

day1--心得


1 info = ''' 2 --------------------info of %s---------------- 3 name: %s 4 age: %s 5 job: %s 6 ------------------------------------------ 7 8 ''' % (name,name,age,job) 9 print(info) 10 11 info2 = ''' 12 --------------------info2 of {_name}---------------- 13 name: {_name} 14 age: {_age} 15 job: {_job} 16 ------------------------------------------ 17 18 ''' .format(_name = name, 19 _age = age, 20 _job = job 21 22 ) 23 24 print(info2)
以上有2中方式
------------------------------------------------------
输入密码时,如果想要不可见,需要利用getpass 模块中的 getpass方法,即:
1 #!/usr/bin/env python 2 # -*- coding: utf-8 -*- 3 4 import getpass 5 6 # 将用户输入的内容赋值给 name 变量 7 pwd = getpass.getpass("请输入密码:") 8 9 # 打印输入的内容 10 print(pwd)
strip() 方法用于移除字符串头尾指定的字符(默认为空格)
1 password = getpass.getpass("input your password\n:>>>").strip()
-----------------------------------------
py2与3的详细区别
1 Old: print "The answer is", 2*2 New: print("The answer is", 2*2) 2 Old: print x, # Trailing comma suppresses newline New: print(x, end=" ") # Appends a space instead of a newline 3 Old: print # Prints a newline 4 New: print() # You must call the function! 5 Old: print >>sys.stderr, "fatal error" New: print("fatal error", file=sys.stderr) 6 Old: print (x, y) # prints repr((x, y)) 7 New: print((x, y)) # Not the same as print(x, y)!
库改名字了:
|
Old Name |
New Name |
|
_winreg |
winreg |
|
ConfigParser |
configparser |
|
copy_reg |
copyreg |
|
Queue |
queue |
|
SocketServer |
socketserver |
|
markupbase |
_markupbase |
|
repr |
reprlib |
|
test.test_support |
test.support |
----------------------------------------------
Python注释:
当行注视:# 被注释内容
多行注释:""" 被注释内容 """
---------------------------------------------
python在linux下的补全
1 #!/usr/bin/env python 2 # python startup file 3 import sys 4 import readline 5 import rlcompleter 6 import atexit 7 import os 8 # tab completion 9 readline.parse_and_bind('tab: complete') 10 # history file 11 histfile = os.path.join(os.environ['HOME'], '.pythonhistory') 12 try: 13 readline.read_history_file(histfile) 14 except IOError: 15 pass 16 atexit.register(readline.write_history_file, histfile) 17 del os, histfile, readline, rlcompleter 18 19 for Linux
1 ocalhost:~ jieli$ python 2 Python 2.7.10 (default, Oct 23 2015, 18:05:06) 3 [GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwin 4 Type "help", "copyright", "credits" or "license" for more information. 5 >>> import tab
上面自己写的tab.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫 Python/2.7/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表
--------------------------------------------
range:
1 for i in range(0,10,2): 2 if i <5: 3 print("loop",i) 4 else: 5 continue 6 print("hehe")
--------------------------------------------
python中的三个读read(),readline()和readlines()
Python 将文本文件的内容读入可以操作的字符串变量非常容易。文件对象提供了三个“读”方法: .read()、.readline() 和 .readlines()。每种方法可以接受一个变量以限制每次读取的数据量,但它们通常不使用变量。 .read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。然而 .read() 生成文件内容最直接的字符串表示,但对于连续的面向行的处理,它却是不必要的,并且如果文件大于可用内存,则不可能实现这种处理。
.readline() 和 .readlines() 非常相似。它们都在类似于以下的结构中使用:
Python .readlines() 示例
fh = open( 'c:\\autoexec.bat') for line in fh.readlines(): print line.readline() 和 .readlines()之间的差异是后者一次读取整个文件,象 .read()一样。.readlines()自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for... in ... 结构进行处理。另一方面,.readline()每次只读取一行,通常比 .readlines()慢得多。仅当没有足够内存可以一次读取整个文件时,才应该使用.readline()。
写:
writeline()是输出后换行,下次写会在下一行写。write()是输出后光标在行末不会换行,下次写会接着这行写
1 通过readline输出,对于比较大的文件,这种占用内存比较小。 2 #coding:utf-8 3 4 f = open('poem.txt','r') 5 result = list() 6 for line in open('poem.txt'): 7 line = f.readline() 8 print line 9 result.append(line) 10 print result 11 f.close() 12 open('result-readline.txt', 'w').write('%s' % '\n'.join(result))
1 #coding:utf-8 2 '''cdays-4-exercise-6.py 文件基本操作 3 @note: 文件读取写入, 列表排序, 字符串操作 4 @see: 字符串各方法可参考hekp(str)或Python在线文档http://docs.python.org/lib/string-methods.html 5 ''' 6 7 f = open('cdays-4-test.txt', 'r') #以读方式打开文件 8 result = list() 9 for line in f.readlines(): #依次读取每行 10 line = line.strip() #去掉每行头尾空白 11 if not len(line) or line.startswith('#'): #判断是否是空行或注释行 12 continue #是的话,跳过不处理 13 result.append(line) #保存 14 result.sort() #排序结果 15 print result 16 open('cdays-4-result.txt', 'w').write('%s' % '\n'.join(result)) #保存入结果文件
两个字典合并方法: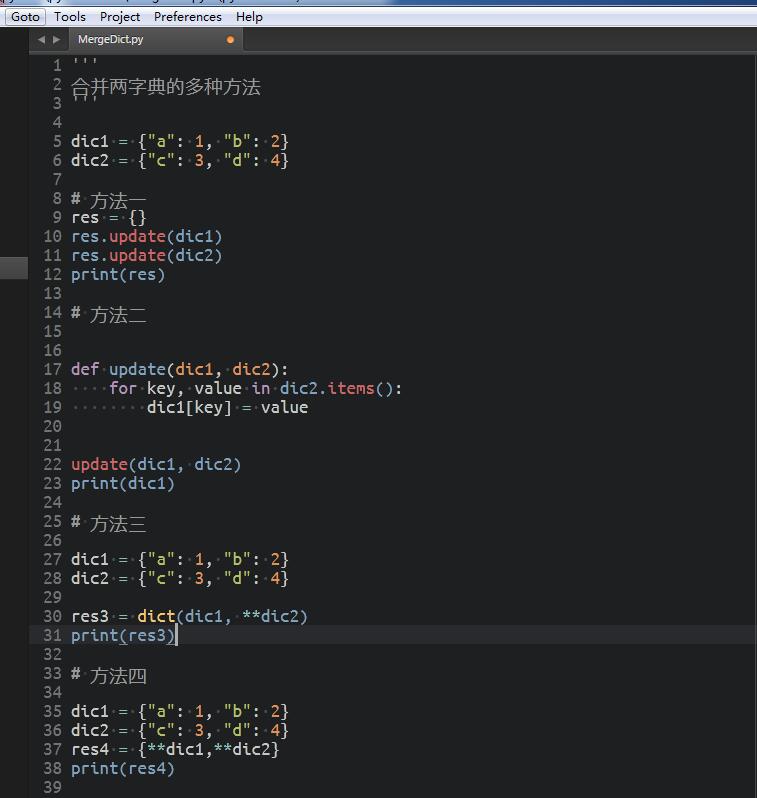

 浙公网安备 33010602011771号
浙公网安备 33010602011771号