


learning to Estimate 3D Hand Pose from Single RGB Images论文理解
概括:以往很多论文借助深度信息将2D上升到3D,这篇论文则是想要用网络训练代替深度数据(设备成本比较高),提高他的泛性,诠释了只要合成数据集足够大和网络足够强,我就可以不用深度信息。
一、论文结构
这篇论文的思路很清晰,主要分为三个部分:
1、HandSegNet
2、PoseNet
3、the PosePrior network
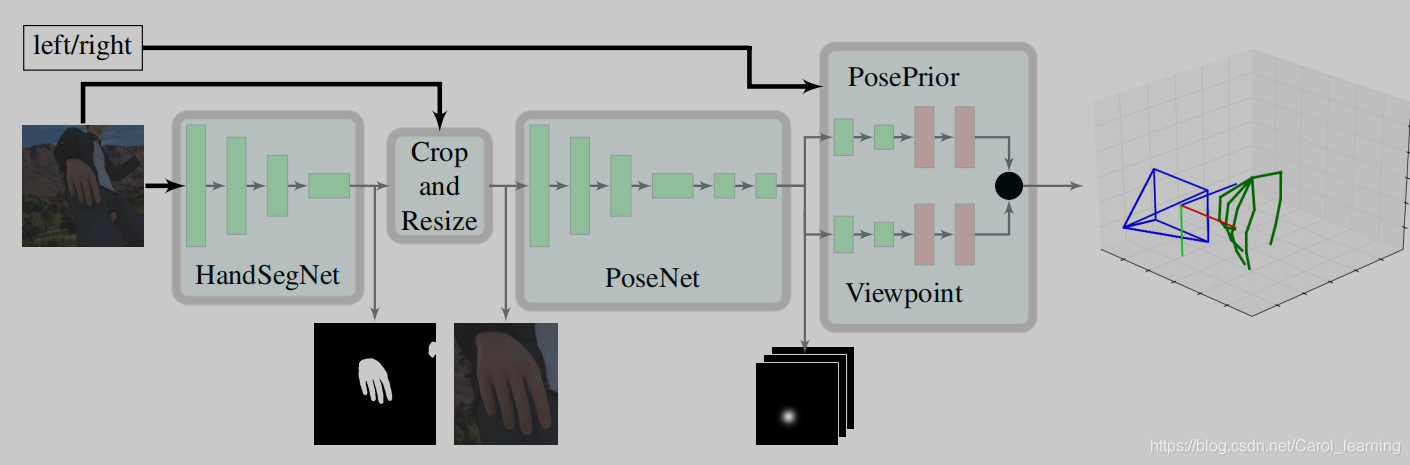
第1、2个网络主要是借助 Convolutional Pose Machines 这篇论文的网络进行设置, 通过卷积图层表达纹理信息和空间信息提取出手的位置(只是对第一个网络添加了二值化处理形成了handmask 的中间输出),由于手势比较小,因此对手的位置进行裁剪成为第二个网络的输入,以类似的方式提取关节的位置(score map)。
本论文的核心是第三个网络,该网络以score map 作为输入,进行网络的训练估计正则化框架WC内的三维坐标,并分别估计旋转矩阵R(Wrel),根据公式反求出wc (rel)。

数据集
1、Stereo Hand Pose Tracking Benchmark
an evaluation set of 3000 images(S-val) and a training set with 15000 images (S-train)
2、自制数据集:(引擎)
a validation set (R-val) and a training set (R-train)
为什么2D数据可以直接通过网络进行3D的估计?
关键在于方法用的是合成数据集(synthetic dataset (R-val) ),什么是合成数据集呢?Unity大家一定不陌生。通过类似Unity的引擎我们可以模拟各种场景、光线下的人物,根据自己的需要去制作大量的数据集,解决计算机视觉领域缺少数据集的短板。但是,这只是合成数据集的其中一个好处,最大的好处在于由于我们通过引擎模拟人物,那么这个人物的数据我们是有的,即我们可以知道人物三维手势各个关节的相对位置和绝对位置(ground truth),因此我们可以通过这些数据进行训练,从而达到不用深度数据就可以3D训练的效果。
为什么要用一个canonical frame呢?
论文中这样定义:
给定一个颜色图像I∈RN×M3显示一只手,我们想推断它的三维姿态。 我们用一组坐标wi=(xi,yi,zi)来定义手姿,它描述了J关键点在三维空间中的位置,即在我们的情况下,用J=21来∈[1,J]。


s将某对关键点之间的距离归一化为单位长度。

深度数据限制了我们可以脱离整个图像,如果不用深度数据,我们的目光就只需要针对一只手,以手建立对象来研究他的属性。论文中,作者将关节之间的距离归一化,并且手心关节这一个关键点作为标志(land mark),计算其他关节到手心关节点的距离,从而构成一个canonical frame。第三层网络则是不断将canonical frame测量值和ground truth 采用L2 损失对两个估计值WC内的三维坐标和旋转矩阵R(Wrel)进行训练。
为什么要用旋转矩阵将视角统一?
我的理解是如果将视角统一,那么手势的所有可能形式将大大地减少,这样子网络训练准确率将提高。
二、代码框架
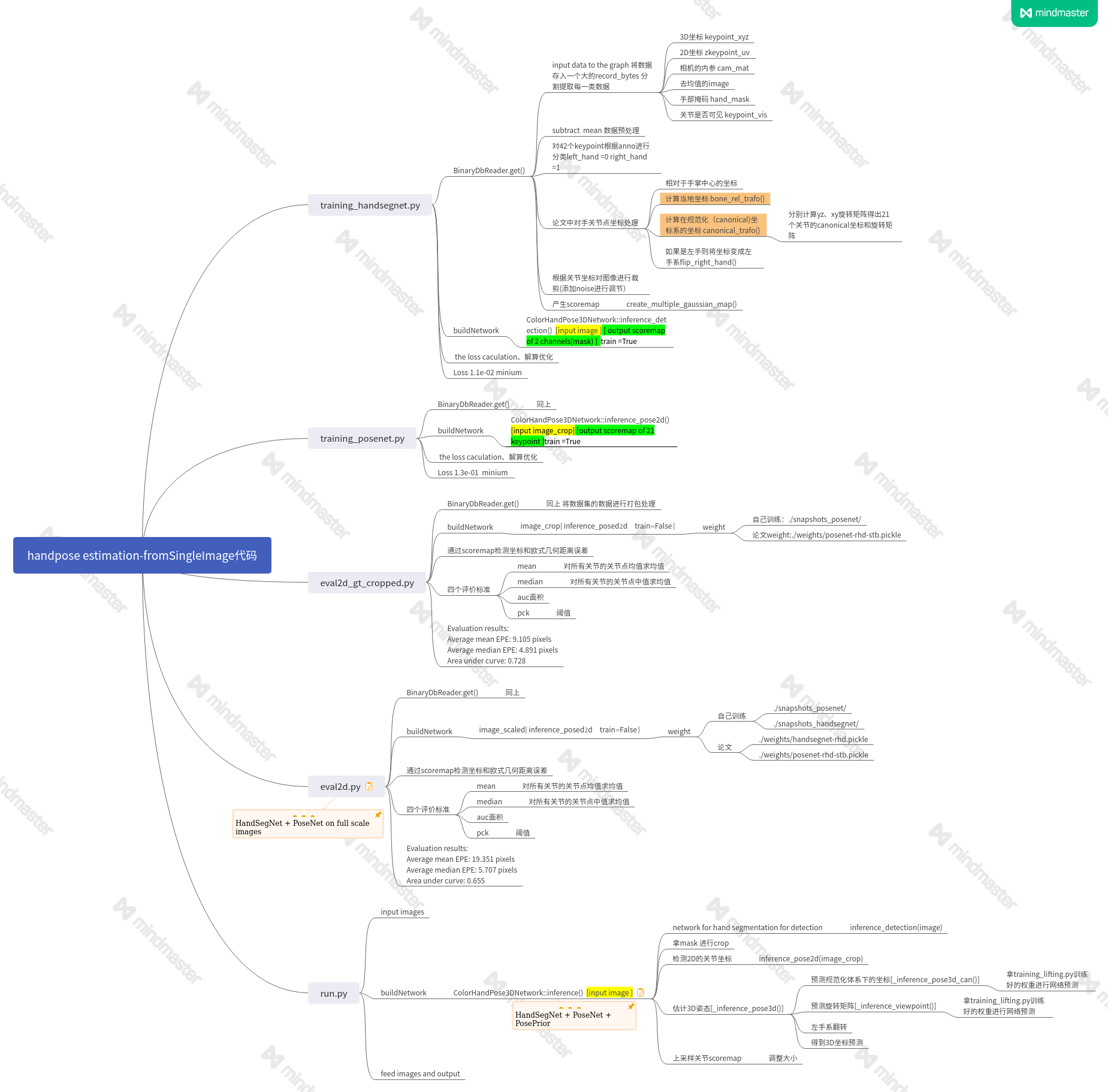
代码中的小问题和自我消化
session 的理解
session是tensorflow的一个开关函数,对于整一个神经网络,他将权重,网络结构准备好,通过y = F(G(x..))进行设置,然后通过session.run()进行启动。这里的y相当于句柄。
A,B,C = session.run([a],[b],[c])
其中a句柄的函数run之后return给A,b句柄的函数run之后return给B,c句柄的函数run之后return给C,一一对应。
cost = np.squeeze(cost) 的作用?
def compute_cost(A2, Y, parameters):
m = Y.shape[1] #样例的数量
#计算交叉熵损失
logprobs = np.multiply(np.log(A2), Y) + np.multiply(np.log(1 - A2), 1 - Y)
cost = -1 / m * np.sum(logprobs)
cost = np.squeeze(cost) #确保损失函数是我们期望的维度
因为算法出来的结果通常是可以表示向量的数组,比如,array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]),通过np.squeeze() 删除数组形状中的单维度条目,变成array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),对后面的处理比较方便,画图也是需要去除单维度条目。
对于权重的问题?
看完整个代码不太清楚代码将pickle文件读入读取权重后将权重放到了哪里,找不到相应的变量,初步理解是tf内部框架的处理,通过train=True or False,决定是否采用权重,而权重也是通过框架进行输入。
init_op, init_feed = tf.contrib.framework.assign_from_values(weight_dict)
session.run(init_op, init_feed)
trainning_seg 为什么要添加噪声?
在代码中看到作者设定了坐标和裁剪的noise,估计只是预留一下误差的微调,里面对于noise的参数都是false,如果参数是True,那么计算后对应的值要加上高斯随机产生的量。
将噪声输入到网络中,避免过拟合,减小进入局部最优化的可能性。
为什么前面num_kp = 42?
因为是包括左手和右手,之后通过检测到的关节序列主要分布来确定是左手还是右手,之后就变成量num_kp = 21 啦
subtract mean 减去平均!数据增强
image = image / 255.0 - 0.5
if self.hue_aug:
# 随机调整图像色调
image = tf.image.random_hue(image, self.hue_aug_max)
data_dict['image'] = image
如果是image - mean 则是减去平均亮度,这里只是为了输入网络的值不要太大,使得处理比较方便。
以下是摘录
这种归一化可以移除图像的平均亮度值 (intensity)。很多情况下我们对图像的照度并不感兴趣,而更多地关注其内容,比如在对象识别任务中,图像的整体明亮程度并不会影响图像中存在的是什么物体。这时对每个数据点移除像素的均值是有意义的。
如果输入层 x 很大,在反向传播时候传递到输入层的梯度就会变得很大。梯度大,学习率就得非常小,否则会越过最优。在这种情况下,学习率的选择需要参考输入层数值大小,而直接将数据归一化操作,能很方便的选择学习率。
为什么可以实现关节的链接?
通过字典。
kinematic_chain_dict = {0: 'root',
4: 'root',
3: 4,
2: 3,
1: 2,
8: 'root',
7: 8,
6: 7,
5: 6,
12: 'root',
11: 12,
10: 11,
9: 10,
16: 'root',
15: 16,
14: 15,
13: 14,
20: 'root',
19: 20,
18: 19,
17: 18}
#order in which we will calculate stuff
kinematic_chain_list = [0,
4, 3, 2, 1,
8, 7, 6, 5,
12, 11, 10, 9,
16, 15, 14, 13,
20, 19, 18, 17]
先设定好每个关节的处理顺序,通过类似树的形式child-parent一对一进行对应,实现相对坐标的运算和关节连接。
论文中scoremap是一张图片21个channel还是一个图片21个关节一个输出?
输出是一个张量,最后一个维度是21, 表示不同关节点的scoremap,即之后只要不同关节的scoremap求出最大值,就可以找出坐标值。
AUC
如果要计算accuracy,需要先把概率转化成类别,这就需要手动设置一个阈值,如果对一个样本的预测概率高于这个预测,就把这个样本放进一个类别里面,低于这个阈值,放进另一个类别里面。所以这个阈值很大程度上影响了accuracy的计算。使用AUC或者logloss可以避免把预测概率转换成类别。
AUC是Area under curve的首字母缩写。这个曲线有个名字,叫ROC曲线。
AUC对样本类别是否均衡并不敏感,这也是不均衡样本通常用AUC评价分类器性能的一个原因。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号