
数据采集第三次大作业1
数据挖掘第三次实践
作业一
天气图片爬取实验
作业内容
指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
实践过程
主要思路,首先观察网站不难发现,中国气象网内部的url都存在a标签下的href标签中
urls = soup.select("a") for url in urls: i = url["href"]
通过以上代码可以遍历中国气象网内部的所有网站
images = soup.select("img") for image in images: try: src = image["src"]
再通过遍历每个网站下的所有img标签将所有图片的url存入列表当中,接下来我们只要将存有图片url的列表传入我们写好的download函数当中即可
代码部分:
def imageSpider(start_url): try: req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") urls = soup.select("a") for url in urls: i = url["href"] print(i) try: if count > 126: break req = urllib.request.Request(i, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "lxml") images = soup.select("img") for image in images: try: src = image["src"] print(src) url = urllib.request.urljoin(start_url, src) download(url) if count > 126: break except Exception as err: print(err) except Exception as err: print(err) except Exception as err: print(err)
def download(url): global count try: if url[len(url) - 4] == ".": ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("images\\" + str(count) + ext, "wb") fobj.write(data) fobj.close() print("正在下载第" + str(count) + "张" + ext + "图片" ) count = count + 1 except Exception as err: print(err)
单线程爬虫与多线程爬虫的实现大差不差 ,这里就不过分赘述了,详情请查看完整代码
结果截图: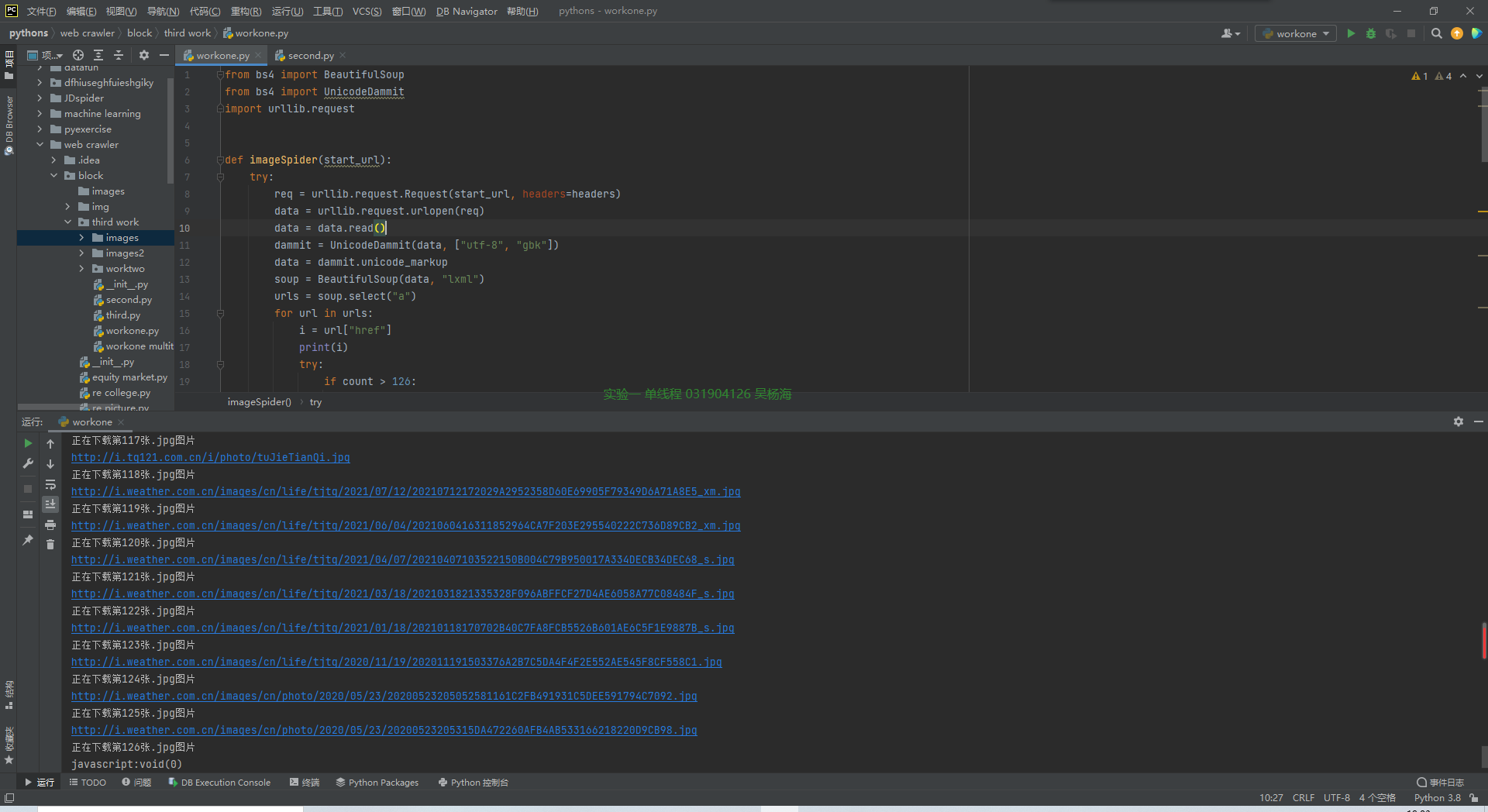
心得体会:
在实现多线程爬取的过程中,我们通常会使用Thread函数中的args参数传入我们已经存好的url列表,但是在使用的过程中由于出现了不明的原因,导致代码出现以下的报错,函数会将一个完整的url中的每个字符都识别为一个参数,解决该问题的方法是,在args参数中多传递一个参数,具体是什么参数不重要,重要的是不能使用args仅仅传递一个url,否则便会出现以下的报错。

代码地址:
https://gitee.com/kilig-seven/crawl_project/blob/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/workone.py
https://gitee.com/kilig-seven/crawl_project/blob/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/workone%20mul.py
作业二
天气图片爬取实验(scrapy框架)
作业内容
使用scrapy框架复现作业①。
实践过程
大致爬取思路与作业一相同,我们只需要在scrapy框架下重现即可
代码部分:
爬虫主体:
class WeatherSpidersSpider(scrapy.Spider): name = 'weather_spiders' #allowed_domains = ['http://p.weather.com.cn/zrds/index.shtml'] start_urls = ['http://p.weather.com.cn/zrds/index.shtml'] def parse(self, response): urls = response.xpath('//div[@class="tu"]/a/@href').extract() for url in urls: yield scrapy.Request(url=url, callback=self.imgs_parse) def imgs_parse(self, response): item = WeatherItem() #获取对应图片的链接 item["pic_url"] = response.xpath('/html/body/div[3]/div[1]/div[1]/div[2]/div/ul/li/a/img/@src').extract() yield item
items部分:
class WeatherItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pic_url = scrapy.Field()
pipelines部分:
class WeatherPipeline(ImagesPipeline): def get_media_requests(self, item, info): for i in range(len(item['pic_url'])): yield scrapy.Request(url=item['pic_url'][i]) def item_completed(self, results, item, info): if not results[0][0]: raise DropItem('下载失败') return item
结果截图:
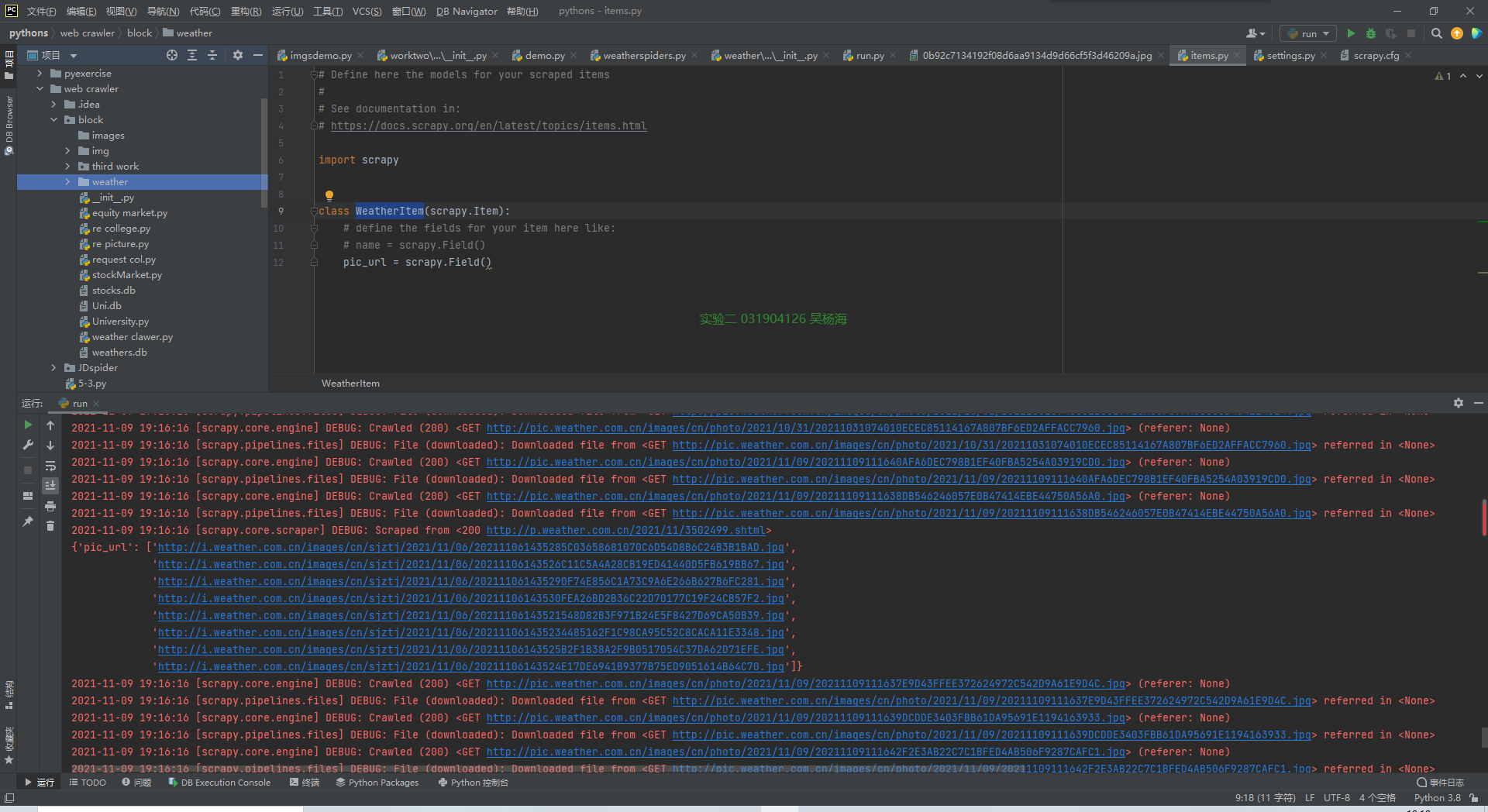
心得体会:
复现了相同代码在scrapy框架下的实现,重温了xpath的语法规则
代码地址:
https://gitee.com/kilig-seven/crawl_project/tree/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/%E4%BD%9C%E4%B8%9A%E4%BA%8Cscrapy
作业三
豆瓣电影信息实验
作业内容
爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在imgs路径下。
实践过程
主要思路,在该网站下找到我们所需要的信息的路径,爬取并存入列表当中,再用数据库的方法将信息保存下来
代码部分:
爬虫主体:
class DouSpidersSpider(scrapy.Spider): name = 'douban_spiders' allowed_domains = ['movie.douban.com'] start_urls = ['https://movie.douban.com/top250'] def parse(self, response): item = DoubanItem() title = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()').extract() # 多个span标签 movieInfo = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]').extract() star = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()').extract() quote = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()').extract() pic = response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li/div/div[1]/a/img/@src').extract() directors = [] actors = [] for list in movieInfo: list = list.replace("\n", "") director = re.findall(r'导演: (.*?)\xa0', list) directors.append(director) actor = re.findall(r'主演: (.*?)[\./]', list) actors.append(actor) item['movieinfo'] = movieInfo item['title'] = title item['director'] =directors item['actor'] = actors item['star'] = star item['quote'] = quote item['pic'] =pic yield item
items部分:
class DoubanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() # 电影名字 director = scrapy.Field() # 导演 movieinfo = scrapy.Field() actor = scrapy.Field()#演员 star = scrapy.Field()#分数 quote = scrapy.Field()#简介 pic = scrapy.Field()#电影封面
pipelines部分:
class DoubanPipeline(object): def process_item(self, item, spider): # movieinfo = item["movieinfo"] title = item["title"] director = item["director"] actor = item["actor"] star = item["star"] quote = item["quote"] pic = item["pic"] os.mkdir("./img/") moviedb = movieDB() # 创建数据库对象 moviedb.openDB() # 打开数据库 for i in range(len(title)): print(str(i + 1) + "\t" + title[i] + "\t" + director[i][0] + "\t" + actor[i][0] + "\t" + quote[i] + "\t" +star[i] + "\t\t" + pic[i]) moviedb.insert(i + 1, title[i], director[i][0], actor[i][0], quote[i], star[i], pic[i]) urllib.request.urlretrieve(pic[i], "./img/" + title[i] + ".jpg") print("成功存入数据库") moviedb.closeDB() # 关闭数据库
数据库部分:
class movieDB: def openDB(self): self.con = sqlite3.connect("movie.db") # 连接数据库,没有的话会注定创建一个 self.cursor = self.con.cursor() # 设置一个游标 try: self.cursor.execute("create table movies(排名 varchar(10),电影名称 varchar(16),导演 varchar(20),主演 varchar(20),简介 varchar(50),分数 varchar(10),电影封面 varchar(50))") # 创建电影表 except: self.cursor.execute("delete from movies") def closeDB(self): self.con.commit() self.con.close() # 关闭数据库 def insert(self,Rank,Name,Director,Actor,State,Score,Surface): try: self.cursor.execute("insert into movies(排名,电影名称,导演,主演,简介,分数,电影封面) values (?,?,?,?,?,?,?)", (Rank, Name, Director, Actor, State, Score, Surface)) # 插入数据 except Exception as err: print(err)
结果截图:

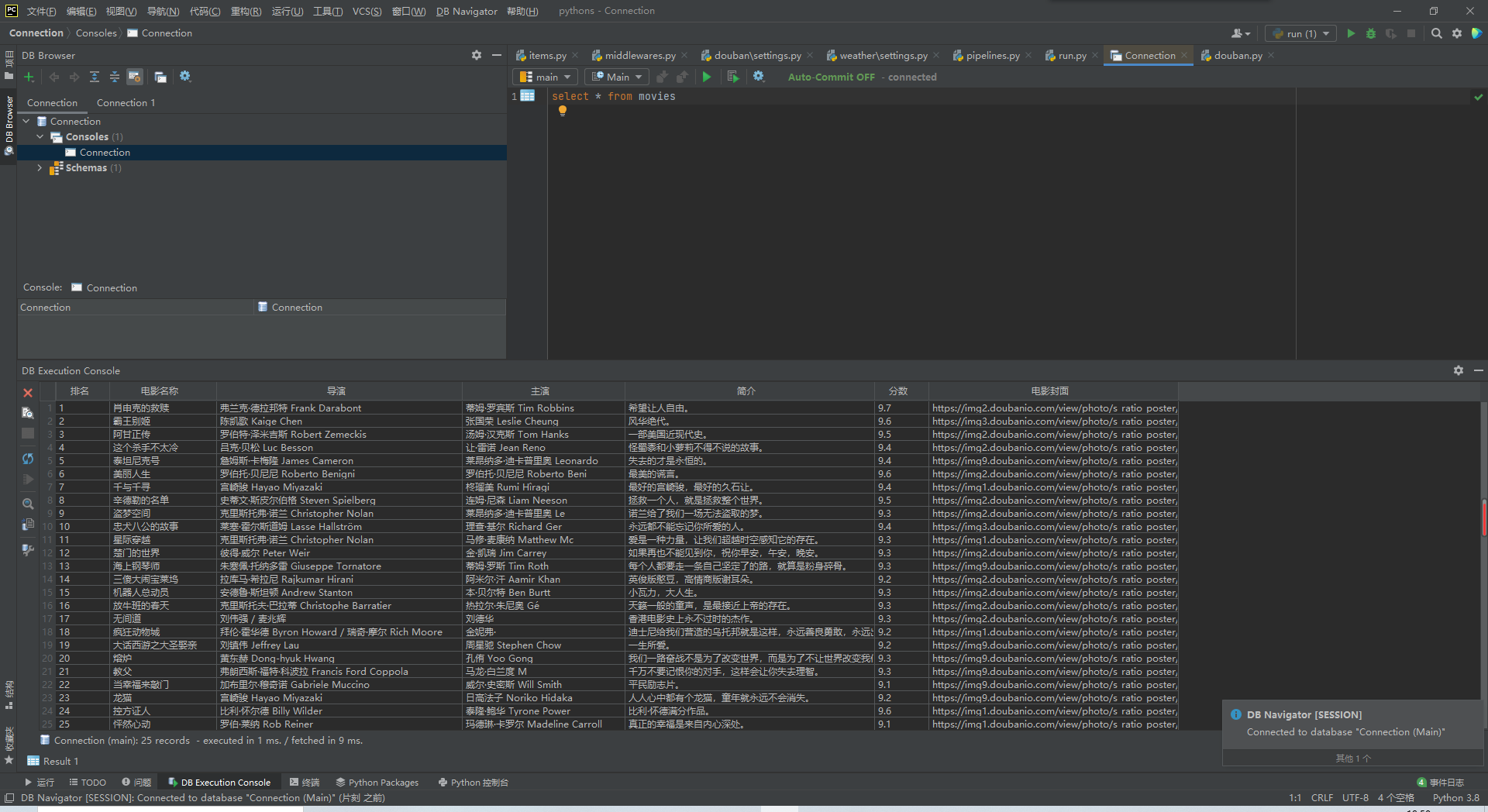
心得体会:
在经过了多次爬取的作业后,发现,大部分时候爬取的不同点在于每次需要的信息不同,这就需要我们通过xpath或是正则的不同语法来爬取我们所需要的内容,而在存储信息方式,大部分时候代码都是大差不差的,我们只需要考虑重新设计数据库的格式等方面即可。所以i,倘若是做好此方面的框架,我们在每次爬取的过程当中只需要对之前的代码进行微小的重构即可
代码地址:
https://gitee.com/kilig-seven/crawl_project/tree/master/%E7%AC%AC%E4%B8%89%E6%AC%A1%E5%A4%A7%E4%BD%9C%E4%B8%9A/%E4%BD%9C%E4%B8%9A%E4%B8%89scrapy

