SNet解读
解读论文:Learning Local Image Descriptors with Deep Siamese and Triplet Convolutional Networks by Minimising Global Loss Functions
为什么要总结这么一篇旧的论文?因为里面一些方法具有总结性。
例如对于图像块匹配来说,我自己给出的一个划分:
- 按照网络类型:度量学习(metric learning)和描述子学习(local image discriptor)。
- 按照网络结构:pairwise的siamese结构、triplet的three branch结构,以及引入尺度信息的central-surround结构(此结构往往在baseline中使用进一步提升结果)。
- 按照网络输出:单个概率值(pairwise similarity)、特征向量(feature embedding)。
- 按照损失函数:损失函数可以是对比损失函数、交叉熵损失函数、triplet loss、hinge loss等等。此外损失函数可以带有隐式的困难样本挖掘,例如pn-net中的softpn等,也可以是显示的困难挖掘等等。但是困难挖掘就一定好吗?也不一定,可能导致过拟合是的结果变差。
而本文则是引入一个应用到mini-batch中的全局损失函数(Global Loss Functions)来提高结果,方法非常简单,下面进入正文。
1. 摘要
为什么引入这样一个损失函数?因为当前的siamese和triplet网络易于陷入过拟合。所以作者提出全局损失函数来证明泛化性能的提高。同时作者验证triplet网络比siamese网络产生更加精确的embedding。此外论文Improved Deep Metric Learning with Multi-class N-pair Loss Objective提到:尽管contrastive loss和triplet loss广泛应用,但是都容易遭受收敛慢、需要昂贵的数据采样方法来提供不平凡的pairs或triplets来加速训练。
2. 介绍
作者介绍了当前卷积网络的主要实现,无非就是siamese和triplet网络及变体。注意下图b和d。b为siamese网络,即输入一对匹配或者不匹配的图像块,输出可以是embedding(特征向量)也可以是pairwise similarity(匹配概率值)。而d作为triplet网络一般输出embedding。

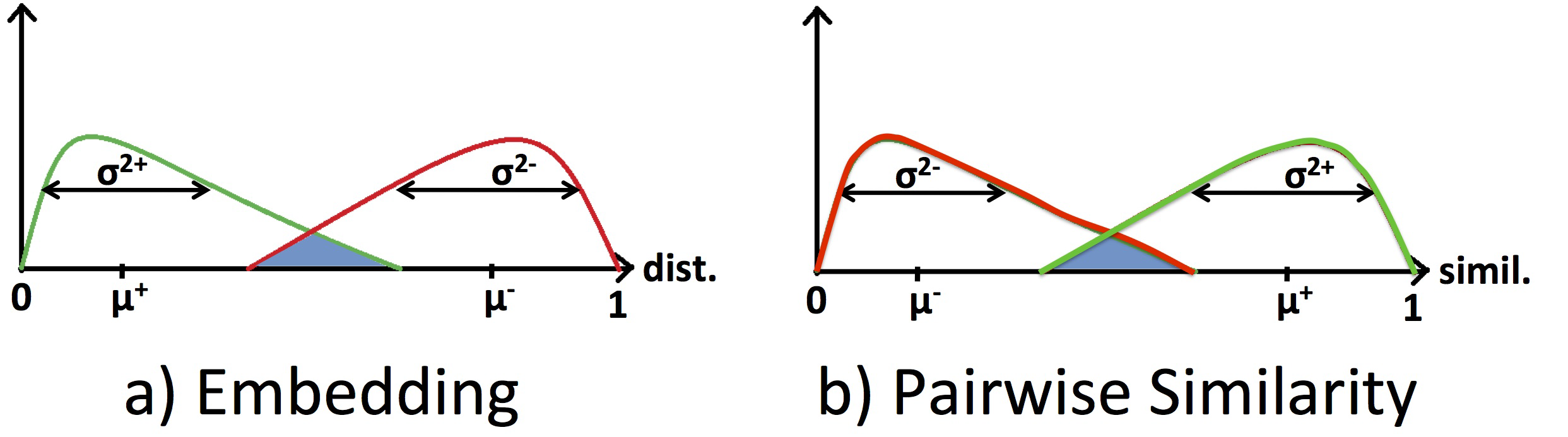
在b和d中作者采用全局损失函数,通过最小化属于同一类和属于不同类的特征的距离的方差,并最小化属于同一类的特征的距离的均值,最大化不同类图像块特征的均值。就是说对于这两类,都要最下化其方差,同时让它们分布尽可能远:类似下图:

为此,作者首先利用triplet network,利用triplet损失函数+global loss。然后利用siamese network+唯一的global loss,最后利用central-surround siamese network来完成实验。这在15年是state-of-the-art的。通过在UBC数据上发现:triplet net比siamese net有更好的分类结果(我觉得这基本毋庸置疑,三张图同时考虑了额外信息)、triplet loss+global loss提升了单triplet loss结果、global loss来训练central-surround siamese net达到了当时最好结果。而后,作者分析了metric learning 和local image descriptor(度量学习和描述子学习)。
3. 方法
这一节,作者看似推了一大堆公式,其实就说明了这个global loss怎么实现?其目标就是实现最小化方差、分别最大最小化均值。
首先介绍pairwise loss(包括embedding feature和similarity estimate),embedding feature的损失:
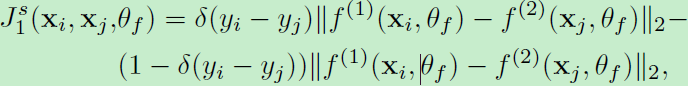
即输出的一对特征向量,对于匹配而言距离越大损失越大,距离越小损失越小。不匹配情况反之。
然后是similarity estimate损失:
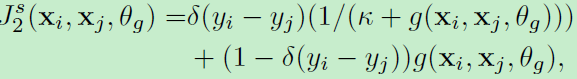
即输出的概率值,对于匹配而言概率越大损失越小,概率越小损失越大,不匹配情况反之。
对于triplet net而言的triplet损失:

就是说对于匹配的图像特征之间的距离要小于不匹配图像特征的距离至少为margin:m。
很好理解,就是下图:
下面global loss就很明确了:
作者讲到siamese和triplet网络含有大量参数,需要采样大量样本来训练。然而采样所有的图像对不可能的,并且其中绝大多数都是简单样本!所以可选的方案是采样策略。必须足够小心,因为在困难样本上关注太多又会导致过拟合,所以这其实很棘手。为此作者提出了这个全局损失函数。这个函数主要为了避免欠采样(太多简单样本)或者过采样(太多困难样本)问题。所以这个损失函数就是要:1) minimise the variance of the two distributions and the mean value of the distances between matching pairs, and 2) maximise the mean value of the distances between non-matching pairs。
1)输出是特征向量feature embedding: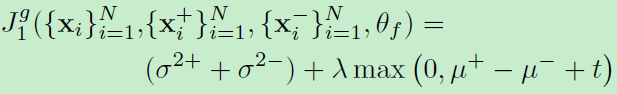
t为margin,方差和均值为一个batch中匹配和非匹配样本的特征距离的方差和均值。
2)输出是相似概率值pairwise similarities:
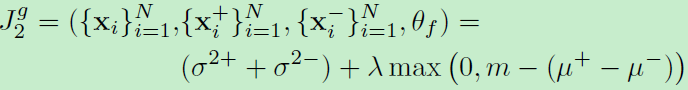
同理稍微一改,方差和均值为一个batch中匹配和非匹配样本的概率的方差和均值。
然后作者的四个实验网络如下:
- TNet,TLoss:triplet net+triplet loss、输出feature embedding
- TNet,TGLoss:triplet net+triplet loss&global loss、输出feature embedding
- SNet,GLoss:siamese net+global loss、输出pairwise similarity estimator
- CS SNet,GLoss:central-surrond siamese net+global loss、输出pairwise similarity estimator
注意前面两个模型产生的是feature embedding,所以局部描述子的比较基于L2正则的距离比较。(也就是计算出特征向量后要正则一下,使得模为1!)
对于网络结构,作者采用的是Learning to compare image patches via convolutional neural networks一文中的结构,再次强调:Finally, the output feature from both siamese networks are normalised to have unit norm。
以下是实验一和实验二的结果:
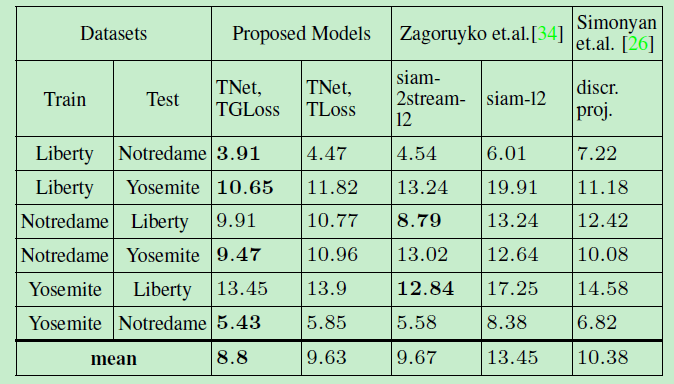
可以看到第二组实验fpr95均值最小,只有8.8。这时feature embedding里最好的结果。
另外作者自己为了验证global loss的有效性,自己随机生成二维数据,看看分类结果:
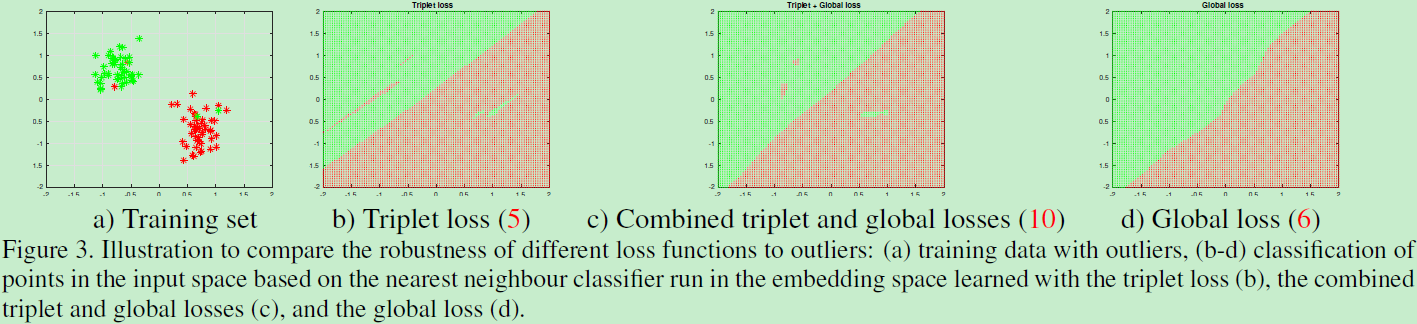
外点明显对b影响很大,过拟合的问题。结合了全局损失后,c好了一些,d中不受外点影响,更鲁棒。
第三四组实验结果:可以看到加上尺度信息后,直接掉了一半fpr95,也看到siamese的5.28优于上面的triplet结果。

然后是对于网络的详细设置,以及UBC数据的分析,这部分略过,可以在论文中找到信息。
4. 实验与结论
从之前两个table,我们也看到了,输出pairwise similarity的siamese结构要优于输出feature embedding的triplet网络,但就siamese成对的输入来说,在测试时比较复杂。确实是,siamese测试一对图像得经过全连接得到一个0-1之间的概率值,而对于特征向量来说可以直接利用余弦内积得到相似度,因为这些向量都被l2 norm为1了,所以得到的也是0-1之间的概率。但是上面不能说的绝对,因为有的方法中triplet更优于siamese,这还是要看网络结构、损失函数、优化策略等等。总结就是global loss首次运用到triplet网络,这个损失函数作用于mini-batches,也比较好实现。
附:
利用直方图损失来区分两种分布:16年cvpr:Learning Deep Embeddings with Histogram Loss
思想:通过在正样本中随机取样所得到的相似性比从负样本中随机取样得到的相似性低的可能性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号