Joint Discriminative and Generative Learning for Person Re-identification
关于利用GAN做行人ReID的文章:
[NIPS-2018] FD-GAN: Pose-guided Feature Distilling GAN for Robust Person Re-identification。
[CVPR2019] Joint Discriminative and Generative Learning for Person Re-identification.
两篇paper代码均以开源,本文简要分析后者,在GAN生成行人数据做的比较好,提升非常明显。文中提到之前利用GAN做reid都是分离式的,即先利用GAN生成数据,然后训练所有的数据。而文中提出一个统一框架将生成模型合并到特征学习模型中,端到端训练在线利用生成的数据训练。所提出的生成器模型将每个行人图分解成appearance部分和structure部分。判别器和生成器共享appearance部分。通过转换appearance和structure部分,可以是生成器生成高质量交叉id的图像,然后输入到appearance编码器取提升判别器。
下图是appearance和structure组合:

appearance和structure主要负责编码的内容:
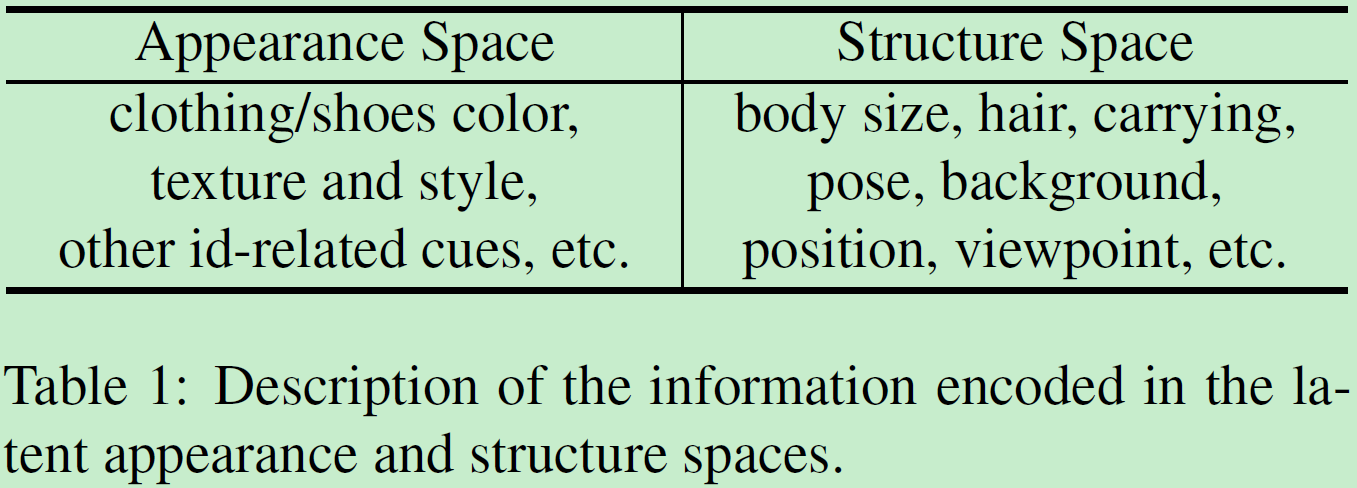
即appearance负责外表和其他和id身份有关的信息,structure负责几何位置信息。所有模块是联合训练,在线生成的图片在线利用。是首个端到端嵌入判别器和生成器在同一框架的reid结构。整体结构如图:
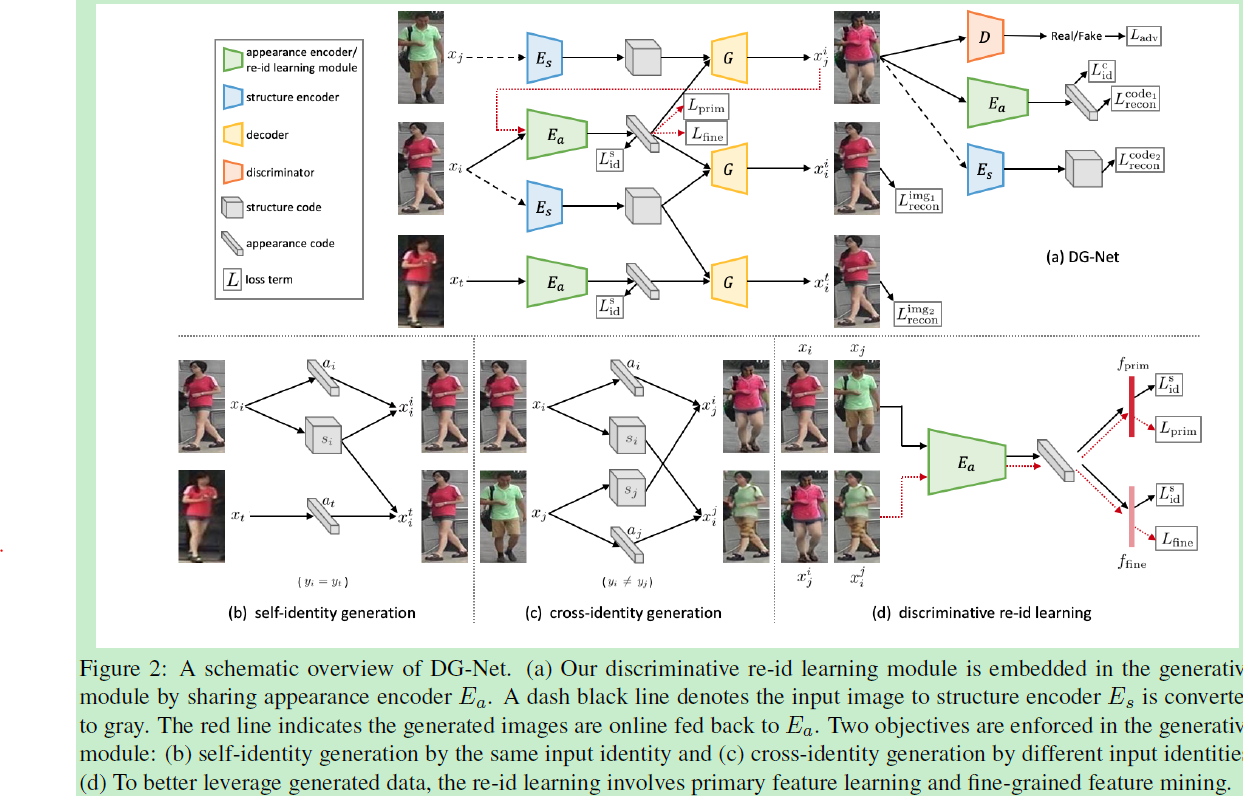
文中生成器负责图像生成,判别器用于reid学习。生成器包括两种图像映射:同一id映射和跨id映射。判别器包括特征学习和细粒度学习特征挖掘。一个个人觉得比较重要的点:由于在生成一张图时需要一个appearance编码和一个structure编码,所以有可能会在学习过程中网络只利用structure的信息而忽略了appearance的信息,所以为了避免这种平凡解,在利用structure时,将图像转换为灰度图,这样迫使网络必须也从appearance中学习。
1. 生成器部分 :7个loss
损失极其多。第一个loss是同等映射。就是由图A生成图A,即要保证生成器的重构能力。第二个loss是交叉重构。即对于同一id的不同图片进行重构,这个loss鼓励appearance编码器将同一id的appearance拉近。来减少特征类内方差。同时第三个loss是分类损失,保证所有同一appearance的不同图像属于同一类。前三个loss针对同一id,接下类三个loss都是针对跨id。第四个loss约束相同appearance的两个不同id的appearance相近。第五个loss约束相同structure的两个不同id的structure相近。由于appearance决定了id,所以第六个loss也是分类损失·,所有生成的appearance相同的图像都应属于一类。第七个loss为对抗损失,就是生成器和判别器的损失。
2. 判别器部分 :2个loss
判别器部份通过共享appearance编码器嵌入到生成器模块。和生成器通过转换appearance和structure来生成图像一样,判别器部分包括primary特征学习和fine-grained特征挖掘来更好利用在线生成的图像。这个模块如图(d)所示,单拎出来在图(d)。
Primary feature learning:可以按照已有的工作将生成的图作为训练样本,但是不同id的类间方差促使我们采取一种伴随动态软标签的教师-学生类型的监督。利用一个教师模型来动态赋予软标签。教师模型是利用原有训练数据集训练的一个分类基线模型。通过最小化KL divergence来最小化判别器预测的分布和教师模型预测的分布差异。
Fine-grained feature mining:直接利用生成的数据用于学习primary特征之外,一个有趣的方案是估计同一个人的衣服变化。此时判别器将被强制学习细粒度相关的属性,例如头发,包,身材等,是与衣服独立的。利用分类损失来优化。实现了自动属性挖掘。
效果对比:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号