机器学习之分类和聚类的区别
一、概念
分类:通过训练集训练出来一个模型,用于判断新输入数据的类型,而在训练的过程中,一定需要有标签的数据,即训练集本身就带有标签。简单来说,用已知的数据来对未知的数据进行划分。这是一种有监督学习。
聚类:对于一组数据,你根本不知道数据之间的关系,不知道他们是否属于同一类,抑或属于不同类别,也不知道到底可以分为多少类。这个时候,我们就需要聚类算法来对数据进行一个关系分析,通过聚类,我们可以把未知类别的数据,分为一类或者多类,这个过程是不需要标签的,这是一种无监督学习。
二、区别
给出一张图简要道出两者区别,图片来源:https://www.zhihu.com/question/42044303/answer/470589507
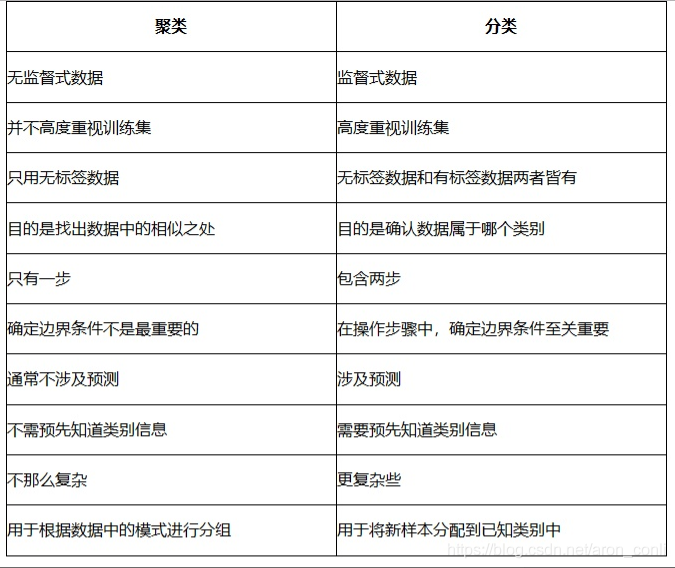
解释一下第五条:步数问题
对于分类问题,首先需要使用带标签的训练集来训练一个分类器出来,然后再将要分类的数据输入到分类器进行类别划分,所以说是两步。
对于聚类问题,只需要直接对数据进行处理,寻找数据之间相同之处来对数据进行划分类别,相对于分类来说这里只有一步。
三、常用对应算法
1.分类算法:
- K近邻(KNN)
- 逻辑回归
- 支持向量机
- 朴素贝叶斯
- 决策树
- 随机森林
2.聚类算法 :
- K均值(K-means)
- FCM(模糊C均值聚类)
- 均值漂移聚类
- DBSCAN
- DPEAK
- Mediods
- Canopy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号