指定数据库名字 [gpadmin@greenplum01 ~]$ psql --连接本地数据库 psql (8.3.23) Type "help" for help. testDB=# SELECT version(); version ------------------------------------------------------------------------------------------------------------------------------- ----------------------------------------------------------------------- PostgreSQL 8.3.23 (Greenplum Database 5.16.0 build commit:23cec7df0406d69d6552a4bbb77035dba4d7dd44) on x86_64-pc-linux-gnu, co mpiled by GCC gcc (GCC) 6.2.0, 64-bit compiled on Jan 16 2019 02:32:15 (1 row)
02,使用说明
postgres=# \h create view; Command: CREATE VIEW Description: define a new view Syntax: CREATE [ OR REPLACE ] [ TEMP | TEMPORARY ] VIEW name [ ( column_name [, ...] ) ] AS query postgres=# \h create Command: CREATE AGGREGATE Description: define a new aggregate function Syntax: CREATE AGGREGATE name ( input_data_type [ , ... ] ) ( ..... ---\h 为语句的使用说明书
03,建表语句
--语法查询 \h create table --创建表 create table test001(id int,name varchar(128)); --id 为分布键 create table test002(id int,name varchar(128)) distributed by (id); --同上 create table test003(id int,name varchar(128)) distributed by (id,name) --多个分布键 create table test004(id int,name varchar(128)) distributed randomly; --随机分布键 create table test005(id int primary,name varchar(128)); create table test006(id int unique,name varchar(128)); create table test007(id int unique,name varchar(128)) distributed by (id,name); ---创建一模一样的 表 create table test_like (like test001);
04,插入语句
执行insert语句注意分布键不要为空,否则分布键默认变成null',数据都被保存到一个节点上会导致分布不均
insert into test001 values (100,'tom'),(101,'lily'),(102,'jack'),(103,'linda'); insert into test002 values (200,'tom'),(101,'lily'),(202,'jack'),(103,'linda');
05,更新语句
不能批量对分布键执行update,因为分布键执行update需要将数据重分布.
update test002 set id=203 where id=202;
06,删除语句delete--truncate
delete 删除整张表比较慢,所以建议使用truncate
truncate test001;
07,查询语句
postgres=# select * from test2; id | name -----+------ 102 | zxc 203 | rty 105 | bnm 101 | qwe 201 | asd 204 | dfg (6 rows)
08,执行计划
postgres=# select * from test1 x,test2 y where x.id=y.id; id | name | id | name -----+------+-----+------ 101 | lily | 101 | qwe 102 | jack | 102 | zxc (2 rows) postgres=# explain select * from test1 x,test2 y where x.id=y.id; QUERY PLAN ------------------------------------------------------------------------------------------------------ Gather Motion 8:1 (slice2; segments: 8) (cost=0.00..862.00 rows=4 width=17) -> Hash Join (cost=0.00..862.00 rows=1 width=17) Hash Cond: test1.id = test2.id -> Table Scan on test1 (cost=0.00..431.00 rows=1 width=9) -> Hash (cost=431.00..431.00 rows=1 width=8) -> Redistribute Motion 8:8 (slice1; segments: 8) (cost=0.00..431.00 rows=1 width=8) Hash Key: test2.id -> Table Scan on test2 (cost=0.00..431.00 rows=1 width=8) Optimizer status: PQO version 3.21.0 (9 rows)
二,常用数据类型
1.数值类型
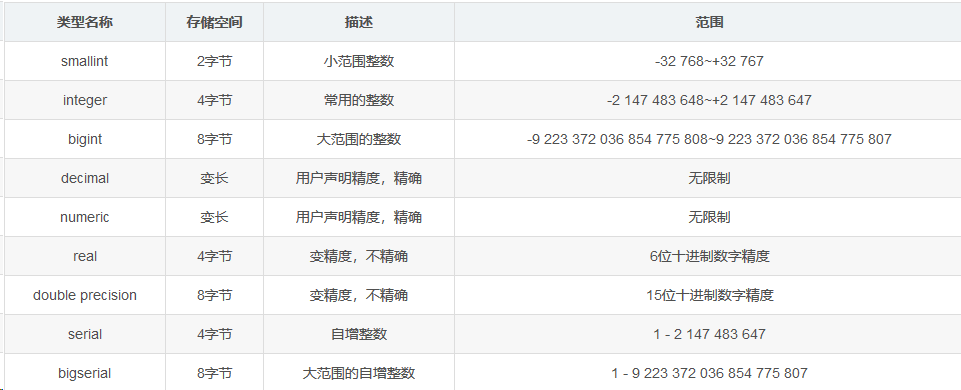
02,字符类型

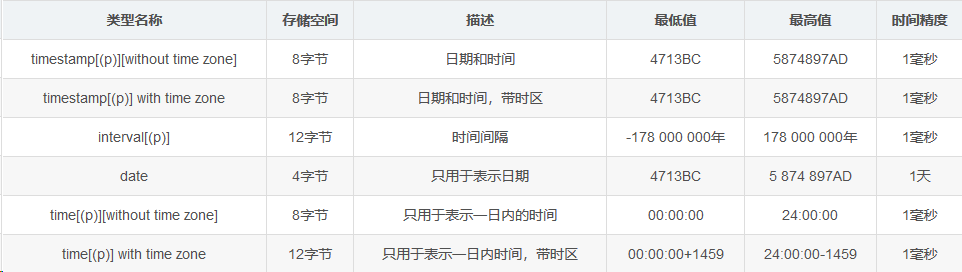
03,时间类型
三,常用函数
1,字符串函数
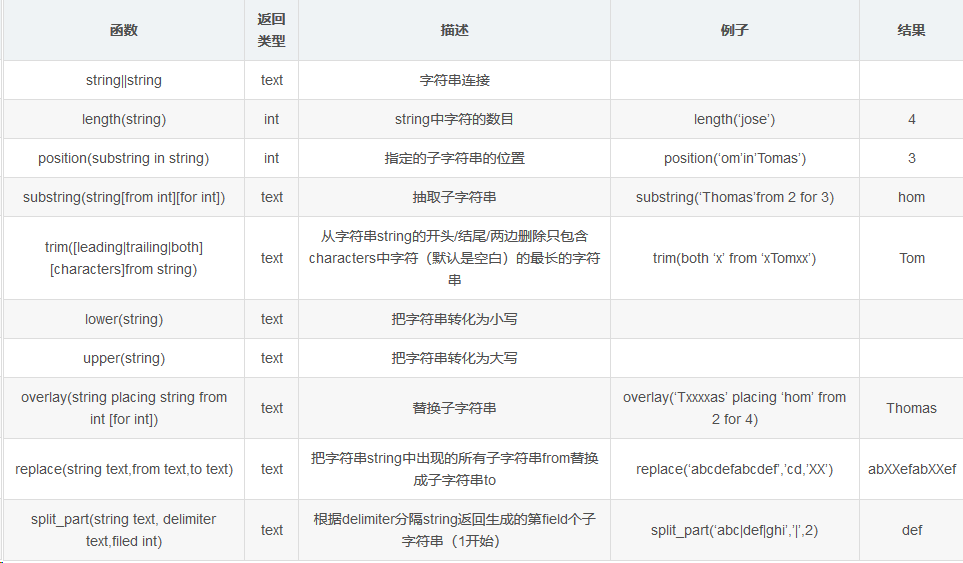
-- postgres=# VALUES ('hello|world!'),('greenplum|database'); column1 -------------------- hello|world! greenplum|database (2 rows) -- postgres=# SELECT substr('hello world!',2,3); substr -------- ell (1 row) -- postgres=# SELECT position('world' in 'hello world!'); position ---------- 7 (1 row)
2,时间函数
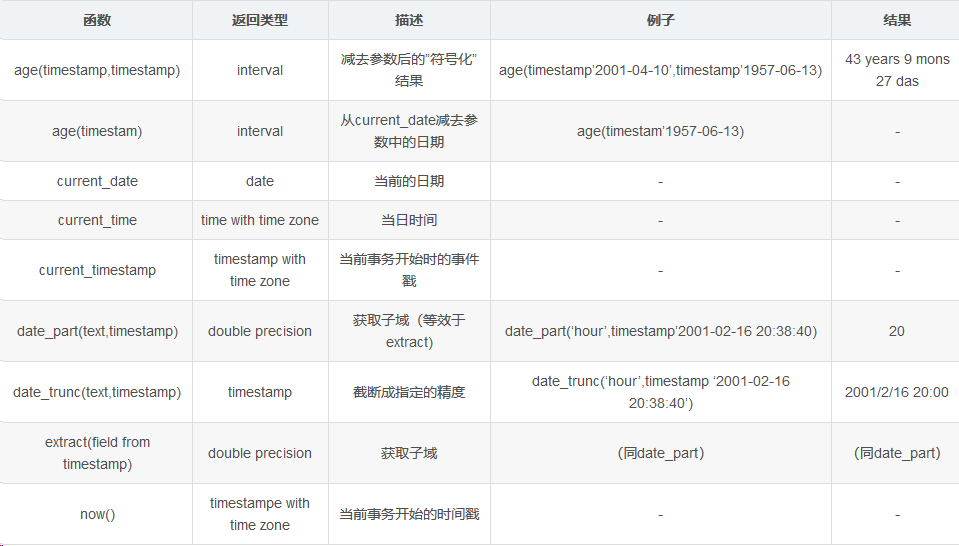
postgres=# SELECT now(),current_date,current_time,current_timestamp; now | date | timetz | now -------------------------------+------------+--------------------+------------------------------- 2019-03-17 22:26:58.330843-04 | 2019-03-17 | 22:26:58.330843-04 | 2019-03-17 22:26:58.330843-04 (1 row)
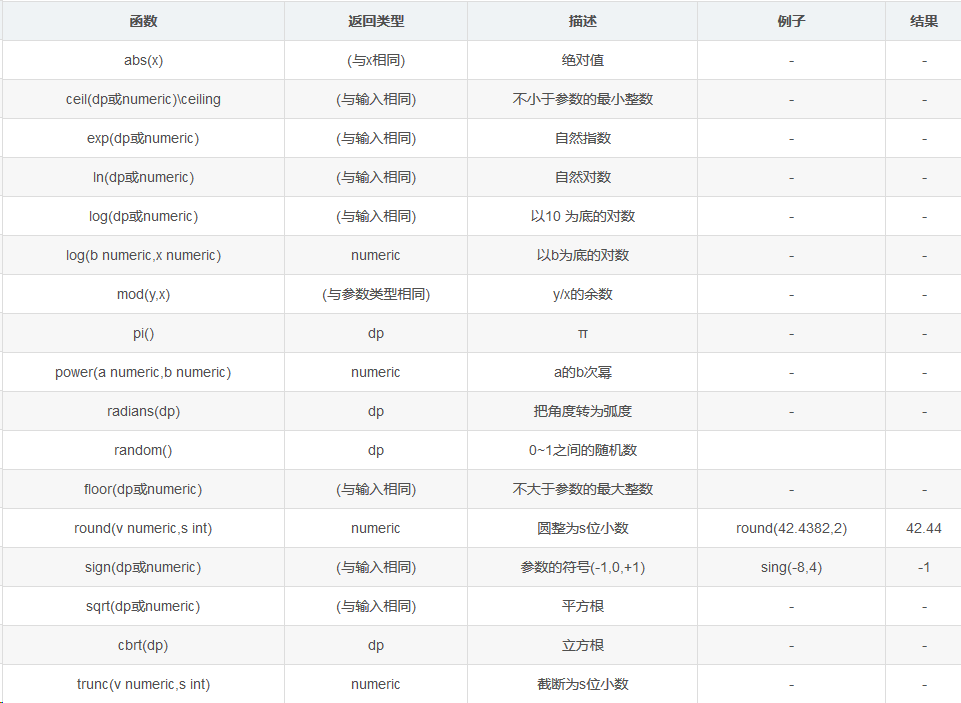
3,数值计算
四,其他函数
1,序列号生成函数——generate_series
postgres=# SELECT * from generate_series(6,10); generate_series ----------------- 6 7 8 9 10 (5 rows)
语法: generate_series(x,y,t)
生成多行数据从x到另外y,步长为t,默认是1
2,字符串列转行——string_agg
string_agg(str,symbol [order by str]) (按照某字段排序)将str列转行,以symbol分隔
3,字符串行转列——regexp_split_to_table
把转成行的数据变成列数据
4,hash函数——md5,hashbpchar
md5的hash算法精度为128位,返回一个字符串
Hashbpchar的精度是32位,返回一个integer类型
postgres=# SELECT md5('admin') postgres-# ; md5 ---------------------------------- 21232f297a57a5a743894a0e4a801fc3 (1 row) postgres=# SELECT hashbpchar('admin'); hashbpchar ------------- -2087781708 (1 row)
人生就像一滴水,非要落下才后悔!
--kingle

 浙公网安备 33010602011771号
浙公网安备 33010602011771号