
Kafka - 05生产者生产消息解析
一、生产者发送消息原理
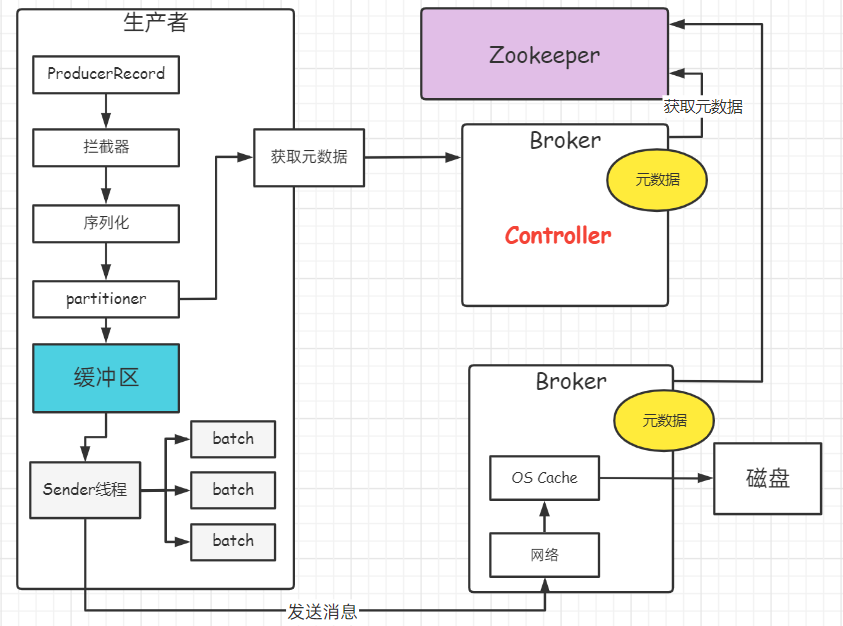
1.1 生产者数据发送过程
- 消息封装成对象
- 把对象序列化成二进制对象
- 通过分区器(partitioner), 决定往topic的哪个分区发送
- 向broker获取元数据(随机一台), 每一台broker元数据都一样
- 获取到信息后, 将数据保存到缓冲区
- 从缓冲区源源不断获取数据,封装成一个个的batch, 多条消息合并成一个batch, 某个batch发往指定分区
- Sender线程将数据发送到broker
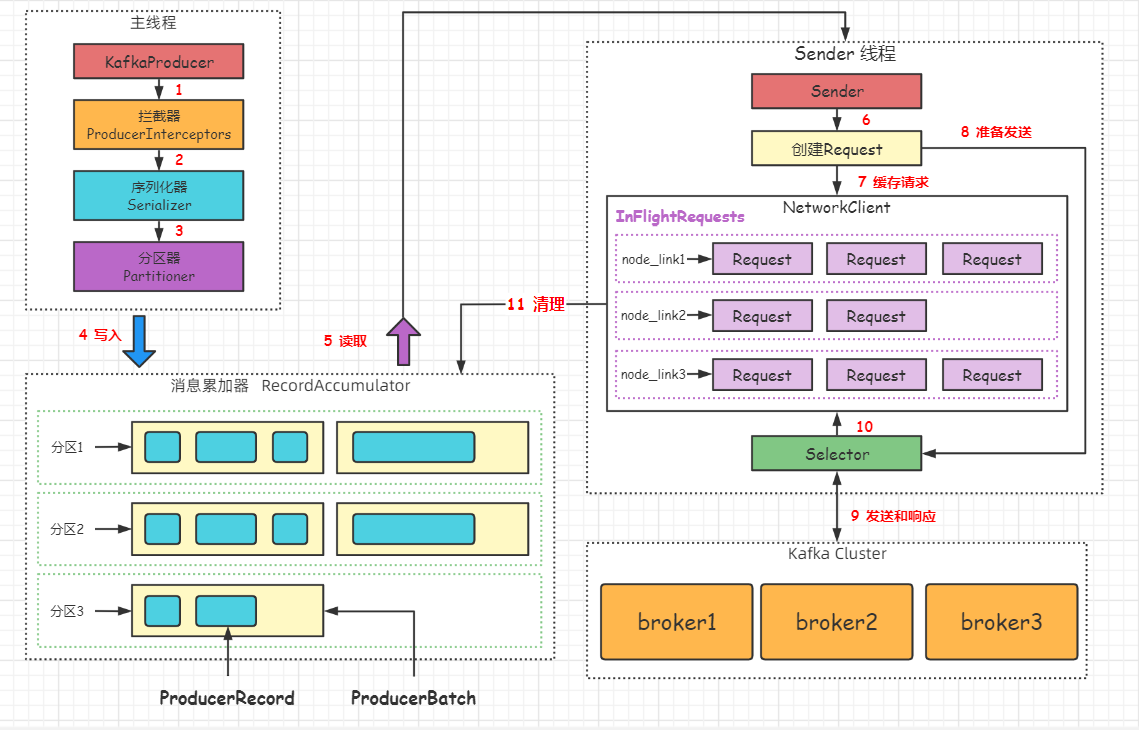
1.2 消息累加器
- 作用
- 用来缓存消息,以便sender线程可以每次批量发送,减少网络传输资源消耗
- 数据到服务端,服务端可以批量写操作,减少磁盘I/O,提升性能
- 消息累加器结构
- 为每个分区维护一个双端队列Deque,队列内容是ProducerBatch, ProducerBatch包含一个或多个ProducerRecord消息
- ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
- 消息ProducerRecord写入到消息累加器时, 会被追加到双端队列的尾部。
- 尾部的ProducerBatch 剩余空间意味着能否写入本次的消息。
- batch.size 控制着ProducerBatch的大小。
- 整个累加器的缓存空间由buffer.memory参数控制。
1.3 消息写入累加器过程
- 先寻找对应分区的双端队列(如果不存在则新建队列)
- 从双端队列的尾部获取一个ProducerBatch对象(如果不存在则新建Batch对象)
- 判断ProducerBatch是否有剩余空间写入本次的消息,可以则写入,不可以则新创建Producer对象
- 新建ProducerBatch对象时评估消息大小是否超过batch.size大小
- 不超过则以batch.size创建Batch对象,超过则以消息的大小创建Batch对象;
- 使用batch.size创建的内存空间会被BufferPool管理,进行空间复用;
- 超过batch.size创建的空间使用完就被回收。
1.4 Sender线程
- Sender线程异步从消息累加器中获取缓存的消息,然后转为指定格式的ProducerRequest对象,发送各个broker。
- 在请求发送broker之前会被保存到InFlightRequest中,缓存已经发出但没有收到服务端响应的请求。
- max.in.flight.request.per.connection: 每个客户端与broker的网络连接的最多缓存请求数,默认是5。
- 超过这个值,客户端不再向这个连接发送更多的请求。
- 当该参数配置大于1时,由于失败重试原因,可能存在消息乱序问题。
二、生产者核心参数
2.1 提升吞吐量
- buffer.memory: 设置发送消息的缓冲器,默认值是33554432,32MB。
- compression.type: 设置发送消息的压缩类型, 默认是none,不压缩。压缩算法有lz4、snappy等, 压缩后减少数据传输量,但加大producer端cpu开销。
- batch.size
- batch 设置太小,导致频繁网络请求,吞吐量下降
- batch 设置过大,导致消息等待太长时间才能发出去,存在延时;内存压力大。
- batch.size 默认值是16384,16KB。 生产环境可以调大提升吞吐量,根据消息大小来设置。
- 消息比较少,可以使用linger.ms,默认值是0, 表示消息必须立刻被发送。可以设置100毫秒。
- 消息被封装处理后进入batch, 在100毫秒内,batch达到16KB, 消息会被发送出去。
2.2 消费发送异常
- LeaderNotAvailableException: 如果机器宕机,leader副本不可用。 follower切换为leader后,才能继续写入。
- NotControllerException: Controller所在服务器宕机,需要等待Controller重新选举。
- NetworkException: 网络异常timeout
- 配置 retries 参数,自动重试: 重试几次后,提供Exception。可以单独处理;发送不成功的消息可以发送到Redis或文件系统,或丢弃。
重试机制带来的问题
- 消息重复: 网络抖动导致生产者认为没有成功,重试发送。
- 消息乱序: 重试导致乱序。
- max.in.flight.requests.per.connection: 设置为1,保证producer同一时间只能发送一条消息。
- retry.backoff.ms: 两次重试的间隔,默认是100毫秒。
2.3 ACK参数
producer端
- request.required.acks=0: 只要请求已经发送出去,不关心broker是否写入成功。性能好,有丢数据风险。
- request.required.acks=1: 当leader partition写入成功后,才算写入成功。存在丢数据问题。
- request.required.acks=-1: 当ISR列表中所有副本都写入成功,才算写入成功。
Kafka服务端
- min.insync.replicas=1
- 默认值是1,一个leader partition会维护一个ISR列表。这个值限制ISR列表至少有几个副本。
- 如果值为2, 当ISR列表中只有一个副本时,写入数据报错。
设计不丢数据的方案
- 分区副本 >= 2; acks = -1; min.insync.replicas >= 2
三、Producer业务场景
3.1 消息key
- 没有设置key: 消息被轮询的发送到topic的不同分区。
- 设置key: 分区器根据key计算出hash值, hash值对应一个分区。key相同的消息,发送到同一个分区。
- 需要设置key的场景:
- 用户的行为有先后顺序: 支付订单、取消订单。 根据订单金额获取积分。
- 不设置key,可以导致积分系统先消费到取消订单的数据。
- 设置了key, 数据发送同一个分区。 消息产生有先后顺序, 保证了消费的顺序。
3.2 生产者代码
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.11.4</version>
</dependency>
</dependencies>
public class ProducerTest {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
props.put("bootstrap.servers","my-node51:9092,my-node52:9092,my-node53:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("buffer.memory", 33554432);
props.put("compression.type", "lz4");
props.put("batch.size", 32768);
props.put("linger.ms", 100);
props.put("retries", 10);
props.put("retry.backoff.ms", 300);
props.put("request.required.acks", "1");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("ttopic2", "topic message 1");
// 异步发送
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e == null) {
System.out.println("消息发送成功");
}else{
System.out.println("重新发送");
}
}
});
Thread.sleep(10 * 1000);
// 同步发送
// producer.send(record).get();
producer.close();
}
}
3.3 自定义分区器
public class HotDataPartitioner implements Partitioner {
private Random random;
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String keyStr = (String) key;
List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);
int partitionCount = partitionInfoList.size();
int hotDataPartition = partitionCount -1;
// key字符串包含hot_data, 发送到 hotData分区,否则随机分配
return !keyStr.contains("hot_data") ? random.nextInt(partitionCount -1):hotDataPartition;
}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) {
random = new Random();
}
}
// 自定义分区器
props.put("partitioner.class", "com.kunking.kafka.producer.HotDataPartitioner");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号