Pytorch 细节记录
1. PyTorch进行训练和测试时指定实例化的model模式为:train/eval
eg:


class VAE(nn.Module): def __init__(self): super(VAE, self).__init__() ... def reparameterize(self, mu, logvar): if self.training: std = logvar.mul(0.5).exp_() eps = Variable(std.data.new(std.size()).normal_()) return eps.mul(std).add_(mu) else: return mu model = VAE() ... def train(epoch): model.train() ... def test(epoch): model.eval()
eval即evaluation模式,train即训练模式。仅仅当模型中有Dropout和BatchNorm是才会有影响。因为训练时dropout和BN都开启,而一般而言测试时dropout被关闭,BN中的参数也是利用训练时保留的参数,所以测试时应进入评估模式。
(在训练时,𝜇和𝜎2是在整个mini-batch 上计算出来的包含了像是64 或28 或其它一定数量的样本,但在测试时,你可能需要逐一处理样本,方法是根据你的训练集估算𝜇和𝜎2,估算的方式有很多种,理论上你可以在最终的网络中运行整个训练集来得到𝜇和𝜎2,但在实际操作中,我们通常运用指数加权平均来追踪在训练过程中你看到的𝜇和𝜎2的值。还可以用指数加权平均,有时也叫做流动平均来粗略估算𝜇和𝜎2,然后在测试中使用𝜇和𝜎2的值来进行你所需要的隐藏单元𝑧值的调整。在实践中,不管你用什么方式估算𝜇和𝜎2,这套过程都是比较稳健的,因此我不太会担心你具体的操作方式,而且如果你使用的是某种深度学习框架,通常会有默认的估算𝜇和𝜎2的方式,应该一样会起到比较好的效果) -- Deeplearning.ai
2. PyTorch权重初始化的几种方法
class discriminator(nn.Module): def __init__(self, dataset = 'mnist'): super(discriminator, self).__init__() 。... self.conv = nn.Sequential( nn.Conv2d(self.input_dim, 64, 4, 2, 1), nn.ReLU(), ) ... self.fc = nn.Sequential( nn.Linear(32, 64 * (self.input_height // 2) * (self.input_width // 2)), nn.BatchNorm1d(64 * (self.input_height // 2) * (self.input_width // 2)), nn.ReLU(), ) self.deconv = nn.Sequential( nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1), #nn.Sigmoid(), # EBGAN does not work well when using Sigmoid(). ) utils.initialize_weights(self) def forward(self, input): ... def initialize_weights(net): for m in net.modules(): if isinstance(m, nn.Conv2d): m.weight.data.normal_(0, 0.02) m.bias.data.zero_() elif isinstance(m, nn.ConvTranspose2d): m.weight.data.normal_(0, 0.02) m.bias.data.zero_() elif isinstance(m, nn.Linear): m.weight.data.normal_(0, 0.02) m.bias.data.zero_()
def init_weights(m): print(m) if type(m) == nn.Linear: m.weight.data.fill_(1.0) print(m.weight) net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2, 2)) net.apply(init_weights)
def weights_init(m): classname = m.__class__.__name__ if classname.find('Conv') != -1: m.weight.data.normal_(0.0, 0.02) elif classname.find('BatchNorm') != -1: m.weight.data.normal_(1.0, 0.02) m.bias.data.fill_(0) net.apply(weights_init)
class torch.nn.Module 是所有神经网络的基类。
modules()返回网络中所有模块的迭代器。
add_module(name, module) 将一个子模块添加到当前模块。 该模块可以使用给定的名称作为属性访问。
apply(fn) 适用fn递归到每个子模块(如返回.children(),以及自我。
3. PyTorch 中Variable的重要属性
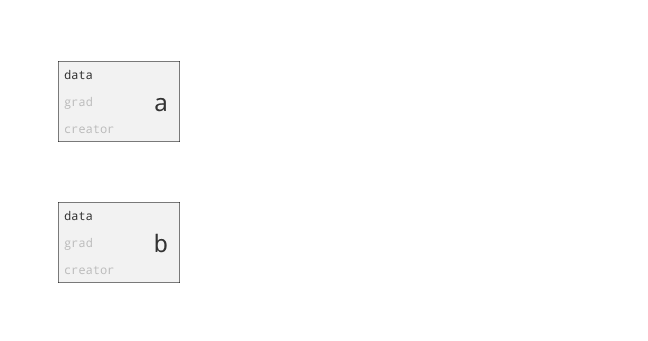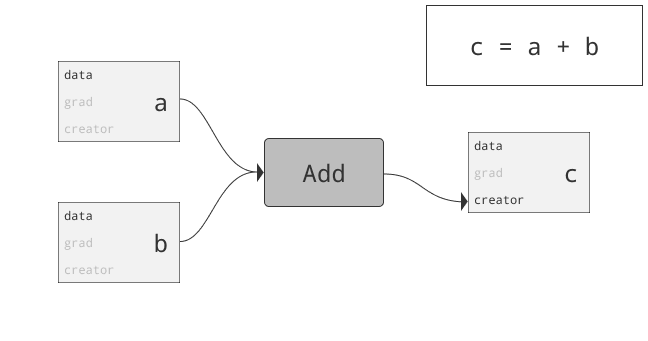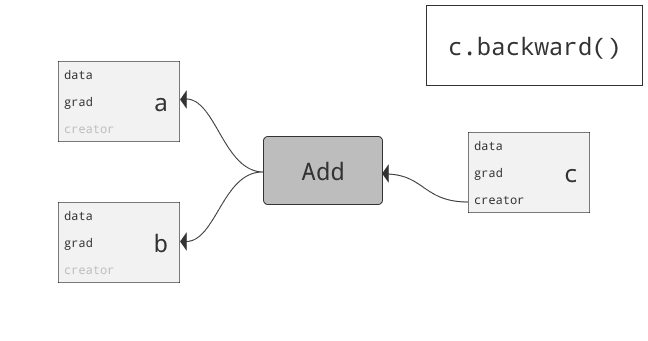
class torch.autograd.Variable
为什么要引入Variable?首先回答为什么引入Tensor。仅仅利用numpy也可以实现前向反向操作,但numpy不支持GPU运算。而Pytorch为Tensor提供多种操作运算,此外Tensor支持GPU。问题来了,两三层网络可以推公式写反向传播,当网络很复杂时需要自动化。autograd可以帮助我们,当利用autograd时,前向传播会定义一个计算图,图中的节点就是Tensor。图中的边就是函数。当我们将Tensor塞到Variable时,Variable就变为了节点。若x为一个Variable,那x.data即为Tensor,x.grad也为一个Variable。那x.grad.data就为梯度的值咯。总结:PyTorch Variables与PyTorch Tensors有着相同的API,Tensor上的所有操作几乎都可用在Variable上。两者不同之处在于利用Variable定义一个计算图,可以实现自动求导!
重要的属性如下:
requires_grad
指定要不要更新這個變數,對於不需要更新的變數可以把他設定成False,可以加快運算。
Variable默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
在用户手动定义Variable时,参数requires_grad默认值是False。而在Module中的层在定义时,相关Variable的requires_grad参数默认是True。
在计算图中,如果有一个输入的requires_grad是True,那么输出的requires_grad也是True。只有在所有输入的requires_grad都为False时,输出的requires_grad才为False。
volatile
指定需不需要保留紀錄用的變數。指定變數為True代表運算不需要記錄,可以加快運算。如果一個變數的volatile是True,則它的requires_grad一定是False。
簡單來說,對於需要更新的Variable記得將requires_grad設成True,當只需要得到結果而不需要更新的Variable可以將volatile設成True加快運算速度。 参考:PyTorch 基礎篇
variable的volatile属性默认为False,如果某一个variable的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。
当有一个输入的volatile=True时,那么输出的volatile=True。volatile=True推荐在模型的推理过程(测试)中使用,这时只需要令输入的voliate=True,保证用最小的内存来执行推理,不会保存任何中间状态。在使用volatile=True的时候,变量是不存储 creator属性的,这样也减少了内存的使用。
参考:自动求导机制 、『PyTorch』第五弹_深入理解autograd_上:Variable属性方法
PyTorch学习系列(十)——如何在训练时固定一些层?、Pytorch笔记01-Variable和Function(自动梯度计算)
detach()
返回一个新变量,与当前图形分离。结果将永远不需要渐变。如果输入是易失的,输出也将变得不稳定。返回的 Variable 永远不会需要梯度。
根据GAN的代码来看:
方法1. 利用detach阶段梯度流:(代码片段:DCGAN)
# train with real netD.zero_grad() real_cpu, _ = data batch_size = real_cpu.size(0) if opt.cuda: real_cpu = real_cpu.cuda() input.resize_as_(real_cpu).copy_(real_cpu) label.resize_(batch_size).fill_(real_label) inputv = Variable(input) labelv = Variable(label) output = netD(inputv) errD_real = criterion(output, labelv) errD_real.backward() D_x = output.data.mean() # train with fake noise.resize_(batch_size, nz, 1, 1).normal_(0, 1) noisev = Variable(noise) fake = netG(noisev) labelv = Variable(label.fill_(fake_label)) output = netD(fake.detach()) errD_fake = criterion(output, labelv) errD_fake.backward() D_G_z1 = output.data.mean() errD = errD_real + errD_fake optimizerD.step() ############################ # (2) Update G network: maximize log(D(G(z))) ########################### netG.zero_grad() labelv = Variable(label.fill_(real_label)) # fake labels are real for generator cost output = netD(fake) errG = criterion(output, labelv) errG.backward() D_G_z2 = output.data.mean() optimizerG.step()
首先在用fake更新D的时候,给G的输出加了detach,是因为我们希望更新时只更新D的参数,而不需保留G的参数的梯度。其实这个detach也是可以不用加的,因为直到netG.zero_grad() 被调用G的梯度是不会被用到的,optimizerD.step()只更新D的参数。
然后在利用fake更新G的时候,却没有给G的输出加detach,因为你本身就是需要更新G的参数,所以不能截断它。
参考:stackoverflow 、github_issue(why is detach necessary)
方法2.利用 volatile = True 来冻结G的梯度:(代码片段:WGAN
# train with real real_cpu, _ = data netD.zero_grad() batch_size = real_cpu.size(0) if opt.cuda: real_cpu = real_cpu.cuda() input.resize_as_(real_cpu).copy_(real_cpu) inputv = Variable(input) errD_real = netD(inputv) errD_real.backward(one) # train with fake noise.resize_(opt.batchSize, nz, 1, 1).normal_(0, 1) noisev = Variable(noise, volatile = True) # totally freeze netG fake = Variable(netG(noisev).data) inputv = fake errD_fake = netD(inputv) errD_fake.backward(mone) errD = errD_real - errD_fake optimizerD.step() ############################ # (2) Update G network ########################### for p in netD.parameters(): p.requires_grad = False # to avoid computation netG.zero_grad() # in case our last batch was the tail batch of the dataloader, # make sure we feed a full batch of noise noise.resize_(opt.batchSize, nz, 1, 1).normal_(0, 1) noisev = Variable(noise) fake = netG(noisev) errG = netD(fake) errG.backward(one) optimizerG.step() gen_iterations += 1
冻结G的梯度,即在更新D的时候,反向传播计算梯度时不会计算G的参数的梯度。作用与方法1相同。
eg:
如果我们有两个网络 A,B, 两个关系是这样的 y=A(x),z=B(y). 现在我们想用 z.backward()来为 B 网络的参数来求梯度,但是又不想求 A 网络参数的梯度。我们可以这样:
# y=A(x), z=B(y) 求B中参数的梯度,不求A中参数的梯度 # 第一种方法 y = A(x) z = B(y.detach()) z.backward() # 第二种方法 y = A(x) y.detach_() z = B(y) z.backward()
参考: pytorch: Variable detach 与 detach_ 、Pytorch入门学习(九)---detach()的作用(从GAN代码分析)
另一个简单说明detach用法的github issue demo:
fc1 = nn.Linear(1, 2) fc2 = nn.Linear(2, 1) opt1 = optim.Adam(fc1.parameters(),lr=1e-1) opt2 = optim.Adam(fc2.parameters(),lr=1e-1) x = Variable(torch.FloatTensor([5])) z = fc1(x) x_p = fc2(z) cost = (x_p - x) ** 2 ''' print (z) print (x_p) print (cost) ''' opt1.zero_grad() opt2.zero_grad() cost.backward() for n, p in fc1.named_parameters(): print (n, p.grad.data) for n, p in fc2.named_parameters(): print (n, p.grad.data) opt1.zero_grad() opt2.zero_grad() z = fc1(x) x_p = fc2(z.detach()) cost = (x_p - x) ** 2 cost.backward() for n, p in fc1.named_parameters(): print (n, p.grad.data) for n, p in fc2.named_parameters(): print (n, p.grad.data) 结果: weight 12.0559 -8.3572 [torch.FloatTensor of size 2x1] bias 2.4112 -1.6714 [torch.FloatTensor of size 2] weight -33.5588 -19.4411 [torch.FloatTensor of size 1x2] bias -9.9940 [torch.FloatTensor of size 1] ================================================ weight 0 0 [torch.FloatTensor of size 2x1] bias 0 0 [torch.FloatTensor of size 2] weight -33.5588 -19.4411 [torch.FloatTensor of size 1x2] bias -9.9940 [torch.FloatTensor of size 1]
pytorch学习经验(一) detach, requires_grad和volatile
grad_fn
梯度函数图跟踪。每一个变量在图中的位置可通过其grad_fn属性在图中的位置推测得到。
is_leaf
查看是否为叶子节点。即如果由用户创建。
x = V(t.ones(1)) b = V(t.rand(1), requires_grad = True) w = V(t.rand(1), requires_grad = True) y = w * x # 等价于y=w.mul(x) z = y + b # 等价于z=y.add(b) x.requires_grad, b.requires_grad, w.requires_grad (False, True, True) x.is_leaf, w.is_leaf, b.is_leaf (True, True, True) z.grad_fn <AddBackward1 object at 0x7f615e1d9cf8> z.grad_fn.next_functions ((<MulBackward1 object at 0x7f615e1d9780>, 0), (<AccumulateGrad object at 0x7f615e1d9390>, 0)) #next_functions保存grad_fn的输入,是一个tuple,tuple的元素也是Function # 第一个是y,它是乘法(mul)的输出,所以对应的反向传播函数y.grad_fn是MulBackward # 第二个是b,它是叶子节点,由用户创建,grad_fn为None
autograd.grad、register_hook
在反向传播过程中非叶子节点的导数计算完之后即被清空。若想查看这些变量的梯度,有两种方法:
- 使用autograd.grad函数
- 使用register_hook
x = V(t.ones(3), requires_grad=True) w = V(t.rand(3), requires_grad=True) y = x * w # y依赖于w,而w.requires_grad = True z = y.sum() x.requires_grad, w.requires_grad, y.requires_grad (True, True, True)
# 非叶子节点grad计算完之后自动清空,y.grad是None z.backward() (x.grad, w.grad, y.grad) (Variable containing: 0.1636 0.3563 0.6623 [torch.FloatTensor of size 3], Variable containing: 1 1 1 [torch.FloatTensor of size 3], None)
此时y.grad为None,因为backward()只求图中叶子的梯度(即无父节点),如果需要对y求梯度,则可以使用autograd_grad或`register_hook`使用autograd.grad:
# 第一种方法:使用grad获取中间变量的梯度 x = V(t.ones(3), requires_grad=True) w = V(t.rand(3), requires_grad=True) y = x * w z = y.sum() # z对y的梯度,隐式调用backward() t.autograd.grad(z, y) (Variable containing: 1 1 1 [torch.FloatTensor of size 3],)
使用hook:
# 第二种方法:使用hook # hook是一个函数,输入是梯度,不应该有返回值 def variable_hook(grad): print('y的梯度: \r\n',grad) x = V(t.ones(3), requires_grad=True) w = V(t.rand(3), requires_grad=True) y = x * w # 注册hook hook_handle = y.register_hook(variable_hook) z = y.sum() z.backward() # 除非你每次都要用hook,否则用完之后记得移除hook hook_handle.remove() y的梯度: Variable containing: 1 1 1 [torch.FloatTensor of size 3]
参考:pytorch-book/chapter3-Tensor和autograd/
关于梯度固定与优化设置:
model = nn.Sequential(*list(model.children())) for p in model[0].parameters(): p.requires_grad=False
for i in m.parameters(): i.requires_grad=False
optimizer.SGD(filter(lambda p: p.requires_grad, model.parameters()), lr=1e-3)
可以在中间插入冻结操作,这样只冻结之前的层,后续的操作不会被冻结:
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5) for p in self.parameters(): p.requires_grad=False self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)
count = 0 para_optim = [] for k in model.children(): # model.modules(): count += 1 # 6 should be changed properly if count > 6: for param in k.parameters(): para_optim.append(param) else: for param in k.parameters(): param.requires_grad = False optimizer = optim.RMSprop(para_optim, lr) ################ # another way for idx,m in enumerate(model.modules()): if idx >50: for param in m.parameters(): param.requires_grad = True else: for param in m.parameters(): param.requires_grad = False
对特定层的权重进行限制:
def clamp_weights(self): for module in self.net.modules(): if(hasattr(module, 'weight') and module.kernel_size==(1,1)): module.weight.data = torch.clamp(module.weight.data,min=0)
参考:github
载入权重后发现错误率或正确率不正常,可能是学习率已改变,而保存和载入时没有考虑优化器:所以保存优化器:
save_checkpoint({ 'epoch': epoch + 1, 'arch': args.arch, 'state_dict': model.state_dict(), 'optimizer': optimizer.state_dict(), 'prec1': prec1, }, save_name) # save if args.resume: if os.path.isfile(args.resume): print("=> loading checkpoint '{}'".format(args.resume)) checkpoint = torch.load(args.resume) args.start_epoch = checkpoint['epoch'] model.load_state_dict(checkpoint['state_dict']) optimizer.load_state_dict(checkpoint['optimizer']) print("=> loaded checkpoint '{}' (epoch {})" .format(args.resume, checkpoint['epoch'])) else: print("=> no checkpoint found at '{}'".format(args.resume)) # load
对特定的层学习率设置:
params = [] for name, value in model.named_parameters(): if 'bias' in name: if 'fc2' in name: params += [{'params':value, 'lr': 20 * args.lr, 'weight_decay': 0}] else: params += [{'params':value, 'lr': 2 * args.lr, 'weight_decay': 0}] else: if 'fc2' in name: params += [{'params':value, 'lr': 10 * args.lr}] else: params += [{'params':value, 'lr': 1 * args.lr}] optimizer = torch.optim.SGD(params, args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
或者:
class net(nn.Module): def __init__(self): super(net, self).__init__() self.conv1 = nn.Conv2d(3, 64, 1) self.conv2 = nn.Conv2d(64, 64, 1) self.conv3 = nn.Conv2d(64, 64, 1) self.conv4 = nn.Conv2d(64, 64, 1) self.conv5 = nn.Conv2d(64, 64, 1) def forward(self, x): out = conv5(conv4(conv3(conv2(conv1(x))))) return out 我们希望conv5学习率是其他层的100倍,我们可以: net = net() lr = 0.001 conv5_params = list(map(id, net.conv5.parameters())) base_params = filter(lambda p: id(p) not in conv5_params, net.parameters()) optimizer = torch.optim.SGD([ {'params': base_params}, {'params': net.conv5.parameters(), 'lr': lr * 100}, , lr=lr, momentum=0.9) 如果多层,则: conv5_params = list(map(id, net.conv5.parameters())) conv4_params = list(map(id, net.conv4.parameters())) base_params = filter(lambda p: id(p) not in conv5_params + conv4_params, net.parameters()) optimizer = torch.optim.SGD([ {'params': base_params}, {'params': net.conv5.parameters(), 'lr': lr * 100}, {'params': net.conv4.parameters(), 'lr': lr * 100}, , lr=lr, momentum=0.9)
一些简洁的网络组织方法:
class _DenseLayer(nn.Sequential): """Basic unit of DenseBlock (using bottleneck layer) """ def __init__(self, num_input_features, growth_rate, bn_size, drop_rate): super(_DenseLayer, self).__init__() self.add_module("norm1", nn.BatchNorm2d(num_input_features)) self.add_module("relu1", nn.ReLU(inplace=True)) self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate, kernel_size=1, stride=1, bias=False)) self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate)) self.add_module("relu2", nn.ReLU(inplace=True)) self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)) self.drop_rate = drop_rate def forward(self, x): new_features = super(_DenseLayer, self).forward(x) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) return torch.cat([x, new_features], 1) class _DenseBlock(nn.Sequential): """DenseBlock""" def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate): super(_DenseBlock, self).__init__() for i in range(num_layers): layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size, drop_rate) self.add_module("denselayer%d" % (i+1,), layer) class _Transition(nn.Sequential): """Transition layer between two adjacent DenseBlock""" def __init__(self, num_input_feature, num_output_features): super(_Transition, self).__init__() self.add_module("norm", nn.BatchNorm2d(num_input_feature)) self.add_module("relu", nn.ReLU(inplace=True)) self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features, kernel_size=1, stride=1, bias=False)) self.add_module("pool", nn.AvgPool2d(2, stride=2)) class DenseNet(nn.Module): "DenseNet-BC model" def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64, bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000): """ :param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper :param block_config: (list of 4 ints) number of layers in each DenseBlock :param num_init_features: (int) number of filters in the first Conv2d :param bn_size: (int) the factor using in the bottleneck layer :param compression_rate: (float) the compression rate used in Transition Layer :param drop_rate: (float) the drop rate after each DenseLayer :param num_classes: (int) number of classes for classification """ super(DenseNet, self).__init__() # first Conv2d self.features = nn.Sequential(OrderedDict([ ("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)), ("norm0", nn.BatchNorm2d(num_init_features)), ("relu0", nn.ReLU(inplace=True)), ("pool0", nn.MaxPool2d(3, stride=2, padding=1)) ])) # DenseBlock num_features = num_init_features for i, num_layers in enumerate(block_config): block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate) self.features.add_module("denseblock%d" % (i + 1), block) num_features += num_layers*growth_rate if i != len(block_config) - 1: transition = _Transition(num_features, int(num_features*compression_rate)) self.features.add_module("transition%d" % (i + 1), transition) num_features = int(num_features * compression_rate) # final bn+ReLU self.features.add_module("norm5", nn.BatchNorm2d(num_features)) self.features.add_module("relu5", nn.ReLU(inplace=True)) # classification layer self.classifier = nn.Linear(num_features, num_classes) # params initialization for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight) elif isinstance(m, nn.BatchNorm2d): nn.init.constant_(m.bias, 0) nn.init.constant_(m.weight, 1) elif isinstance(m, nn.Linear): nn.init.constant_(m.bias, 0) def forward(self, x): features = self.features(x) out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1) out = self.classifier(out) return out def densenet121(pretrained=False, **kwargs): """DenseNet121""" model = DenseNet(num_init_features=64, growth_rate=32, block_config=(6, 12, 24, 16), **kwargs) if pretrained: # '.'s are no longer allowed in module names, but pervious _DenseLayer # has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'. # They are also in the checkpoints in model_urls. This pattern is used # to find such keys. pattern = re.compile( r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$') state_dict = model_zoo.load_url(model_urls['densenet121']) for key in list(state_dict.keys()): res = pattern.match(key) if res: new_key = res.group(1) + res.group(2) state_dict[new_key] = state_dict[key] del state_dict[key] model.load_state_dict(state_dict) return model densenet = densenet121(pretrained=True) densenet.eval() img = Image.open("./images/cat.jpg") trans_ops = transforms.Compose([ transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) images = trans_ops(img).view(-1, 3, 224, 224) outputs = densenet(images) _, predictions = outputs.topk(5, dim=1) labels = list(map(lambda s: s.strip(), open("./data/imagenet/synset_words.txt").readlines())) for idx in predictions.numpy()[0]: print("Predicted labels:", labels[idx])
DenseNet:比ResNet更优的CNN模型
@author: wujiyang @contact: wujiyang@hust.edu.cn @file: spherenet.py @time: 2018/12/26 10:14 @desc: A 64 layer residual network struture used in sphereface and cosface, for fast convergence, I add BN after every Conv layer. ''' import torch import torch.nn as nn class Block(nn.Module): def __init__(self, channels): super(Block, self).__init__() self.conv1 = nn.Conv2d(channels, channels, 3, 1, 1, bias=False) self.bn1 = nn.BatchNorm2d(channels) self.prelu1 = nn.PReLU(channels) self.conv2 = nn.Conv2d(channels, channels, 3, 1, 1, bias=False) self.bn2 = nn.BatchNorm2d(channels) self.prelu2 = nn.PReLU(channels) def forward(self, x): short_cut = x x = self.conv1(x) x = self.bn1(x) x = self.prelu1(x) x = self.conv2(x) x = self.bn2(x) x = self.prelu2(x) return x + short_cut class SphereNet(nn.Module): def __init__(self, num_layers = 20, feature_dim=512): super(SphereNet, self).__init__() assert num_layers in [20, 64], 'SphereNet num_layers should be 20 or 64' if num_layers == 20: layers = [1, 2, 4, 1] elif num_layers == 64: layers = [3, 7, 16, 3] else: raise ValueError('sphere' + str(num_layers) + " IS NOT SUPPORTED! (sphere20 or sphere64)") filter_list = [3, 64, 128, 256, 512] block = Block self.layer1 = self._make_layer(block, filter_list[0], filter_list[1], layers[0], stride=2) self.layer2 = self._make_layer(block, filter_list[1], filter_list[2], layers[1], stride=2) self.layer3 = self._make_layer(block, filter_list[2], filter_list[3], layers[2], stride=2) self.layer4 = self._make_layer(block, filter_list[3], filter_list[4], layers[3], stride=2) self.fc = nn.Linear(512 * 7 * 7, feature_dim) self.last_bn = nn.BatchNorm1d(feature_dim) for m in self.modules(): if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear): if m.bias is not None: nn.init.xavier_uniform_(m.weight) nn.init.constant_(m.bias, 0) else: nn.init.normal_(m.weight, 0, 0.01) def _make_layer(self, block, inplanes, planes, num_units, stride): layers = [] layers.append(nn.Conv2d(inplanes, planes, 3, stride, 1)) layers.append(nn.BatchNorm2d(planes)) layers.append(nn.PReLU(planes)) for i in range(num_units): layers.append(block(planes)) return nn.Sequential(*layers) def forward(self, x): x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = x.view(x.size(0), -1) x = self.fc(x) x = self.last_bn(x) return x if __name__ == '__main__': input = torch.Tensor(2, 3, 112, 112) net = SphereNet(num_layers=64, feature_dim=512) out = net(input) print(out.shape)
Face_Pytorch/backbone/spherenet.py
分离含有BN层的参数:
def separate_bn_paras(modules):
if not isinstance(modules, list):
modules = [*modules.modules()]
paras_only_bn = []
paras_wo_bn = []
for layer in modules:
if 'model' in str(layer.__class__):
continue
if 'container' in str(layer.__class__):
continue
else:
if 'batchnorm' in str(layer.__class__):
paras_only_bn.extend([*layer.parameters()])
else:
paras_wo_bn.extend([*layer.parameters()])
return paras_only_bn, paras_wo_bn
冻结BN层的beta和gamma,也就是weights和bias:
def set_bn_eval(m): classname = m.__class__.__name__ if classname.find('BatchNorm') != -1: m.eval() model.apply(set_bn_eval)
固定BN均值方差或者beta和gamma的统一形式可表示为:
def train(self, mode=True): """ Override the default train() to freeze the BN parameters """ super(MyNet, self).train(mode) if self.freeze_bn: print("Freezing Mean/Var of BatchNorm2D.") if self.freeze_bn_affine: print("Freezing Weight/Bias of BatchNorm2D.") if self.freeze_bn: for m in self.backbone.modules(): if isinstance(m, nn.BatchNorm2d): m.eval() if self.freeze_bn_affine: m.weight.requires_grad = False m.bias.requires_grad = False
一个ReID的强baseline,有许多trick,以及学习率,采样等超参的设计:
知乎:一个更加强力的ReID Baseline
代码:reid-strong-baseline
Pytorch中Module类中的register_buffer(name, tensor) 用法:
- you want a stateful part of your model that is not a parameter, but you want it in your state_dict
就是需要将某部分参数作为网络的一部分,但不作为parameter进计算梯度、并反向传播。但是又要保存在state_dict中。
参考: Use and Abuse of .register_buffer( ) 、Pytorch模型中的parameter与buffer
‘model.eval()’ vs ‘with torch.no_grad()’ 的区别:测试时
model.eval()
for batch in val_loader:
#some code
或者:
model.eval()
with torch.no_grad():
for batch in val_loader:
#some code
都是可以的。后者因为无需计存储任何中间变量可以更节省内存。eval改变bn和dropout的操作,而torch.no_grad() 和自动求导机制有关,可以阻止计算梯度。
from torchvision import models res=models.resnet50(False) f=nn.Sequential(*list(res.children())[:-2]) s=torch.randn(16,3,256,256) f(s).shape
torch.utils.data.TensorDataset()函数用法:参考
class TensorDataset(Dataset): """Dataset wrapping tensors. Each sample will be retrieved by indexing tensors along the first dimension. Arguments: *tensors (Tensor): tensors that have the same size of the first dimension. """ def __init__(self, *tensors): assert all(tensors[0].size(0) == tensor.size(0) for tensor in tensors) self.tensors = tensors def __getitem__(self, index): return tuple(tensor[index] for tensor in self.tensors) def __len__(self): return self.tensors[0].size(0) 可以看到它把之前的data_tensor 和target_tensor去掉了,输入变成了元组×tensors,只需将data和target直接输入到函数中就可以。 附一个例子: import torch import torch.utils.data as Data BATCH_SIZE = 5 x = torch.linspace(1, 10, 10) y = torch.linspace(10, 1, 10) torch_dataset = Data.TensorDataset(x, y) loader = Data.DataLoader( dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2, ) for epoch in range(3): for step, (batch_x, batch_y) in enumerate(loader): print('Epoch: ', epoch, '| Step: ', step, '| batch x: ', batch_x.numpy(), '| batch y: ', batch_y.numpy()) ———————————————— 版权声明:本文为CSDN博主「l770796776」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/l770796776/article/details/81261981
pytorch中划分划分训练验证集:
利用torch.utils.data.random_split
1 import torch 2 from torchvision import datasets, transforms 3 4 batch_size = 200 5 6 """读取训练集和测试集""" 7 train_db = datasets.MNIST('../data', train=True, download=True, 8 transform=transforms.Compose([ 9 transforms.ToTensor(), 10 transforms.Normalize((0.1307,), (0.3081,)) 11 ])) 12 13 test_db = datasets.MNIST('../data', train=False, 14 transform=transforms.Compose([ 15 transforms.ToTensor(), 16 transforms.Normalize((0.1307,), (0.3081,)) 17 ])) 18 19 20 print('train:', len(train_db), 'test:', len(test_db)) 21 22 """将训练集划分为训练集和验证集""" 23 train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000]) 24 print('train:', len(train_db), 'validation:', len(val_db)) 25 26 27 # 训练集 28 train_loader = torch.utils.data.DataLoader( 29 train_db, 30 batch_size=batch_size, shuffle=True) 31 # 验证集 32 val_loader = torch.utils.data.DataLoader( 33 val_db, 34 batch_size=batch_size, shuffle=True) 35 # 测试集 36 test_loader = torch.utils.data.DataLoader( 37 test_db, 38 batch_size=batch_size, shuffle=True)
ref: How do I split a custom dataset into training and test datasets?
pytorch 利用ddp分布式训练:
train.py单机4个gpu时用法:python3 train.py -g 4
ref:
1)https://yangkky.github.io/2019/07/08/distributed-pytorch-tutorial.html 对应code:https://github.com/yangkky/distributed_tutorial/blob/master/src/mnist-mixed.py
2)https://pytorch.apachecn.org/docs/1.0/dist_tuto.html
3)https://zhuanlan.zhihu.com/p/98535650
4)https://github.com/narumiruna/pytorch-distributed-example/blob/master/mnist/main.py
horvord pytorch 分布式训练
貌似速度和上面的ddp相近,所以一般可以直接用原生的ddp:
horvord官方mnist,可直接跑。https://github.com/horovod/horovod/blob/master/examples/pytorch_mnist.py
用法:
# run training with 4 GPUs on a single machine $ horovodrun -np 4 python train.py # 单机4个gpu # run training with 8 GPUs on two machines (4 GPUs each) $ horovodrun -np 8 -H hostname1:4,hostname2:4 python train.py # 两机,每台4gpu
ref:
1)https://horovod.readthedocs.io/en/stable/pytorch.html
2)https://github.com/horovod/horovod
英伟达 dali加速库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号